
Cross-Entropy Loss là gì? Vai trò, tính năng và ứng dụng

 04/12/2025
04/12/2025
Cross-Entropy Loss được dùng phổ biến cho các bài toán phân loại trong học váy, vì tối ưu cross-entropy tương đương với làm cho phân phối dự đoán tiền gân nhất tới phân phối nhãn thật.
Cross-Entropy Loss là công cụ tiện ích giúp các mô hình phân loại của Trí tuệ nhân tạo (AI) tự học và sửa lỗi. Phép toán này đóng vai trò quan trọng trong việc đo lường sự khác biệt giữa dự đoán của mô hình và kết quả thực tế, điều chỉnh các tham số để đưa ra dự đoán chính xác và tự tin hơn. Vậy Cross-Entropy Loss là gì, có vai trò và ứng dụng như thế nào? Hãy cùng VNPT AI đi sâu tìm hiểu!
Cross-Entropy Loss là gì?
Cross-Entropy Loss (hay còn gọi là Logarithmic Loss hoặc Log Loss - Hàm mất mát logarit, mất mát Entropy chéo) là một hàm mất mát quan trọng trong học máy (Machine Learning - ML), đặc biệt phổ biến trong các bài toán phân loại (classification).
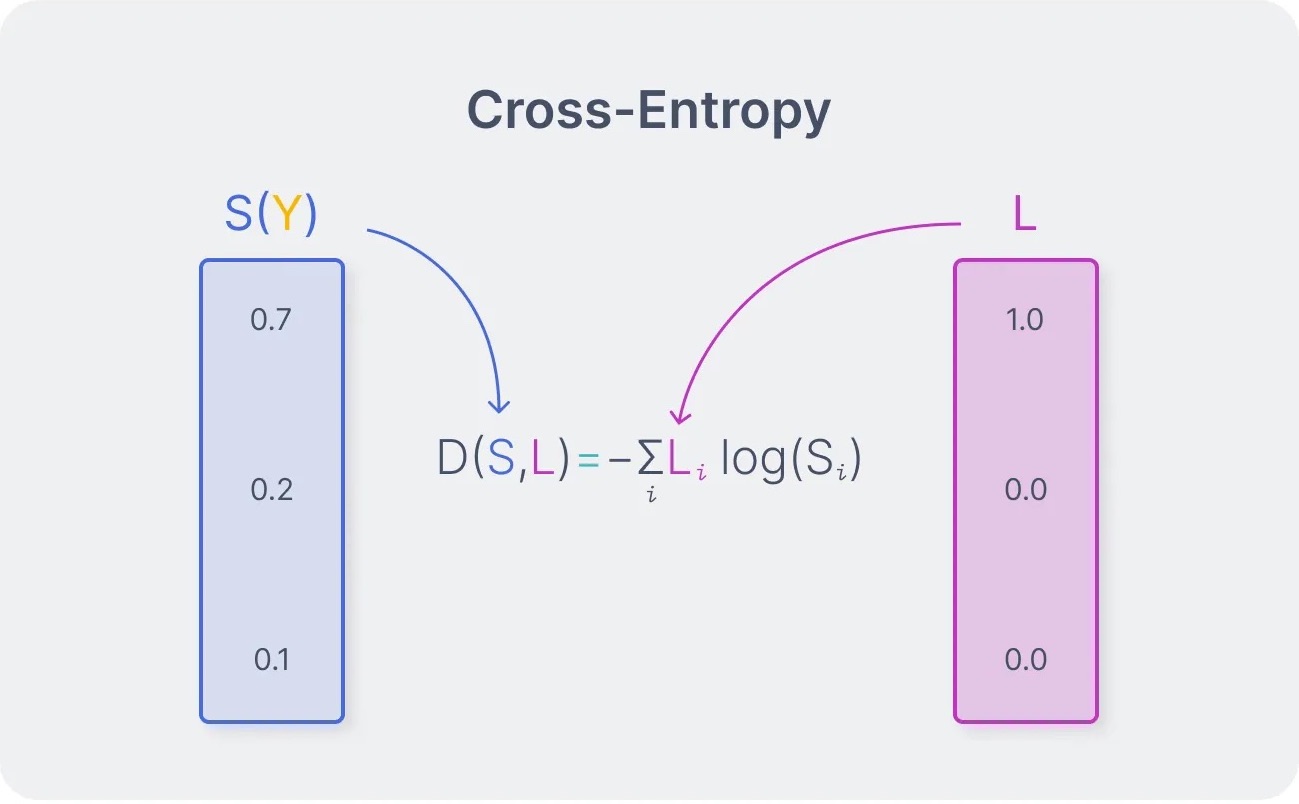
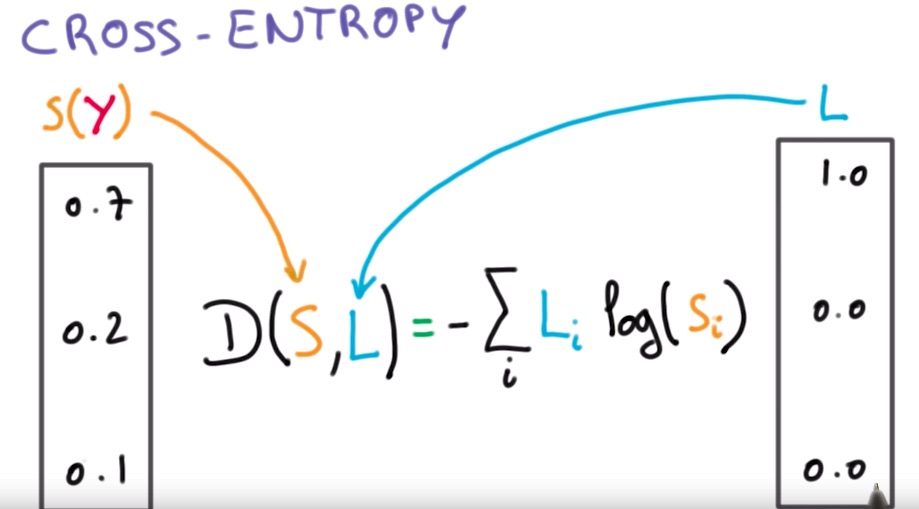
Về cơ bản, Cross-Entropy đo lường sự khoảng cách giữa phân phối xác suất thực tế (nhãn thực) và phân phối xác suất dự đoán của mô hình. Nếu mô hình dự đoán càng gần với giá trị thực, giá trị Cross-Entropy càng nhỏ. Ngược lại, nếu sai số càng lớn thì giá trị mất mát càng cao.
Công thức tổng quát và cách tính của Cross-Entropy Loss như sau:
L(y,t) = - itiln (yi )
Trong đó:
- ti là nhãn thực (ground truth)
- yi là xác suất dự đoán cho lớp i
Vai trò và tính năng của Cross-Entropy Loss
Một số tính năng nổi bật của Cross-Entropy Loss gồm có:
- Diễn giải xác suất rõ ràng: Hàm mất mát Entropy buộc mô hình đưa ra dưới dạng xác suất gần với lớp đúng, giúp kết quả trở nên dễ hiểu và có ý nghĩa hơn.
- Khả năng khả vi (differentiable): Cross-Entropy Loss cho phép tối ưu hóa hiệu quả bằng thuật toán gradient descent (thuật toán dùng để tìm cực tiểu của một hàm số).
- Tiêu chuẩn trong mạng nơ-ron: Hàm Entropy chéo đặc biệt hiệu quả khi kết hợp với các hàm kích hoạt như Softmax (cho các phân loại đa lớp) hoặc Sigmoid (cho phân loại nhị phân).
- Xử phạt mạnh với dự đoán sai: Hàm mất mát Entropy gán mức phạt lớn cho những dự đoán sai nhưng tự tin, từ đó khuyến khích mô hình học cần thân hơn, tránh đưa ra những dự đoán liều lĩnh.
- Hỗ trợ rộng rãi: Cross-Entropy Loss đã được tích hợp sẵn trong hầu hết các thư viện học máy phổ biến như TensorFlow, PyTorch hay Scikit-learn, giúp nâng cao hiệu suất làm việc của các mô hình.
Các loại Cross-Entropy Loss
Trong lĩnh vực học máy và học sâu (Deep Learning), Cross-Entropy Loss được chia thành hai loại chính, tùy thuộc vào số lượng lớp cần phân loại:
Binary Cross-Entropy Loss
Binary Cross-Entropy Loss (BCE) được sử dụng trong bài toán phân loại nhị phân với chỉ hai lớp (ví dụ: có/không, đúng/sai). Hàm mất mát này đo lường sự khác biệt giữa xác suất dự đoán và nhãn thực tế. Công thức được biểu diễn như sau:
L=−N1i=1∑N[yilog(pi)+(1−yi)log(1−pi)]
Trong đó:
- yi là nhãn thực tế (0 hoặc 1)
- pi là xác suất mô hình dự đoán cho lớp dương
Lưu ý: BCE thường kết hợp với hàm Sigmoid ở lớp đầu ra để tối ưu khả năng phân biệt hai lớp
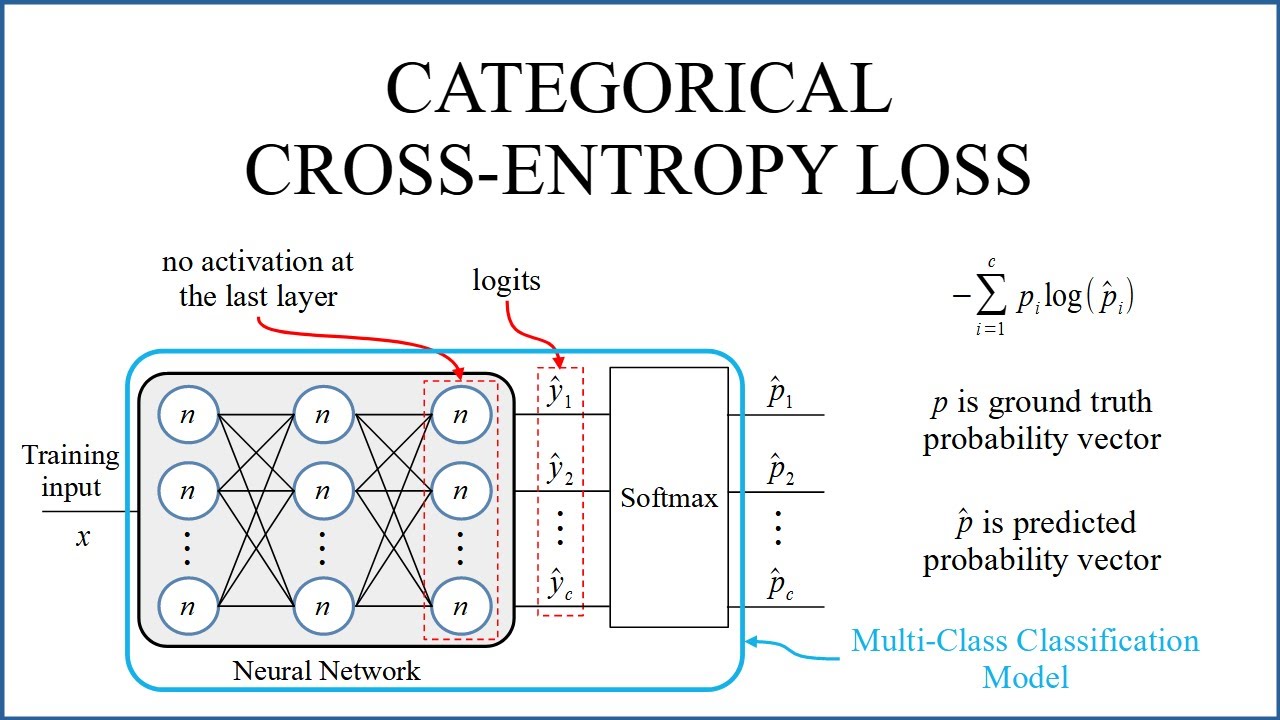
Categorical Cross-Entropy Loss
Categorical Cross-Entropy Loss (CCE) được áp dụng trong bài toán phân loại đa lớp với nhiều nhãn loại trừ lẫn nhau. Hàm mất mát này tính toán sự sai lệch giữa xác suất dự đoán và nhãn thực tế cho từng lớp. Công thức như sau:
L=−N1i=1∑Nj=1∑Cyijlog(pij)
Trong đó:
- C là tổng số lớp
- yij bằng 1 nếu mẫu i thuộc lớp j, ngược lại bằng 0
- pij là xác suất dự đoán cho lớp j
Lưu ý: CCE thường sử dụng hàm Softmax ở lớp đầu ra để tạo phân phối xác suất hợp lệ
Ứng dụng của Cross-Entropy Loss trong AI và Deep Learning
Cross-Entropy Loss được ứng dụng nhiều trong các dự án phát triển Trí tuệ nhân tạo và Học sâu (Deep Learning), ví dụ như:
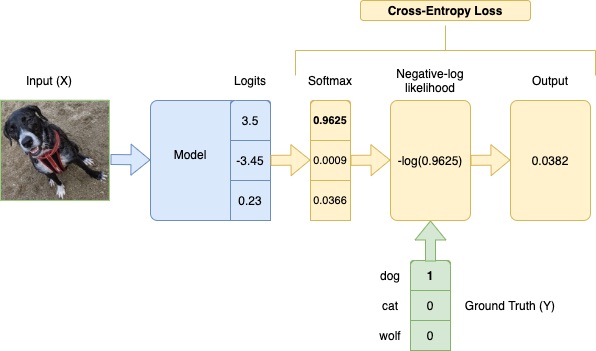
Phân loại đa lớp
Hàm Softmax tạo ra một vector xác suất, sau đó Cross-Entropy Loss sẽ so sánh vector đó với vector one-hot của nhãn thực tế:
- Nếu mô hình dự đoán đúng lớp với xác suất cao, giá trị mất mát nhỏ.
- Nếu mô hình dự đoán sai hoặc không chắc chắn, giá trị mất mát lớn, buộc mô hình phải điều chỉnh trọng số để cải thiện hiệu quả.
Phân loại nhị phân
Trong các bài toán chỉ có hai lớp (ví dụ: email spam/không spam, đúng/sai), Binary Cross-Entropy Loss được sử dụng. Thay vì dùng Softmax, mô hình áp dụng hàm Sigmoid ở lớp đầu ra để ánh xạ xác suất từ 0 đến 1, đảm bảo khả năng phân biệt hai lớp hiệu quả và chuẩn xác.
Các mô hình tạo sinh
Cross-Entropy Loss còn đóng vai trò quan trọng trong các mô hình tạo sinh, chẳng hạn như mô hình ngôn ngữ lớn như GPT-4, Llama 3, Claude 3,..... Nhiệm vụ dự đoán từ tiếp theo trong câu của hàm mất mát Entropy được xem như một bài toán phân loại đa lớp, trong đó mỗi từ trong từ vựng là một lớp. Việc tối thiểu hóa Cross-Entropy Loss giúp mô hình dự đoán từ chính xác hơn, qua đó nâng cao hiệu quả trong các ứng dụng dự đoán văn bản, dịch máy hay sáng tạo nội dung tự động.
Tạm kết
Trên đây là tổng hợp của VNPT AI về các kiến thức liên quan đến Cross-Entropy Loss là gì, vai trò, tính năng và ứng dụng của nền tảng này. Có thể thấy, Cross-Entropy Loss là yếu tố then chốt giúp các mô hình phân loại đưa ra dự đoán chính xác và có ý nghĩa xác suất rõ ràng. Nhờ đặc tính khả vi và khả năng xử phạt mạnh các dự đoán sai, hàm mất mát này đã trở thành tiêu chuẩn trong huấn luyện mạng nơ-ron hiện đại. Việc áp dụng Cross-Entropy Loss không chỉ nâng cao độ chính xác của mô hình, mà còn đặt nền móng cho việc xây dựng các hệ thống AI thông minh, ổn định và đáng tin cậy hơn.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá