
Nhận diện giọng nói là gì? 5 phần mềm Speech Recognition nổi bật nhất hiện nay

 10/02/2025
10/02/2025
Nhận diện giọng nói là công nghệ sử dụng trí tuệ nhân tạo (AI) để chuyển đổi âm thanh giọng nói thành văn bản. Công nghệ này giúp máy tính và thiết bị thông minh hiểu và xử lý ngôn ngữ nói của con người, từ đó thực hiện các lệnh hoặc phản hồi phù hợp.
Theo kỳ vọng của các chuyên gia trên thế giới, thị trường nhận diện giọng nói toàn cầu dự kiến sẽ đạt giá trị hơn 27 tỷ USD vào năm 2026, với tốc độ tăng trưởng hàng năm lên đến 17%. Công nghệ này đã chứng minh được hiệu quả vượt trội trong việc tối ưu hóa quy trình làm việc, nâng cao trải nghiệm khách hàng, và giúp doanh nghiệp tiết kiệm một khoản chi phí đáng kể. Trong bài viết này, hãy cùng VNPT AI tìm hiểu về công nghệ nhận diện giọng nói là gì? và điểm qua 5 phần mềm nhận diện giọng nói được ưa chuộng nhất hiện nay.
Nhận diện giọng nói là gì?
Nhận diện giọng nói (hay còn gọi là Speech Recognition) là một công nghệ sử dụng trí tuệ nhân tạo (AI) để chuyển đổi giọng nói thành văn bản. Sự xuất hiện của Speech Recognition cho phép máy tính hoặc các thiết bị thông minh hiểu và xử lý ngôn ngữ nói của con người, từ đó thực hiện các lệnh hoặc phản hồi phù hợp.

Trong những năm gần đây, ứng dụng nhận diện giọng nói đã được sử dụng sâu rộng trong các lĩnh vực như trợ lý ảo, điển hình như các trợ lý Google Assistant, Siri và Alexa, các nền tảng dịch thuật tự động, hệ thống chăm sóc khách hàng, và thậm chí trong các thiết bị nhà thông minh đang lên ngôi trong thời gian qua. Công nghệ này không chỉ mang lại sự tiện lợi và cá nhân hóa cao hơn cho người dùng khi tương tác với các thiết bị hoặc ứng dụng mà còn tạo điều kiện để nâng cao năng suất lao động của con người.
Nhận dạng giọng nói hoạt động như thế nào?
Công nghệ nhận diện giọng nói hoạt động dựa trên nguyên lý cơ bản là chuyển đổi âm thanh từ lời nói thành định dạng văn bản hoặc lệnh mà máy tính có thể hiểu được. Dĩ nhiên, để thực hiện quá trình này bao gồm khá nhiều bước phức tạp, với các công nghệ hàng đầu như trí tuệ nhân tạo (AI), học máy (Machine Learning), phối hợp cùng các các thuật toán tiên tiến.
1. Thu thập và phân tích âm thanh: Âm thanh từ giọng nói của người dùng sẽ được thu qua micro, sau đó được chuyển đổi thành dạng tín hiệu số. Hệ thống sẽ tiến hành phân tích tín hiệu này để nhận diện các đặc điểm chính như tần số, âm sắc và nhịp điệu.
2. Chia nhỏ âm thanh và số hóa dữ liệu: Tín hiệu âm thanh được chia thành các đoạn nhỏ hơn để xử lý chi tiết hơn. Các đoạn này được số hóa và chuyển thành định dạng mà máy tính có thể phân tích.
3. Khớp tín hiệu với các mẫu âm thanh: Hệ thống sử dụng các mô hình âm học (Acoustic Models) để so sánh tín hiệu âm thanh thu được với các mẫu âm thanh đã được huấn luyện. Điều này giúp xác định mối liên hệ giữa tín hiệu âm thanh và các đơn vị ngôn ngữ như từ hoặc cụm từ.
4. Sử dụng ngữ cảnh để hiểu nghĩa: Mô hình ngôn ngữ (Language Models) được áp dụng để hiểu ngữ cảnh và cú pháp, từ đó sắp xếp các từ thành một câu hoàn chỉnh. Điều này đặc biệt quan trọng trong việc xử lý các từ đồng âm khác nghĩa hoặc giọng nói có sự khác biệt về vùng miền.
5. Học máy và cải thiện liên tục: Các thuật toán học máy liên tục cập nhật và cải thiện độ chính xác bằng cách học từ các mẫu dữ liệu mới. Điều này giúp hệ thống thích nghi với các đặc điểm giọng nói đa dạng như ngữ điệu, phương ngữ, và tạp âm môi trường.
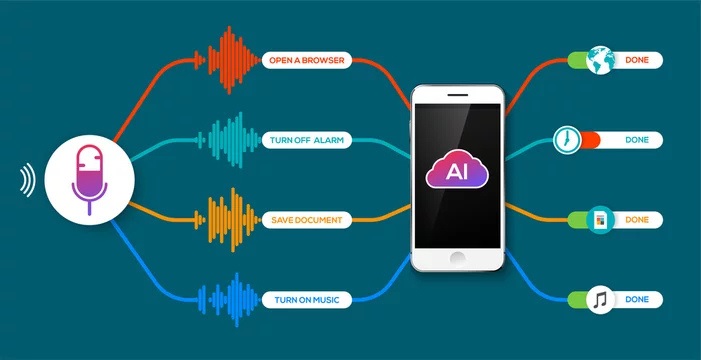
Nhờ quy trình này, công nghệ nhận dạng giọng nói ngày càng trở nên chính xác và linh hoạt hơn. Từ đó, công nghệ này được người dùng tin tưởng và ứng dụng rộng rãi trong nhiều lĩnh vực như trợ lý ảo, tổng đài tự động, dịch thuật ngôn ngữ, hỗ trợ người khuyết tật và các hệ thống điều khiển bằng giọng nói trong doanh nghiệp.
Những tính năng chính của nhận diện giọng nói
Công nghệ nhận diện giọng nói đang len lỏi vào rất nhiều khía cạnh trong đời sống và trở thành công cụ hỗ trợ đắc lực cho con người. Vậy những tính năng chính của Nhận diện giọng nói là gì? Vì sao nó lại được ứng dụng nhiều tới vậy?
- Trọng số ngôn ngữ (Language Weighting): Hệ thống nhận diện giọng nói có thể ưu tiên hoặc chú ý đặc biệt đến một số từ hoặc ngôn ngữ nhất định để tăng độ chính xác. Ví dụ, nếu người dùng thường xuyên sử dụng các thuật ngữ chuyên ngành như y tế hoặc tài chính, hệ thống sẽ tập trung hơn khi nhận diện để hiểu chính xác từ đó.
- Phân biệt và gán nhãn người nói (Speaker Labeling): Trong các cuộc hội thoại nhiều người, công nghệ nhận diện giọng nói có thể phân biệt và gán nhãn cho từng người nói, hỗ trợ trong việc tạo biên bản cuộc họp hoặc phân tích hội thoại.
- Đào tạo âm thanh (Acoustics training): Khả năng hiểu và xử lý ngôn ngữ tự nhiên giúp hệ thống học các giọng nói và điều kiện âm thanh khác nhau như sử dụng địa phương, tốc độ nói và tạp âm từ môi trường. Nhờ có tính năng này, công nghệ nhận diện giọng nói hoạt động hiệu quả trong nhiều tình huống đàm thoại phức tạp.
- Lọc và kiểm duyệt nội dung thô tục (Profanity Filtering): Khả năng nhận diện và lọc bỏ các từ ngữ không phù hợp hoặc nhạy cảm, đảm bảo đầu ra văn bản phù hợp với tiêu chuẩn và ngữ cảnh sử dụng.
Các loại thuật toán sử dụng trong nhận dạng giọng nói
Khi tìm hiểu về nhận diện giọng nói là gì, nhiều người có thể thắc mắc công nghệ sử dụng những thuật toán nào để đảm bảo độ chính xác. Để nhận diện giọng nói hiệu quả, công nghệ này phải áp dụng nhiều thuật toán hiện đại nhằm xử lý tín hiệu âm thanh và ngữ cảnh một cách tối ưu. Dưới đây là những thuật toán quan trọng giúp công nghệ này trở nên mạnh mẽ và linh hoạt hơn:
Xử lý ngôn ngữ tự nhiên - NLP
Mặc dù không phải là một thuật toán cụ thể trong nhận diện giọng nói, Xử lý ngôn ngữ tự nhiên (NLP) là một lĩnh vực của trí tuệ nhân tạo tập trung vào tương tác giữa con người và máy tính thông qua ngôn ngữ nói và văn bản. Nhiều thiết bị di động hiện nay đã tích hợp công nghệ nhận diện giọng nói để hỗ trợ tìm kiếm bằng giọng nói (ví dụ: Siri) hoặc tăng khả năng tiếp cận trong nhắn tin.
Mô hình Markov ẩn ( Hidden Markov Models - HMM)
Mô hình Markov ẩn (HMM) được phát triển dựa trên mô hình chuỗi Markov, trong đó xác suất của một trạng thái chỉ phụ thuộc vào trạng thái hiện tại, không bị ảnh hưởng bởi các trạng thái trước đó. Nếu chuỗi Markov chủ yếu dùng để xử lý các sự kiện quan sát được, như văn bản nhập vào, thì mô hình Markov ẩn cho phép tích hợp các yếu tố ẩn, chẳng hạn như nhãn từ loại (danh từ, động từ, v.v.), vào mô hình xác suất. Trong nhận diện giọng nói, HMM được sử dụng để gán nhãn cho từng đơn vị trong chuỗi âm thanh (từ, âm tiết, câu, v.v.), giúp hệ thống xác định trình tự nhãn phù hợp nhất với dữ liệu đầu vào.
Mạng nơ-ron thần kinh nhân tạo hoặc Neutral Networks
Mạng nơ-ron nhân tạo là nền tảng của các thuật toán học sâu (deep learning), giúp hệ thống xử lý dữ liệu huấn luyện bằng cách mô phỏng cách kết nối của não bộ con người thông qua các lớp nơ-ron. Mỗi nơ-ron trong mạng bao gồm đầu vào, trọng số, một giá trị ngưỡng (bias) và đầu ra. Khi giá trị đầu ra vượt qua ngưỡng cho phép, nơ-ron sẽ kích hoạt và truyền dữ liệu sang lớp tiếp theo. Mạng nơ-ron học cách ánh xạ dữ liệu thông qua học có giám sát (supervised learning), điều chỉnh mô hình dựa trên hàm mất mát thông qua quá trình tối ưu hóa gradient descent.
Mặc dù mạng nơ-ron có thể xử lý dữ liệu với độ chính xác cao hơn và tiếp nhận nhiều dữ liệu hơn, nhưng việc huấn luyện mô hình lại tốn nhiều thời gian và tài nguyên hơn so với các mô hình ngôn ngữ truyền thống.
N-gram
N-gram là một trong những mô hình ngôn ngữ đơn giản nhất, được sử dụng để gán xác suất cho một câu hoặc cụm từ. Một N-gram là một chuỗi gồm N từ liên tiếp. Ví dụ, “gọi món pizza” là một trigram (3-gram), còn “vui lòng gọi món pizza” là một 4-gram. Mô hình này sử dụng quy tắc ngữ pháp và xác suất xuất hiện của các cụm từ để cải thiện độ chính xác của nhận diện giọng nói.
Gắn nhãn người nói ( Speaker Diarization)
Thuật toán Speaker Diarization giúp nhận diện và phân đoạn giọng nói theo từng người nói trong một đoạn hội thoại. Công nghệ này giúp các hệ thống phân biệt giữa nhiều người trong cuộc trò chuyện, đặc biệt hữu ích trong các trung tâm chăm sóc khách hàng khi cần tách biệt giọng nói giữa khách hàng và nhân viên tư vấn.

Những thuật toán này kết hợp chặt chẽ với nhau để tạo nên hệ thống nhận diện giọng nói hiện đại, thông minh và có khả năng đáp ứng nhu cầu đa dạng trong thực tế.
Ưu nhược điểm của công nghệ nhận diện giọng nói
Công nghệ này đã mở ra nhiều cơ hội và tiện ích, nhưng không phải không có những thách thức. Mặc dù giúp tối ưu hóa thời gian và tương tác người dùng, hệ thống vẫn gặp phải một số vấn đề như độ chính xác bị ảnh hưởng bởi tiếng ồn hay giọng nói phức tạp. Để hiểu rõ hơn nhận diện giọng nói là gì, VNPT AI sẽ cung cấp những ưu nhược điểm của nhận diện giọng nói để người đọc có cái nhìn toàn diện hơn về công nghệ này:
Những ưu điểm nổi bật của công nghệ nhận diện giọng nói
- Tiện lợi và tiết kiệm thời gian: Nhận diện giọng nói giúp người dùng thực hiện các tác vụ nhanh chóng mà không cần phải sử dụng bàn phím, từ việc soạn thảo văn bản đến điều khiển thiết bị thông minh.
- Ứng dụng đa dạng: Công nghệ này được sử dụng trong nhiều lĩnh vực như chăm sóc khách hàng, trợ lý ảo, xe tự hành và nhà thông minh, mang lại nhiều tiện ích cho người dùng.
- Tăng cường khả năng tương tác: Giúp người dùng tương tác với hệ thống mà không cần thao tác trực tiếp, hỗ trợ những người có khó khăn về thể chất.

Một số nhược điểm cần lưu ý
- Độ chính xác phụ thuộc vào môi trường: Công nghệ dễ bị ảnh hưởng bởi tiếng ồn và điều kiện môi trường không lý tưởng, gây giảm độ chính xác trong nhận diện.
- Khả năng nhận diện hạn chế với giọng nói phức tạp: Các giọng điệu, âm sắc và ngữ điệu đặc biệt có thể gây khó khăn cho hệ thống trong việc nhận diện chính xác.
- Vấn đề bảo mật: Việc nhận diện giọng nói có thể bị giả mạo hoặc tấn công, tạo ra mối lo ngại về bảo mật trong một số ứng dụng.
Ứng dụng của nhận diện giọng nói trong thực tế
Công nghệ nhận dạng giọng nói đã và đang được ứng dụng rộng rãi trong nhiều lĩnh vực, mang lại tiện ích và hiệu quả cao cho người dùng. Dưới đây là một số ứng dụng nhận dạng giọng nói trong thực tiễn:
Trợ lý ảo giao tiếp bằng giọng nói
Các trợ lý ảo như Siri, Google Assistant và Alexa sử dụng nhận diện giọng nói để thực hiện các tác vụ như đặt lịch, gửi tin nhắn, điều khiển thiết bị thông minh và cung cấp thông tin theo yêu cầu. Điều này giúp người dùng tương tác với công nghệ một cách tự nhiên và thuận tiện hơn.
Hệ thống chăm sóc khách hàng tự động
Nhiều doanh nghiệp đã tích hợp công nghệ nhận diện giọng nói vào hệ thống tổng đài để tự động hóa việc tiếp nhận và xử lý yêu cầu của khách hàng. Điều này không chỉ giảm tải cho nhân viên mà còn nâng cao hiệu quả và độ chính xác trong việc cung cấp thông tin.
Hỗ trợ người khuyết tật
Công nghệ nhận diện giọng nói đóng vai trò quan trọng trong việc hỗ trợ người khuyết tật, đặc biệt là những người gặp khó khăn trong việc sử dụng thiết bị đầu vào truyền thống như bàn phím hoặc chuột. Việc điều khiển thiết bị bằng giọng nói giúp họ tiếp cận công nghệ một cách dễ dàng và độc lập hơn.
Dịch vụ phiên âm và dịch thuật
Nhận diện giọng nói được sử dụng để chuyển đổi lời nói thành văn bản, hỗ trợ trong việc phiên âm cuộc họp, hội thảo hoặc dịch thuật tự động. Điều này giúp tiết kiệm thời gian và tăng cường hiệu quả trong công việc.

Hệ thống bảo mật và xác thực
Một số hệ thống sử dụng nhận diện giọng nói như một phương thức xác thực sinh trắc học, giúp tăng cường bảo mật cho các thiết bị và dịch vụ trực tuyến. Tuy nhiên, cần lưu ý rằng công nghệ này có thể bị ảnh hưởng bởi các yếu tố như tiếng ồn môi trường và sự thay đổi trong giọng nói của người dùng.
Những ứng dụng trên chỉ là một phần nhỏ trong số rất nhiều cách mà công nghệ nhận dạng giọng nói đang được tích hợp vào cuộc sống hàng ngày, mang lại sự tiện lợi và hiệu quả cho người dùng.
5 phần mềm nhận diện giọng nói thành văn bản phổ biến hiện nay
Hiện nay, việc biến lời nói thành văn bản không còn là điều xa lạ. Từ soạn thảo văn bản, quản lý công việc đến điều khiển thiết bị thông minh, các phần mềm nhận diện giọng nói đã trở thành trợ thủ đắc lực giúp chúng ta tiết kiệm thời gian và tăng hiệu quả làm việc. Dưới đây là 5 cái tên nổi bật trong lĩnh vực này:
Google Now
Google Now không chỉ hỗ trợ người dùng thực hiện các tác vụ hàng ngày mà còn mang lại trải nghiệm cá nhân hóa thông minh. Công cụ này có khả năng học hỏi từ thói quen sử dụng của bạn để cung cấp thông tin hữu ích, chẳng hạn như gợi ý tuyến đường đi làm ít kẹt xe, thông báo lịch hẹn sắp tới hoặc hiển thị tin tức theo sở thích. Với tính năng nhận diện giọng nói chính xác và hỗ trợ đa nền tảng, Google Now trở thành trợ lý ảo đáng tin cậy.
Ngoài ra, công cụ này còn tích hợp sâu với hệ sinh thái của Google như Gmail, Google Calendar, và Google Maps, giúp người dùng dễ dàng quản lý mọi hoạt động trong một giao diện duy nhất. Với giao diện đơn giản và khả năng sử dụng miễn phí, Google Now phù hợp cho cả người dùng cá nhân và doanh nghiệp, mang lại sự tiện lợi trong công việc và cuộc sống hàng ngày.
Google Docs
Tính năng nhập liệu bằng giọng nói của Google Docs giúp người dùng soạn thảo văn bản nhanh chóng và chính xác. Với khả năng hỗ trợ hơn 40 ngôn ngữ, trong đó có tiếng Việt, đây là công cụ hữu ích cho những ai cần nhập liệu liên tục hoặc thực hiện các tác vụ liên quan đến văn bản.
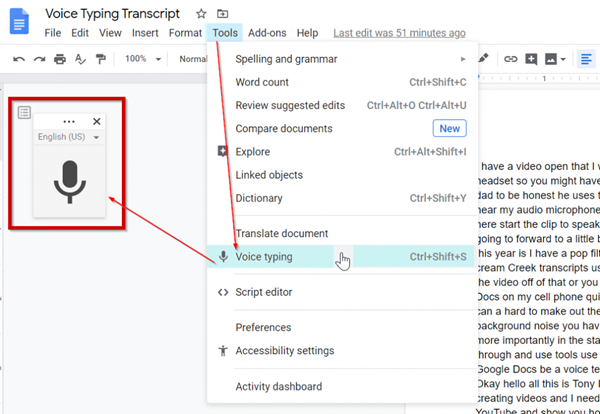
Ngoài ra, Google Docs Voice Typing còn hỗ trợ nhận diện giọng nói trong thời gian thực, giúp tối ưu hóa quá trình làm việc. Với giao diện thân thiện và khả năng sử dụng miễn phí, công cụ này trở thành lựa chọn lý tưởng cho cả cá nhân và doanh nghiệp.
Cortana
Là trợ lý ảo của Microsoft, Cortana hỗ trợ nhận diện giọng nói để thực hiện các lệnh như tìm kiếm, đặt lịch, gửi email và điều khiển thiết bị. Với khả năng tương tác tự nhiên, Cortana không chỉ giúp nâng cao hiệu quả công việc mà còn mang lại trải nghiệm người dùng tốt hơn.
Microsoft Bing Speech API
Bing Speech API là một công cụ mạnh mẽ từ Microsoft, cho phép chuyển đổi giọng nói thành văn bản với độ chính xác cao. Công cụ này hỗ trợ nhiều ngôn ngữ, bao gồm cả tiếng Việt, và phù hợp cho các doanh nghiệp cần tích hợp tính năng nhận diện giọng nói vào sản phẩm hoặc dịch vụ của mình.
VNPT SmartVoice
VNPT SmartVoice là giải pháp Trí tuệ nhân tạo về giọng nói được phát triển bởi VNPT AI, với khả năng chuyển đổi giọng nói thành văn bản (Speech to Text), chuyển đổi văn bản thành giọng nói (Text to Speech) và Xác thực giọng nói với độ chính xác cao. Đồng thời giải pháp này cũng cho phép người dùng Cá nhân hóa giọng nói từ các mẫu âm thanh và tiến hành Phân tích cảm xúc của các cuộc gọi.
VNPT SmartVoice từng đạt giải vàng tại IT World Awards 2022 - hạng mục “SPDV AI mới của năm” và giải Vàng Cyber Security Global Excellence Award 2022 - hạng mục “Sản phẩm dịch vụ mới của năm. Những giải thưởng này là minh chứng rõ ràng cho chất lượng của giải pháp VNPT SmartVoice.
Xu hướng của công nghệ nhận diện giọng nói trong tương lai
Trong bối cảnh công nghệ ngày càng gắn bó chặt chẽ với cuộc sống, nhận diện giọng nói không chỉ dừng lại ở việc hỗ trợ giao tiếp mà còn mở ra những tiềm năng đột phá trong nhiều lĩnh vực. Từ nhà thông minh, chăm sóc sức khỏe cho đến dịch vụ khách hàng, công nghệ này đang chứng minh sức ảnh hưởng vượt trội. Nhưng điều thú vị nhất vẫn nằm ở tương lai, vì vậy hãy cùng VNPT AI khám phá những xu hướng của công nghệ nhận diện giọng nói trong tương lai:
- Nhận diện giọng nói đa ngôn ngữ và cá nhân hóa sâu hơn: Các hệ thống nhận diện giọng nói sẽ ngày càng thông minh hơn, không chỉ hỗ trợ đa ngôn ngữ mà còn nhận diện các sắc thái, ngữ điệu và thậm chí là cảm xúc của người dùng. Điều này giúp tạo ra trải nghiệm giao tiếp tự nhiên hơn, cá nhân hóa từng tương tác và phù hợp với nhu cầu của từng người.
- Ứng dụng mạnh mẽ trong nhà thông minh: Công nghệ nhận diện giọng nói sẽ trở thành trung tâm điều khiển của các thiết bị nhà thông minh. Người dùng có thể ra lệnh bằng giọng nói để quản lý mọi thứ, từ ánh sáng, nhiệt độ cho đến các thiết bị gia dụng, mang lại sự tiện nghi tối đa.
- Tích hợp AI để cải thiện độ chính xác và khả năng dự đoán: Với sự hỗ trợ của trí tuệ nhân tạo (AI), các hệ thống nhận diện giọng nói trong tương lai sẽ không chỉ hiểu chính xác lời nói mà còn dự đoán nhu cầu của người dùng dựa trên ngữ cảnh và hành vi.
- Ứng dụng trong chăm sóc sức khỏe và giáo dục: Công nghệ này sẽ đóng vai trò quan trọng trong việc hỗ trợ y tế từ xa, theo dõi sức khỏe người dùng và cải thiện giao tiếp giữa bác sĩ và bệnh nhân. Trong giáo dục, nhận diện giọng nói có thể giúp xây dựng các nền tảng học tập tương tác, hỗ trợ học sinh và giáo viên hiệu quả hơn.
- Bảo mật và nhận diện sinh trắc học bằng giọng nói: Giọng nói sẽ trở thành một yếu tố xác thực sinh trắc học quan trọng, được ứng dụng rộng rãi trong việc bảo mật thông tin và giao dịch tài chính. Các hệ thống tương lai sẽ đảm bảo tính an toàn cao hơn nhờ khả năng phân tích giọng nói độc nhất của từng cá nhân.
Với những xu hướng này, công nghệ nhận diện giọng nói không chỉ phát triển vượt bậc về mặt kỹ thuật mà còn đóng góp tích cực vào việc nâng cao chất lượng cuộc sống và tối ưu hóa hiệu quả trong mọi lĩnh vực.
Một số câu hỏi thường gặp
Sử dụng phần mềm nhận diện giọng nói có chính xác không?
Độ chính xác của phần mềm nhận diện giọng nói phụ thuộc vào nhiều yếu tố như chất lượng âm thanh, ngữ cảnh sử dụng, và công nghệ được tích hợp. Các phần mềm hiện đại như Google Docs Voice Typing, VNPT SmartVoice hay Microsoft Bing Speech API thường đạt độ chính xác cao, đặc biệt trong môi trường yên tĩnh và khi người dùng phát âm rõ ràng. Tuy nhiên, với giọng địa phương, cách phát âm không chuẩn hoặc âm thanh bị nhiễu, kết quả có thể bị ảnh hưởng. Sự tiến bộ trong công nghệ trí tuệ nhân tạo và xử lý ngôn ngữ tự nhiên đang không ngừng cải thiện độ chính xác này.
Sự khác biệt giữa Speech Recognition và Voice Recognition là gì?
Hai thuật ngữ này thường bị nhầm lẫn nhưng thực chất có sự khác biệt rõ ràng:
- Speech Recognition (nhận diện giọng nói): Là công nghệ chuyển đổi nội dung giọng nói thành văn bản hoặc lệnh để máy tính hiểu và thực thi. Đây là tính năng thường thấy trong các công cụ nhập liệu hoặc trợ lý ảo như Siri, Google Assistant.
- Voice Recognition (nhận diện giọng nói cá nhân): Tập trung vào việc xác định danh tính của người nói dựa trên các đặc điểm riêng của giọng nói. Công nghệ này thường được ứng dụng trong bảo mật sinh trắc học hoặc để cá nhân hóa trải nghiệm người dùng.
Sử dụng phần mềm nhận dạng giọng nói có an toàn không?
Hầu hết các phần mềm nhận diện giọng nói hiện đại đều áp dụng các tiêu chuẩn bảo mật nghiêm ngặt, mã hóa dữ liệu giọng nói và xử lý trên các máy chủ an toàn. Tuy nhiên, để đảm bảo an toàn thông tin, người dùng nên lựa chọn các phần mềm uy tín, đọc kỹ chính sách bảo mật trước khi sử dụng và tránh cung cấp các thông tin nhạy cảm. Đây cũng là ưu tiên hàng đầu của VNPT AI khi phát triển VNPT SmartVoice để đảm bảo tính bảo mật và quyền riêng tư cho người dùng.
Kết luận:
VNPT AI mong rằng bài viết trên đã cung cấp cái nhìn toàn diện về công nghệ nhận diện giọng nói là gì, từ cách hoạt động, tính năng, ứng dụng thực tế đến các xu hướng trong tương lai. Đây không chỉ là một bước tiến trong lĩnh vực trí tuệ nhân tạo mà còn là giải pháp hữu ích, giúp cải thiện đáng kể hiệu suất làm việc và chất lượng cuộc sống.
Những công cụ như VNPT SmartVoice được phát triển bởi VNPT AI là minh chứng cho tiềm năng không giới hạn của công nghệ này, từ tự động hóa quy trình đến cá nhân hóa trải nghiệm người dùng. Vì vậy, có thể nói, trong thời đại công nghệ số, nhận diện giọng nói không chỉ là một lựa chọn mà đã trở thành một phần không thể thiếu trong các hoạt động hàng ngày và chiến lược phát triển của doanh nghiệp.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan




.jpg)