
Lỗi Underfitting: Dấu hiệu nhận biết và cách khắc phục hiệu quả

 16/12/2025
16/12/2025
Mô hình underfitting thường xảy ra do độ phức tạp thấp, dữ liệu huấn luyện không đủ hoặc chưa được làm sạch, regularization quá mạnh, hoặc thiếu đặc trưng quan trọng. Điều này khiến mô hình không tổng quát hóa tốt, dự đoán dựa trên dữ liệu thực té kém chính xác.
Trong Machine Learning (học máy), Underfitting xảy ra khi mô hình quá đơn giản, không đủ năng lực học các quy luật phức tạp trong dữ liệu, dẫn đến hiệu suất thấp. Hiện tượng này thường bị bỏ qua do ít phổ biến hơn Overfitting, nhưng nó là rào cản lớn ngăn mô hình hoạt động hiệu quả. Bài viết này sẽ VNPT AI sẽ giúp bạn cách nhận biết và cung cấp các phương pháp tối ưu để khắc phục triệt để tình trạng Underfitting.
Underfitting là gì?
Underfitting (thiếu khớp/chưa khớp) là một hiện tượng thường thấy trong học máy, xảy ra khi mô hình quá đơn giản, không đủ khả năng học được các quy luật tiềm ẩn trong dữ liệu. Khi đó, mô hình vừa cho kết quả kém trên tập huấn luyện vừa hoạt động không tốt trên dữ liệu kiểm thử.
Đặc trưng của Underfitting là độ chệch cao (high bias) và độ biến thiên thấp (low variance). Nghĩa là, mô hình đưa ra những giả định quá mạnh mẽ, ví dụ chỉ xem mối quan hệ dữ liệu là tuyến tính trong khi thực tế phức tạp hơn.
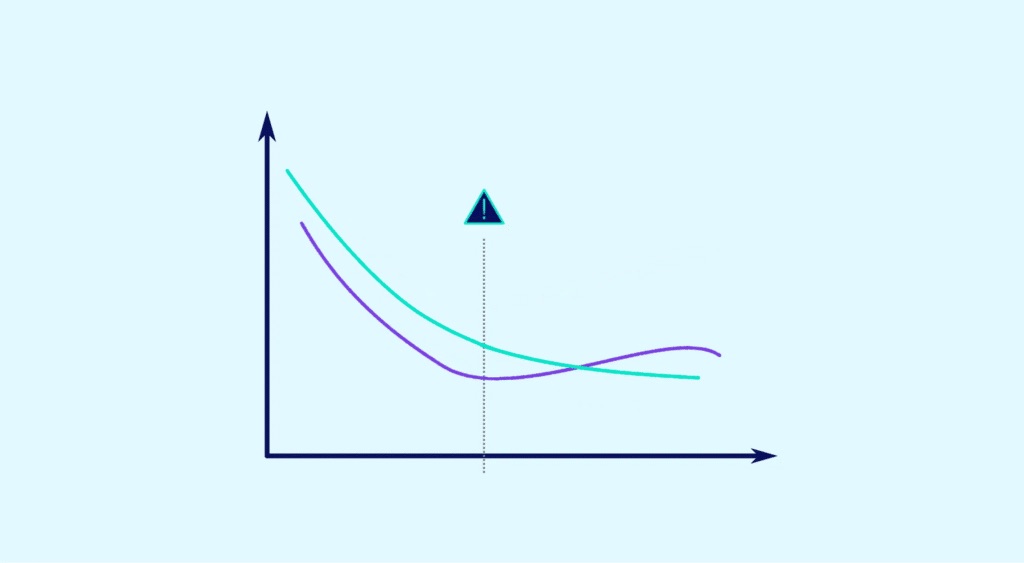
Nguyên nhân gây ra hiện tượng Underfitting
Một số nguyên nhân gây ra hiện tượng Underfitting phổ biến gồm có:
- Mô hình quá đơn giản: Sử dụng thuật toán tuyến tính cho dữ liệu phi tuyến tính làm mô hình không thể học được sự phức tạp của dữ liệu.
- Huấn luyện chưa đầy đủ: Số vòng lặp (epoch) quá ít hoặc dừng sớm khiến mô hình chưa kịp nắm bắt các quy luật tiềm ẩn.
- Đặc trưng kém chất lượng: Thiếu các biến quan trọng, chứa nhiều nhiễu, hoặc chưa được chuẩn hóa và biến đổi phù hợp.
- Tập dữ liệu hạn chế: Kích thước nhỏ hoặc chất lượng thấp khiến mô hình khó học chính xác các mối quan hệ.
- Regularization quá mạnh: Việc áp dụng L1, L2 hoặc dropout với mức cao có thể ràng buộc mô hình quá mức, từ đó làm mất khả năng biểu diễn.

Dấu hiệu nhận biết Underfitting
Underfitting có thể được phát hiện thông qua việc phân tích hiệu suất của mô hình trên dữ liệu huấn luyện và kiểm thử. Một số dấu hiệu thường gặp giúp nhận biết hiện tượng này, gồm:
- Sai số huấn luyện cao: Mô hình không học được quy luật từ dữ liệu, dẫn đến loss hoặc error vẫn cao sau nhiều vòng lặp.
- Sai số huấn luyện và kiểm thử tương đồng: Khi cả hai đều cao và không có sự cải thiện rõ rệt, mô hình đang hoạt động kém trên toàn bộ dữ liệu.
- Đường cong học phẳng: Trên biểu đồ learning curve, loss của cả training và validation đều duy trì ở mức cao, không giảm đáng kể theo thời gian.
- Phân tích dư lượng có quy luật: Residuals không phân bố ngẫu nhiên quanh 0 mà xuất hiện mô hình rõ ràng, cho thấy mô hình bỏ sót xu hướng chính.
- Độ chệch (bias) cao: Mô hình đưa ra giả định quá cứng nhắc, dẫn đến lỗi hệ thống ngay cả trên tập huấn luyện.
Cách giảm thiểu tình trạng Underfitting
Để khắc phục Underfitting, cần áp dụng các kỹ thuật giúp mô hình học tốt hơn các quy luật trong dữ liệu. Một số giải pháp phổ biến gồm:
- Tăng độ phức tạp của mô hình: Chuyển từ mô hình tuyến tính sang các thuật toán mạnh hơn như cây quyết định, Random Forest, Gradient Boosting (XGBoost, LightGBM) hoặc mạng nơ-ron sâu.
- Cải thiện đặc trưng đầu vào: Thực hiện trích chọn đặc trưng (feature engineering), bổ sung đặc trưng đa thức (polynomial features), chọn lọc đặc trưng quan trọng hoặc chuẩn hóa dữ liệu để mô hình học tốt hơn.
- Kéo dài thời gian huấn luyện: Tăng số epochs hoặc điều chỉnh tốc độ học để đảm bảo mô hình có đủ thời gian học, đồng thời theo dõi chỉ số validation để tránh Overfitting.
- Giảm mức độ regularization: Điều chỉnh L1, L2 hoặc dropout hợp lý, tránh đặt ràng buộc quá mạnh khiến mô hình mất khả năng học các quan hệ phức tạp.
- Xử lý dữ liệu và nhiễu: Loại bỏ dữ liệu không liên quan, giảm nhiễu hoặc bổ sung thêm dữ liệu chất lượng để mô hình học được xu hướng chính xác hơn.
- Tối ưu siêu tham số: Điều chỉnh các tham số như độ sâu cây, số lượng nơ-ron hoặc tham số C trong SVM để tăng tính linh hoạt của mô hình.
Loại bỏ các dữ liệu nhiễu không cần thiết để tránh hiện tượng Underfitting
So sánh Underfitting và Overfitting
Underfitting và Overfitting là hai vấn đề đối lập trong lĩnh vực học máy, liên quan trực tiếp đến khả năng mô hình khái quát hóa dữ liệu. Nếu Underfitting xảy ra khi mô hình quá đơn giản, thì Overfitting xuất hiện khi mô hình quá phức tạp và học thuộc cả nhiễu trong tập dữ liệu.
Dưới đây là bảng so sánh tổng quan của hai hiện tượng này:
Tiêu chí | Underfitting | Overfitting |
Mức độ phức tạp | Quá đơn giản | Quá phức tạp |
Sai số huấn luyện | Cao | Thấp |
Sai số kiểm thử | Cao | Cao |
Hiệu suất dự đoán | Không chính xác, kém khái quát hóa | Chính xác trên tập huấn luyện, kém tổng quát |
Nguyên nhân chính | Ít tham số, huấn luyện chưa đủ lâu | Quá nhiều tham số, huấn luyện quá lâu hoặc thêm nhiều đặc trưng không cần thiết |
Đặc định chính của Underfitting và Overfitting như sau:
Underfitting:
- Mô hình có độ phức tạp thấp, không nắm bắt được quy luật tiềm ẩn.
- Sai số huấn luyện và kiểm thử đều cao.
- Biểu hiện: dự đoán thiếu chính xác, hiệu suất thấp trên cả dữ liệu huấn luyện và mới.
Overfitting:
- Mô hình quá phức tạp, ghi nhớ chi tiết và nhiễu của dữ liệu huấn luyện.
- Sai số huấn luyện rất thấp, nhưng sai số kiểm thử lại cao.
- Biểu hiện: dự đoán tốt trên dữ liệu huấn luyện nhưng kém hiệu quả với dữ liệu chưa từng thấy.
Một số ví dụ về Underfitting
Dưới đây là một số ví dụ tiêu biểu minh họa cho hiện tượng Underfitting:
Dự đoán giá nhà
Khi xây dựng mô hình dự đoán giá nhà, nếu chỉ sử dụng quá ít đặc trưng (features) như diện tích và số phòng, mô hình sẽ không tiếp cận được các thông tin quan trọng khác. Ví dụ, mô hình có thể dự đoán một căn hộ nhỏ là giá rẻ mà không biết rằng căn hộ đó nằm ở khu vực đắt đỏ bậc nhất (Hoàn Kiếm, Tây Hồ,...).

Nhận dạng giọng nói
Trong các ứng dụng nhận dạng giọng nói, mô hình chuyển đổi sóng âm thành dữ liệu. Nếu nhà phát triển chỉ cung cấp các đặc trưng được đơn giản hóa quá mức như tần số và âm lượng, mô hình sẽ bị thiếu hụt dữ liệu ngữ cảnh (ví dụ như: âm sắc, ngữ điệu, giọng địa phương). Kết quả, mô hình sẽ bị gặp khó khăn khi trong quá trình nhận lệnh cơ bản.
Phân loại hình ảnh
Khi huấn luyện mô hình phân loại ảnh với mạng nơ-ron nông hoặc cấu trúc đơn giản, mô hình không thể học được đặc trưng phức tạp như hình dạng hay chi tiết vật thể. Ví dụ, dùng mạng nơ-ron truyền thẳng (mạng hai lớp) để nhận diện quả bóng sẽ làm mất thông tin không gian, khiến mô hình nhầm lẫn giữa các vật thể có hình tròn tương tự.
Dự báo thời tiết
Một mô hình chỉ dựa trên nhiệt độ trung bình và độ ẩm để dự đoán lượng mưa sẽ không đủ để phản ánh các yếu tố khí tượng phức tạp như hướng gió, áp suất hay chu kỳ mùa. Do đó, kết quả dự báo thường kém chính xác và thiếu độ ổn định.
Tạm kết:
Hy vọng bài viết đã giúp bạn đọc nhận diện chính xác và hiểu rõ hơn về Underfitting - lỗi mô hình thường thấy trong lĩnh vực học máy. Tóm lại, Underfitting xảy ra khi mô hình quá đơn giản hoặc thiếu dữ liệu đặc trưng cần thiết. Việc khắc phục thành công đòi hỏi phải tăng cường độ phức tạp của mô hình, bổ sung đặc trưng dữ liệu, hoặc giảm thiểu Regularization hợp lý. Nắm vững những chiến lược này là chìa khóa để xây dựng các mô hình học máy đạt hiệu suất tối ưu trong thực tế.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá