
Overfitting là gì? Làm thế nào để phát hiện và khắc phục hiện tượng overfitting?

 10/09/2025
10/09/2025
Overfitting xảy ra khi mô hình quá phức tạp, quá khớp với dữ liệu huấn luyện, học luôn cả những nhiễu và biến thể ngẫu nhiên trong dữ liệu, dẫn đến mất khả năng tổng quát hóa dữ liệu.
Theo báo cáo của McKinsey Global Institute, AI có thể đóng góp thêm khoảng 13 nghìn tỷ USD vào GDP toàn cầu đến năm 2030, tương đương mức tăng 1,2 %/năm. Trước xu hướng này, nhu cầu xây dựng các mô hình máy học vừa chính xác vừa hiệu quả trở thành ưu tiên hàng đầu. Tuy nhiên, một thách thức lớn luôn tồn tại là hiện tượng overfitting. Vậy overfitting là gì, ảnh hưởng ra sao, và làm thế nào để khắc phục? Hãy cùng VNPT AI tìm hiểu trong bài viết dưới đây.
Overfitting là gì?
Overfitting (Quá khớp) là hiện tượng xảy ra khi một mô hình học máy học quá kỹ dữ liệu huấn luyện đến mức thuộc lòng cả những chi tiết nhỏ, kể cả nhiễu trong dữ liệu. Kết quả là, mô hình hoạt động rất tốt trên dữ liệu huấn luyện, nhưng lại dự đoán kém khi gặp dữ liệu mới chưa từng thấy.
Ví dụ thực tế:
Hãy tưởng tượng bạn luyện thi bằng cách học thuộc từng câu hỏi trong đề thi cũ. Khi thi thật, chỉ cần đề thay đổi một chút, bạn sẽ lúng túng - đó chính là “overfitting” trong học máy.
Overfitting và Underfitting khác nhau như thế nào?

Trong quá trình xây dựng mô hình học máy, việc cân bằng giữa học quá nhiều (overfitting) và học chưa đủ (underfitting) là một thách thức lớn. Cả hai hiện tượng đều dẫn đến kết quả dự đoán kém, nhưng theo hai cách rất khác nhau.
Overfitting | Underfitting | |
| Định nghĩa | Mô hình học quá kỹ dữ liệu huấn luyện, bao gồm cả nhiễu và chi tiết không quan trọng. | Mô hình quá đơn giản hoặc chưa học đủ để nắm bắt được xu hướng chính trong dữ liệu. |
| Hiệu suất trên dữ liệu huấn luyện | Rất cao | Thấp |
| Nguyên nhân | - Mô hình quá phức tạp - Huấn luyện quá lâu - Dữ liệu chứa nhiều nhiễu | - Mô hình quá đơn giản - Huấn luyện chưa đủ - Dữ liệu đầu vào thiếu thông tin cần thiết |
| Đặc điểm kỹ thuật | - Phương sai (variance) cao - Độ chệch (bias) thấp | - Phương sai thấp - Độ chệch cao |
| Hậu quả | Mô hình bị "lệch" theo dữ liệu cũ, không áp dụng được cho dữ liệu mới | Mô hình không đủ năng lực để học, dẫn đến dự đoán sai ngay cả trên dữ liệu cũ |
>>> Bạn có thể quan tâm: Fine-tuning là gì?
Nguyên nhân gây ra Overfitting
Overfitting xảy ra khi mô hình học máy không thể khái quát hóa tốt cho dữ liệu mới, mà lại học quá chi tiết, thậm chí học cả nhiễu trong tập dữ liệu huấn luyện. Một số nguyên nhân phổ biến dẫn đến overfitting bao gồm:
- Tập dữ liệu huấn luyện quá nhỏ: Khi số lượng mẫu trong tập huấn luyện không đủ lớn, mô hình không có đủ dữ liệu để học các xu hướng tổng quát. Thay vào đó, nó dễ học thuộc lòng các đặc điểm cụ thể của dữ liệu huấn luyện, dẫn đến overfitting.
- Dữ liệu huấn luyện chứa quá nhiều thông tin nhiễu: Nhiễu ở đây có thể hiểu là những thông tin không đúng, không nhất quán hoặc không liên quan đến bản chất của bài toán (ví dụ như lỗi nhập liệu, giá trị bất thường...).
- Huấn luyện mô hình quá lâu trên một tập dữ liệu cố định: Việc để mô hình học trong thời gian quá dài trên cùng một tập dữ liệu khiến mô hình ngày càng học sâu vào chi tiết của dữ liệu đó, thay vì học xu hướng tổng quát.
- Mô hình quá phức tạp so với bài toán: Khi sử dụng một mô hình có cấu trúc hoặc số lượng tham số quá lớn để giải quyết một bài toán đơn giản, mô hình có thể học quá mức chi tiết của dữ liệu huấn luyện, kể cả những thay đổi nhỏ hoặc ngẫu nhiên không mang ý nghĩa thực tế.
Dấu hiệu nhận biết mô hình bị Overfitting
Dưới đây là một số dấu hiệu giúp người dùng nhận biết hiện tượng Overfitting:
1. Hiệu suất chênh lệch lớn giữa dữ liệu huấn luyện và dữ liệu kiểm tra
Nếu mô hình đạt độ chính xác cao trên tập huấn luyện nhưng lại cho kết quả sai lệch hoặc có tỷ lệ lỗi cao trên tập kiểm tra, đây là dấu hiệu rõ ràng của overfitting.
Ví dụ: Accuracy train = 98%, nhưng accuracy test chỉ = 72%.
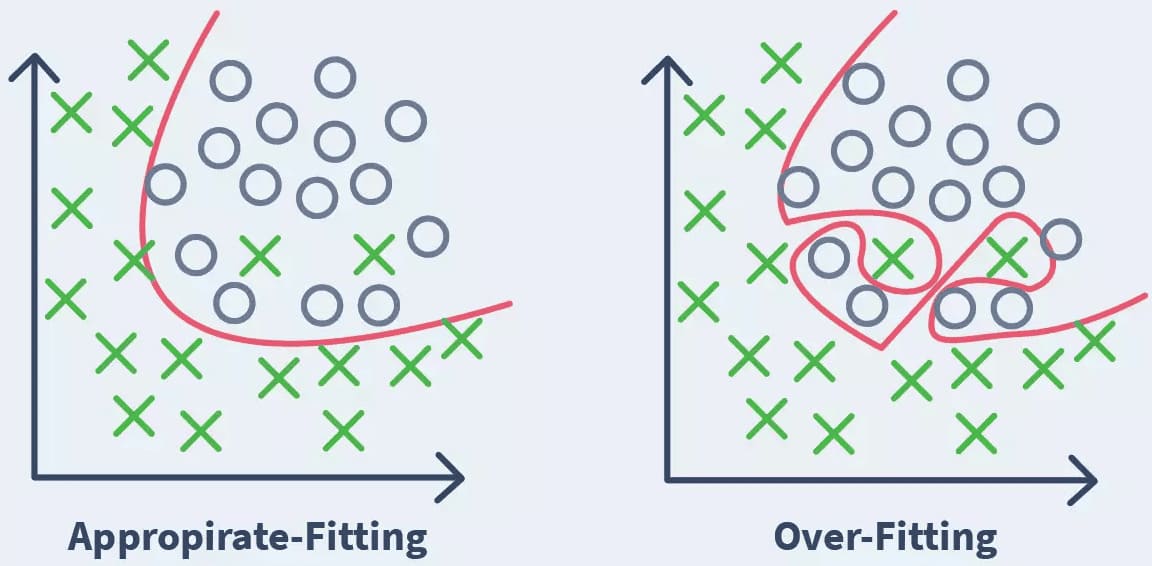
2. Kết quả kiểm tra bằng kỹ thuật K-fold Cross-validation không ổn định
K-fold Cross-Validation là một phương pháp hiệu quả để phát hiện overfitting. Tập dữ liệu huấn luyện được chia đều thành K phần. Trong mỗi vòng lặp, mô hình được huấn luyện trên K-1 phần và kiểm tra trên phần còn lại.
Sau K vòng lặp, tính điểm trung bình hiệu suất của mô hình trên các lớp để đánh giá tổng thể. Nếu điểm số giữa các lớp dao động mạnh hoặc kết quả kiểm tra thấp hơn đáng kể so với kết quả huấn luyện, đó là dấu hiệu cho thấy mô hình bị overfit.
3. Trực quan hóa mô hình
Với các mô hình như cây quyết định hoặc mạng nơ-ron, người dùng có thể trực quan hóa ranh giới phân loại hoặc biểu diễn đã học. Nếu mô hình tạo ra ranh giới quá phức tạp, uốn lượn sát theo dữ liệu huấn luyện, đó là dấu hiệu overfitting - mô hình đang học thuộc thay vì tổng quát hóa.
4. Biểu đồ đường cong học tập (Learning curve)
Người dùng có thể vẽ biểu đồ so sánh sai số của mô hình trên tập huấn luyện và tập kiểm tra khi tăng dần lượng dữ liệu. Nếu mô hình càng học thì sai số trên tập huấn luyện càng giảm, nhưng sai số trên tập kiểm tra lại vẫn cao hoặc tăng lên thì đó là dấu hiệu rõ ràng cho thấy mô hình đang quá khớp dữ liệu huấn luyện.
Ảnh hưởng của Overfitting đến mô hình
Overfitting ảnh hưởng tiêu cực đến hiệu suất và khả năng áp dụng thực tế của mô hình học máy, cụ thể:
- Khả năng dự đoán kém với dữ liệu mới: Mô hình chỉ “nhớ” những gì đã học trong dữ liệu huấn luyện mà không thực sự hiểu bản chất của bài toán. Vì vậy, khi gặp dữ liệu mới, mô hình dễ đoán sai.
- Hiệu suất thấp trên tập kiểm tra: Sai số (error) trên tập kiểm tra tăng cao do mô hình không thể xử lý dữ liệu khác với những gì nó đã học.
- Lãng phí tài nguyên tính toán: Việc huấn luyện mô hình phức tạp quá mức không chỉ tốn thời gian mà còn tiêu tốn tài nguyên tính toán trong khi không mang lại hiệu quả tương xứng.
- Khó khăn trong bảo trì và mở rộng: Mô hình quá phức tạp, khó hiểu và không linh hoạt sẽ gây khó khăn cho việc bảo trì hoặc điều chỉnh trong tương lai.
Cách hạn chế và khắc phục tình trạng Overfitting
Để mô hình học máy không bị rơi vào tình trạng học quá mức, người dùng có thể áp dụng các phương pháp sau để khắc phục tình trạng overfitting:
- Dừng huấn luyện đúng lúc: Theo dõi hiệu suất trên tập validation để dừng huấn luyện trước khi mô hình bắt đầu ghi nhớ dữ liệu thay vì học.
- Chọn lọc đặc trưng quan trọng: Loại bỏ các biến không quan trọng để tránh làm mô hình "bị nhiễu" và phức tạp không cần thiết
- Kết hợp nhiều mô hình nhỏ: Thay vì chỉ dùng một mô hình, có thể dùng nhiều mô hình đơn giản và tổng hợp kết quả để có độ chính xác cao hơn. Các mô hình nhỏ có thể sử dụng như bagging (Chạy các mô hình cùng lúc rồi lấy kết quả trung bình) và boosting (Mỗi mô hình sau sẽ học từ sai sót của mô hình trước để cải thiện kết quả).
- Tăng số lượng và sự đa dạng của dữ liệu: Càng có nhiều dữ liệu phong phú, mô hình càng dễ học được xu hướng tổng quát thay vì nhớ từng chi tiết nhỏ trong dữ liệu cũ.
>>> Tìm hiểu thêm: Batch Normalization là gì?
Ví dụ về Overfitting
Dưới đây là một số ví dụ về overfitting trong thực tế:
Ví dụ về Overfitting trong học máy
Giả sử bạn xây dựng một mô hình nhận diện giọng nói để chuyển lời nói thành văn bản. Bộ dữ liệu huấn luyện chủ yếu là giọng nói của một nhóm người nói chuẩn, không có nhiều biến thể về giọng địa phương, tốc độ nói hay tiếng ồn nền.
Trong quá trình kiểm thử, mô hình hoạt động rất tốt khi nghe giọng từ nhóm người này. Tuy nhiên, khi gặp giọng nói của người khác với âm điệu, ngữ điệu, hoặc tiếng ồn nền khác, mô hình thường xuyên nhận diện sai hoặc không hiểu chính xác. Lý do là mô hình đã học quá chi tiết đặc điểm của giọng nói nhóm huấn luyện, không thể tổng quát hoá cho các kiểu giọng đa dạng khác nhau. Đây chính là hiện tượng overfitting do dữ liệu huấn luyện chưa đủ đa dạng.

Ví dụ về Overfitting trong deep learning
Giả sử một mô hình trên xe tự lái được huấn luyện chủ yếu với hình ảnh chụp trong điều kiện trời nắng, ánh sáng đầy đủ. Mô hình này sẽ hoạt động rất tốt khi xe chạy dưới trời nắng, vì nó đã học được các đặc điểm rõ ràng của người đi bộ, xe đạp hay các phương tiện khác trong điều kiện ánh sáng tốt.
Tuy nhiên, khi xe gặp phải mưa lớn, sương mù hoặc trời tối, mô hình thường không nhận diện chính xác các vật thể xung quanh. Nguyên nhân là do mô hình đã "quen" với dữ liệu có điều kiện ánh sáng lý tưởng và không học được cách xử lý các tình huống phức tạp hơn.
Tạm kết
Hy vọng rằng bài viết của VNPT AI giúp bạn đọc hiểu overfitting là gì và ảnh hưởng của hiện tượng này. Việc nhận diện, ngăn ngừa và khắc phục overfitting đòi hỏi sự cân bằng hợp lý giữa độ phức tạp của mô hình và chất lượng, sự đa dạng của dữ liệu huấn luyện. Do đó, hiểu rõ bản chất và áp dụng các kỹ thuật quản lý overfitting không chỉ nâng cao hiệu suất dự đoán mà còn đảm bảo sự bền vững và khả năng mở rộng của các giải pháp trí tuệ nhân tạo trong nhiều lĩnh vực ứng dụng khác nhau.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá