
Vision Transformer là gì? Giải mã sức mạnh xử lý hình ảnh của ViT

 16/12/2025
16/12/2025
Vision Transformer (ViT) là một kiến trúc mô hình học sâu áp dụng cơ chế Transformer. ViT vượt trội hơn CNN về hiệu suất khi có dữ liệu lớn, hiệu quả tính toán cao hơn gấp 4 lần và dễ mở rộng cho đa phương thức.
Thị trường Trí tuệ nhân tạo (AI) đang tăng trưởng theo cấp số nhân, dự kiến đạt 1.810 tỷ USD vào năm 2030. Trong cuộc đua công nghệ ấy, Vision Transformer (ViT) nổi lên như một nhân tố chiến lược, thay thế hoàn toàn mạng CNN truyền thống trong nhiều tác vụ thị giác máy tính. Vậy Vision Transformer là gì và điều gì làm nên sức mạnh của công nghệ này? Hãy cùng VNPT AI khám phá chi tiết về kiến trúc và cơ chế hoạt động của ViT trong bài viết dưới đây.
Vision Transformer là gì?
Vision Transformer (ViT) là một mô hình học sâu đột phá, được nhóm nghiên cứu Google Research giới thiệu tại hội nghị ICLR 2021 trong công trình “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. Mô hình này ứng dụng kiến trúc transformer, vốn thành công trong xử lý ngôn ngữ tự nhiên (NLP) để giải quyết các bài toán về thị giác máy tính.
Về bản chất, ViT là phiên bản điều chỉnh của Transformer để xử lý dữ liệu hình ảnh thay vì chuỗi ngôn ngữ. ViT không sử dụng các phép toán chập (Convolutional) truyền thống, mà chia hình ảnh đầu vào thành nhiều "patch" (miếng vá) có kích thước cố định. Sau đó, mô hình coi mỗi patch này như một "token thị giác" - tương tự như cách Transformer xử lý các từ (tokens) trong một câu.
Việc này cho phép ViT tận dụng cơ chế Self-Attention mạnh mẽ để học mối quan hệ phụ thuộc giữa các vùng khác nhau của hình ảnh. Kiến trúc này đã chứng minh khả năng đạt được hiệu suất vượt trội trong nhiều tác vụ nhận dạng hình ảnh phức tạp như: phân loại đối tượng, phân đoạn ảnh (segmentation), truy vấn thị giác (visual-question answering) và trả lời câu hỏi trực quan,..…
>>> Tìm hiểu thêm: Mixture of Experts (MoE) là gì?
Kiến trúc Vision transformer (ViT)
Dưới đây là các thành phần chính yếu cấu tạo nên kiến trúc ViT:
- Layer Normalization: Giúp ổn định quá trình huấn luyện, đồng thời cho phép mô hình thích nghi với sự khác biệt giữa các mẫu dữ liệu đầu vào và duy trì hiệu suất.
- Cơ chế Self-Attention và Multi-Head Attention: Self-Attention là trọng tâm của ViT, cho phép mô hình đánh giá tầm quan trọng của từng patch so với toàn bộ hình ảnh. Multi-Head Attention mở rộng cơ chế này bằng nhiều “đầu” chú ý song song, từ đó học được nhiều mối quan hệ khác nhau giữa các vùng ảnh.
- Feed-Forward Network (MLP): Sau lớp attention, các embedding được xử lý tiếp qua mạng nơ-ron truyền thẳng nhiều lớp, thường kèm theo hàm kích hoạt GELU để tăng khả năng biểu diễn. Trong tác vụ phân loại, đầu ra cuối cùng (MLP head) được đưa qua Softmax để dự đoán nhãn.
- Residual Connections: Các kết nối tắt (skip connections) kết hợp với Layer Normalization giúp duy trì luồng thông tin và gradient, đảm bảo quá trình huấn luyện ổn định ngay cả với mô hình sâu.
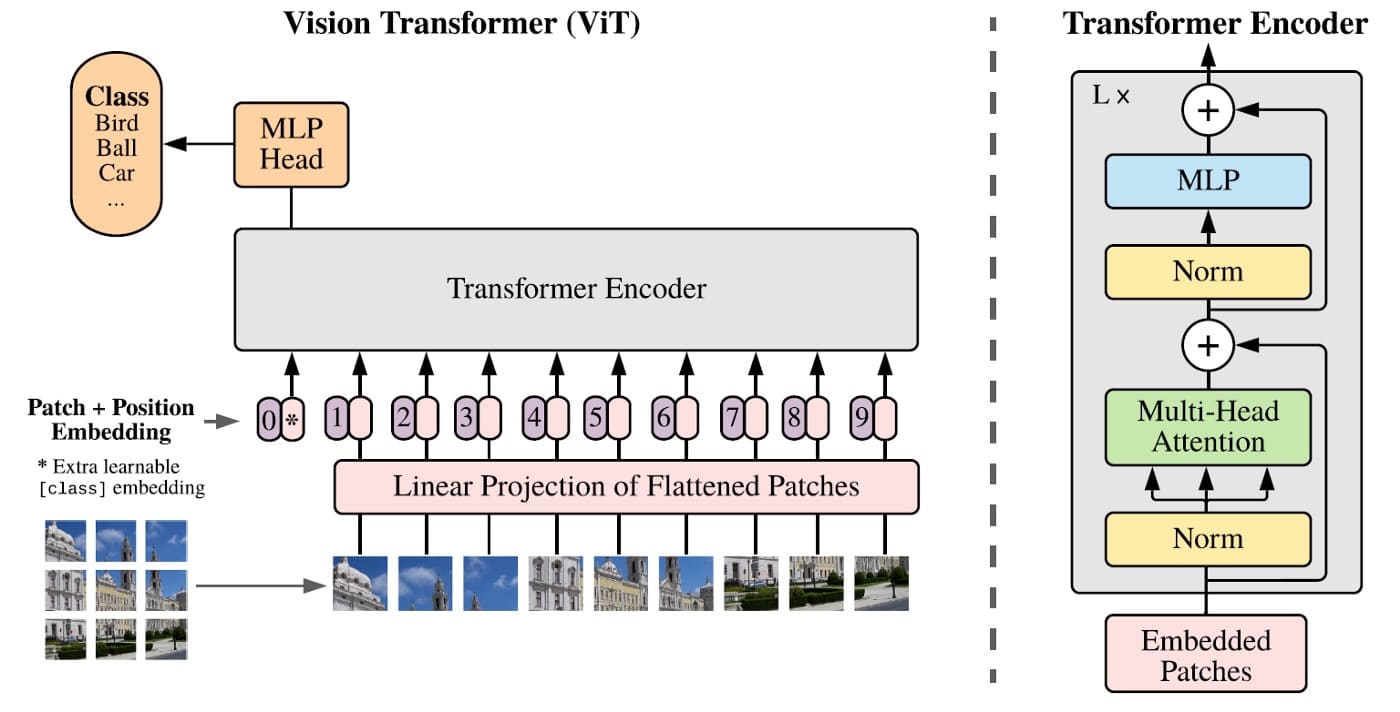
Cơ chế hoạt động của Vision Transformer
Vision Transformer hoạt động theo quy trình các bước như sau:
- Chia ảnh thành patch: Ảnh đầu vào được cắt thành nhiều patch vuông có kích thước cố định (ví dụ 16x16 pixel). Mỗi patch được làm phẳng thành một vector, tạo thành chuỗi tương tự như token trong NLP.
- Tạo patch embedding: Các vector patch được ánh xạ qua lớp tuyến tính để chuyển sang không gian đặc trưng cao hơn. Mỗi embedding được cộng thêm positional encoding nhằm giữ lại thông tin vị trí trong ảnh.
- Transformer Encoder: Chuỗi embedding đi qua nhiều lớp encoder gồm multi-head self-attention và feed-forward network. Cơ chế này cho phép mô hình học cả đặc trưng cục bộ lẫn ngữ cảnh toàn cục.
- Classification token: Một token đặc biệt [CLS] được thêm vào chuỗi embedding. Sau khi xử lý qua encoder, đầu ra của token này được sử dụng làm biểu diễn tổng thể của ảnh cho tác vụ phân loại.
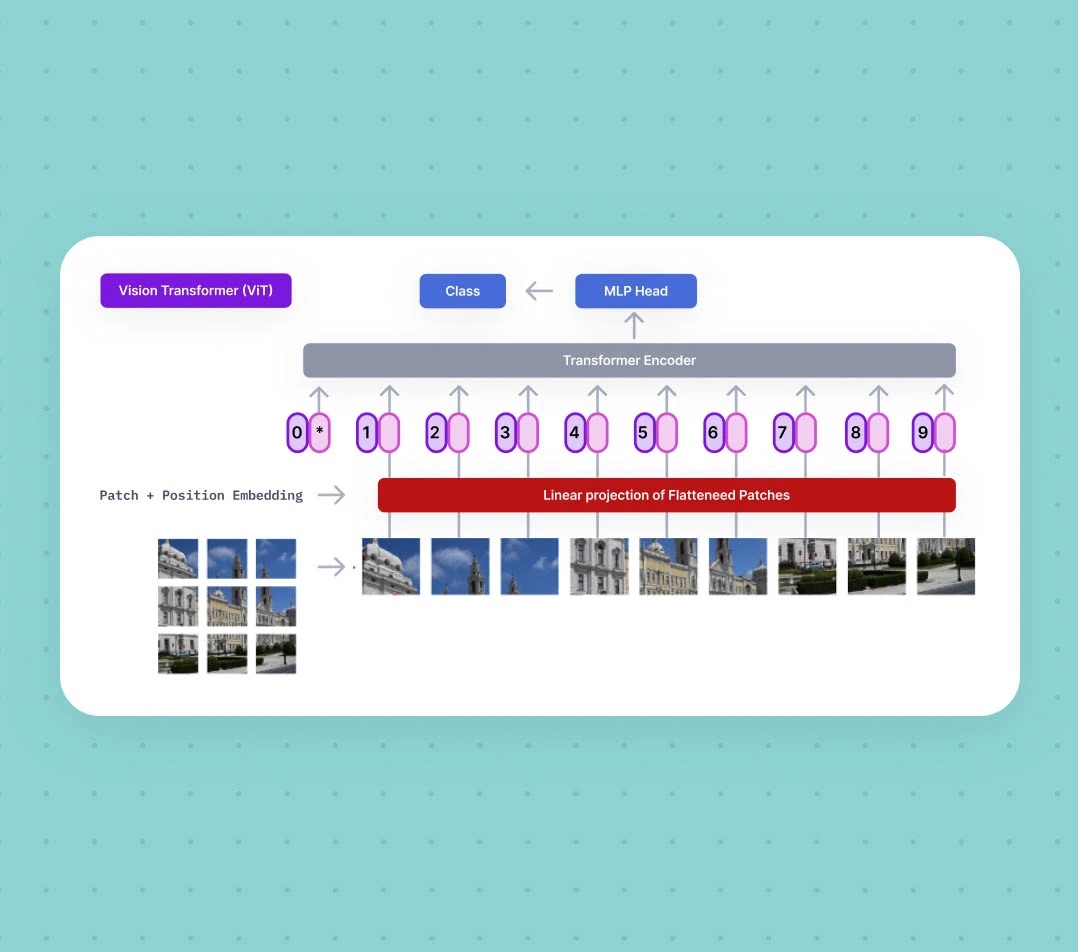
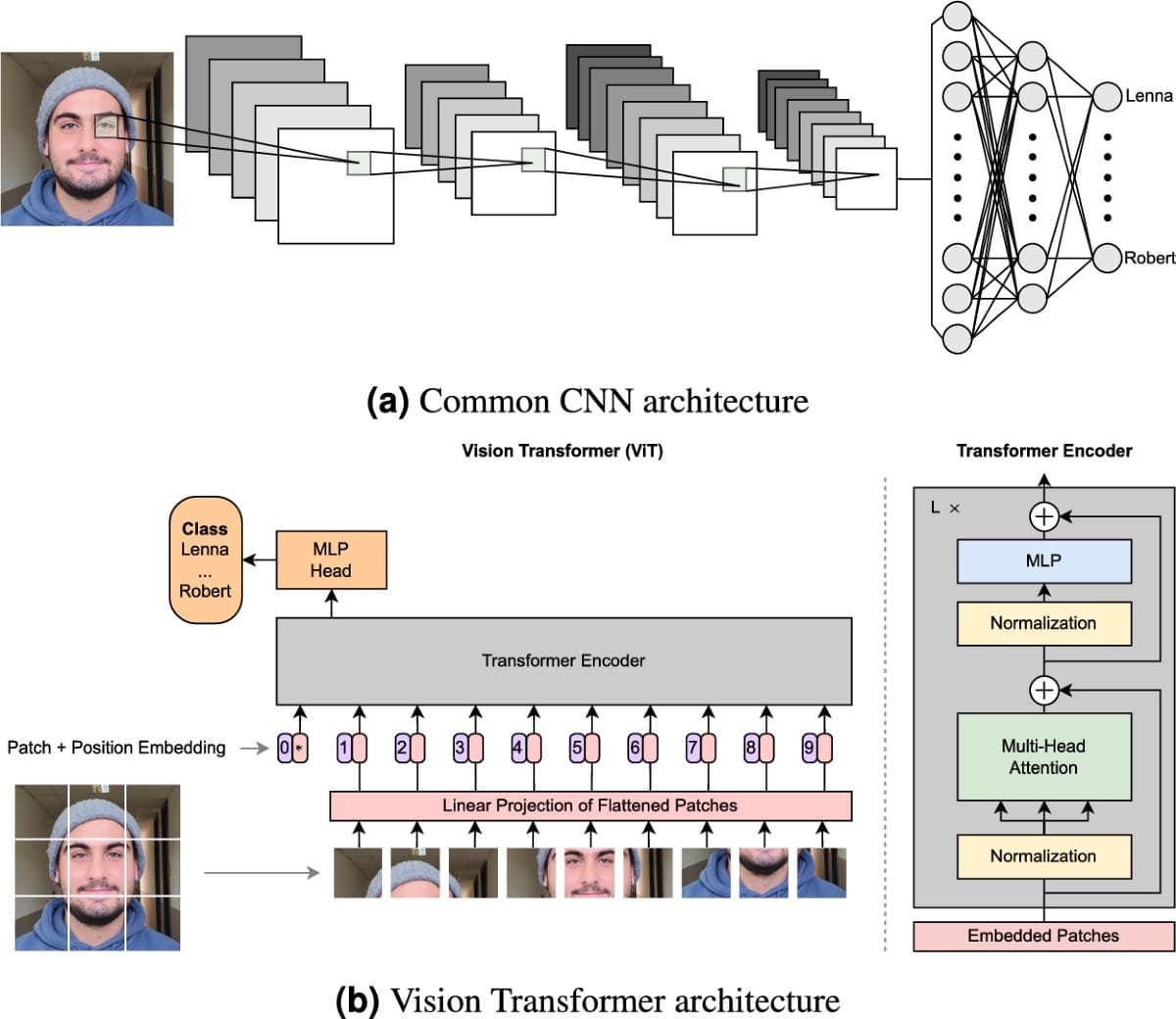
Sự khác nhau giữa Vision transformer và Convolutional Neural Network
Dưới đây là bảng so sánh một số khác biệt chính giữa hai kiến trúc này:
Tiêu chí | Vision Transformer (ViT) | Convolutional Neural Network (CNN) |
| Kiến trúc | Dựa trên transformer encoder, xử lý ảnh dưới dạng chuỗi patch | Sử dụng lớp tích chập để trích xuất đặc trưng theo tầng |
| Khai thác đặc trưng | Học quan hệ toàn cục ngay từ lớp đầu tiên | Bắt đầu từ đặc trưng cục bộ, dần xây dựng ngữ cảnh toàn cục |
| Độ lệch quy nạp (Inductive Bias) | Yếu - Phụ thuộc nhiều vào dữ liệu và kỹ thuật regularization | Mạnh - Nhờ tính cục bộ và bất biến dịch chuyển |
| Yêu cầu dữ liệu | Cần tập dữ liệu lớn hoặc pre-train để đạt hiệu suất cao | Hoạt động tốt với dữ liệu vừa và nhỏ |
| Chi phí tính toán | Cao hơn, đặc biệt với ảnh có độ phân giải lớn | Thấp hơn, phù hợp với ứng dụng thời gian thực và thiết bị hạn chế |
| Khả năng mở rộng | Rất linh hoạt, hiệu quả khi tăng dữ liệu và tài nguyên | Ít linh hoạt hơn khi mở rộng sang tập dữ liệu cực lớn |
| Hiệu suất | Vượt trội trong các bài toán quy mô lớn, yêu cầu hiểu toàn cảnh | Hiệu quả mạnh trong hầu hết các tác vụ cơ bản, đặc biệt khi tài nguyên hạn chế |
| Diễn giải | Khó giải thích do sự phức tạp của attention patterns | Dễ hiểu hơn nhờ trực quan hóa feature maps |
Vision Transformer (ViT) và Convolutional Neural Network (CNN) đều là những kiến trúc nền tảng trong thị giác máy tính, nhưng cách tiếp cận của chúng rất khác biệt. CNN dựa vào các lớp tích chập để trích xuất đặc trưng cục bộ và dần xây dựng thông tin toàn cục, nhờ đó hoạt động hiệu quả ngay cả với tập dữ liệu nhỏ. Trong khi đó, ViT sử dụng cơ chế self-attention để học mối quan hệ toàn cục giữa các patch hình ảnh ngay từ những lớp đầu tiên, cho phép mô hình nắm bắt bối cảnh rộng hơn nhưng lại đòi hỏi lượng dữ liệu lớn và tài nguyên tính toán mạnh.
Ứng dụng nổi bật của Vision Transformer
Vision Transformer ngày càng khẳng định vai trò trong nhiều lĩnh vực nhờ khả năng xử lý toàn cục và linh hoạt. Dưới đây là một số ứng dụng tiêu biểu:
Phân tích hình ảnh y tế
ViT thể hiện hiệu quả vượt trội trong xử lý ảnh MRI, CT hay sinh thiết mô. Cơ chế self-attention giúp mô hình nắm bắt mối quan hệ giữa các vùng xa, hỗ trợ phát hiện khối u và phân đoạn cơ quan chính xác hơn. So với CNN, ViT duy trì tốt thông tin không gian, nhờ đó trở thành công cụ hữu ích trong chẩn đoán y khoa và hệ thống y tế thông minh.
Xe tự hành
Trong lĩnh vực lái xe tự động, ViT giúp phân tích toàn cảnh giao thông, nhận diện vật thể, phân đoạn làn đường và dự đoán tình huống. Nhờ khả năng xử lý quan hệ toàn cục giữa xe, người đi bộ và hạ tầng, ViT góp phần nâng cao độ an toàn, mở rộng tiềm năng ứng dụng trong công nghệ xe tự hành.
Phân loại hình ảnh
Phân loại ảnh là ứng dụng nền tảng của ViT. Khi được huấn luyện trên dữ liệu lớn, mô hình thường vượt trội hơn CNN nhờ khả năng học biểu diễn tổng quát và giàu ngữ cảnh. Các tập dữ liệu như ImageNet-21k cho thấy ViT đạt hiệu suất cao, đánh dấu bước tiến trong lĩnh vực thị giác máy tính.
>>> Đọc thêm: Phân vùng ảnh (Image Segmentation) là gì?
Tạo mô tả hình ảnh
ViT không chỉ nhận diện đối tượng mà còn tạo mô tả ngôn ngữ tự nhiên cho hình ảnh. Cơ chế biểu diễn toàn diện giúp mô hình hiểu ngữ cảnh và sinh câu mô tả chính xác, hỗ trợ các ứng dụng như tìm kiếm hình ảnh, trợ giúp người khiếm thị hay hệ thống AI đa phương thức.

Phát hiện bất thường
Trong các hệ thống giám sát hoặc kiểm tra chất lượng sản phẩm, ViT hỗ trợ phát hiện lỗi nhỏ mà CNN có thể bỏ sót. Mô hình phân tích cấu trúc toàn ảnh và xác định vùng bất thường chính xác nhờ cơ chế attention. Điều này đặc biệt quan trọng trong công nghiệp sản xuất và an ninh, nơi yêu cầu độ chính xác cao.
>>> Xem thêm: Anomaly Detection là gì?
Xử lý 3D Vision
ViT đang thay đổi cách tiếp cận các tác vụ 3D như phân đoạn cảnh, định vị đối tượng hay căn chỉnh hình ảnh với văn bản. Mô hình có thể học đồng thời đặc trưng không gian ba chiều và ngôn ngữ, giúp nâng cao hiệu quả trong thị giác - ngôn ngữ 3D. Điển hình, các nghiên cứu như 3D-VisTA cho thấy ViT đạt kết quả vượt trội trong nhiệm vụ gán nhãn, đặt câu hỏi và mô tả chi tiết cảnh 3D. Điều này mở ra tiềm năng ứng dụng trong robot, thực tế ảo và bản đồ thông minh.
Generative AI
ViT đã góp phần quan trọng vào sự phát triển của Generative AI, đặc biệt là các mô hình sinh ảnh và video. Thay vì chỉ nhận diện, ViT có khả năng mô hình hóa quan hệ dài hạn, từ đó tạo ra dữ liệu mới với độ chân thực cao. Các kiến trúc như MAGVIT và Latte tận dụng self-attention để sinh video, ảnh động hoặc mô phỏng không gian - thời gian mượt mà.

Thách thức và hạn chế của Vision Transformer
Mặc dù được đánh giá cao về tiềm năng phát triển, ViT vẫn còn tồn tại một số hạn chế nhất định như:
- Yêu cầu dữ liệu lớn: ViT cần tập dữ liệu quy mô rất lớn để huấn luyện hiệu quả, dễ bị quá khớp khi dữ liệu hạn chế.
- Tài nguyên tính toán: Cơ chế self-attention có độ phức tạp bậc hai khiến ViT tiêu tốn nhiều GPU và thời gian huấn luyện.
- Độ ổn định huấn luyện: ViT đòi hỏi điều chỉnh siêu tham số kỹ lưỡng, batch size lớn và quá trình huấn luyện dài để đạt hội tụ.
- Khó diễn giải: Quy trình ra quyết định dựa trên attention phức tạp, khó minh bạch hơn so với bản đồ đặc trưng của CNN.
- Độ nhạy biến đổi không gian: ViT kém bền vững với biến đổi như xoay, lật nếu không được huấn luyện cho các trường hợp này.
- Hạn chế ở chi tiết cục bộ: Dù giỏi mô hình hóa ngữ cảnh toàn cục, ViT có thể bỏ qua kết cấu tinh vi quan trọng trong chẩn đoán hoặc phân tích chi tiết.

Tạm kết
Hy vọng bài viết đã cung cấp cái nhìn toàn diện về Vision Transformer (ViT). Tóm lại, ViT không chỉ là một kiến trúc thay thế, mà là sự chuyển đổi mô hình, chứng minh cơ chế Self-Attention có thể vượt trội so với CNN trong xử lý hình ảnh. Với khả năng nắm bắt ngữ cảnh toàn cục mạnh mẽ, ViT đang mở ra những ứng dụng đột phá trong AI, trở thành tiêu chuẩn mới cho Computer Vision.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá