
Text to Speech là gì? 5 Nền tảng chuyển văn bản thành giọng nói nổi bật hiện nay

 10/04/2025
10/04/2025
Text to Speech là một công nghệ vô cùng hữu ích trong thế giới hiện đại, giúp cải thiện khả năng tiếp cận thông tin và tối ưu hóa các hoạt động trong đời sống.
Theo thống kê từ Markets and Markets, thị trường công nghệ Chuyển văn bản thành giọng nói toàn cầu dự kiến đạt 7,6 tỷ USD vào năm 2029 với tăng trưởng ở tốc độ CAGR là 13,7% trong giai đoạn 2024 - 2029. Điều này cho thấy nhu cầu về công nghệ chuyển đổi văn bản thành giọng nói đang ngày càng lớn, được khai thác và ứng dụng trong nhiều lĩnh vực khác nhau từ giáo dục, giải trí đến kinh doanh, hỗ trợ người khiếm thị. Vậy Text to Speech là gì? Đâu là nền tảng TTS tốt nhất, phù hợp với nhu cầu sử dụng? Hãy cùng VNPT AI khám phá 5 nền tảng chuyển đổi văn bản thành giọng nói chất lượng nhất hiện nay để thêm hiểu rõ bạn nhé.
Text to Speech là gì?
Text to Speech (TTS) là công nghệ chuyển văn bản thành giọng nói, giúp máy tính có thể đọc nội dung văn bản một cách tự nhiên. Ban đầu, công nghệ này được phát triển nhằm hỗ trợ người khiếm thị hoặc gặp khó khăn trong việc đọc. Tuy nhiên, ở thời điểm hiện tại, TTS không còn dừng lại ở những định nghĩa đơn thuần - là công cụ “bổ trợ”, thay vào đó, Text to Speech đã được phát triển và “khai phá”, trở thành một giải pháp quan trọng từ trợ lý ảo, tổng đài tự động, cho đến các hệ thống điều hướng và thiết bị thông minh, hỗ trợ việc không nhỏ cho các hoạt động giao tiếp giữa người với người hay con người với máy móc.

>>> Đọc thêm: Speech to Text là gì? Các loại công nghệ STT
Nguyên lý hoạt động của Text-to-Speech
Công nghệ Text-to-Speech chuyển đổi văn bản thành giọng nói thông qua hai giai đoạn chính: xử lý văn bản và tổng hợp giọng nói.
Xử lý văn bản (Text Processing)
Trước khi được chuyển thành âm thanh, văn bản cần được phân tích và chuẩn hóa. Quá trình này đi qua nhiều bước như:
- Nhận diện cấu trúc ngữ pháp: Phân tích từ, câu, dấu câu để xác định ngữ điệu phù hợp.
- Xử lý ký hiệu đặc biệt: Chuyển đổi số, đơn vị đo lường, ngày tháng và các ký hiệu viết tắt thành dạng có thể phát âm được.
- Xác định trọng âm và cách phát âm: Hệ thống ngữ âm học giúp xác định cách đọc chính xác từng từ dựa trên bối cảnh cụ thể.
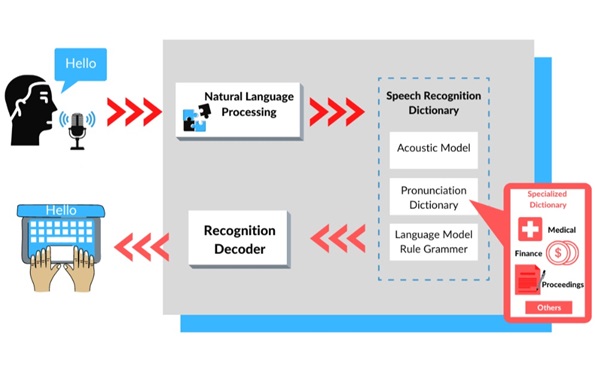
Tổng hợp giọng nói (Speech Synthesis)
Sau khi văn bản được xử lý, hệ thống sẽ tiến hành tạo lập giọng nói/giọng đọc thông qua hai bước chính:
- Tạo đặc trưng âm thanh (Spectrogram Generation): Văn bản sẽ được chuyển thành mel spectrogram - một dạng biểu diễn sóng âm theo thời gian. Trong đó, các mô hình hiện đại như Tacotron 2 sử dụng mạng nơ-ron nhân tạo để tạo ra mel spectrogram từ văn bản đầu vào.
- Biến đổi thành dạng sóng âm thanh (Waveform Generation): Một vocoder như WaveGlow hoặc WaveNet sẽ chuyển mel spectrogram thành dạng sóng âm thanh hoàn chỉnh, từ đó tạo ra giọng nói/giọng đọc tự nhiên như con người.
Một số công nghệ hiện đại trong Text to Speech
Ngày nay, nhờ ứng dụng các mô hình học sâu (Deep Learning), các công cụ Text to Speech đã có sự cải thiện đáng kể về chất lượng giọng nói. Trong đó, tiêu biểu có một số công nghệ nổi bật:
- WaveNet (Google): Mô hình dựa trên mạng nơ-ron tích chập, tạo ra giọng nói/giọng đọc bằng cách mô phỏng từng mẫu sóng âm, mang lại âm sắc có độ tự nhiên cao.
- Tacotron 2 (NVIDIA, Google): Sử dụng mạng nơ-ron hồi quy để tạo ra mel spectrogram, sau đó kết hợp với WaveGlow để tạo giọng nói/giọng đọc trôi chảy.
- WaveGlow: Một mô hình dựa trên kỹ thuật flow-based, giúp tạo ra giọng nói/giọng đọc có độ chính xác cao và tự nhiên hơn.
Lợi ích của công nghệ chuyển văn bản thành giọng nói
Giải pháp chuyển đổi văn bản thành giọng nói không chỉ giúp máy tính đọc văn bản thành giọng nói mà còn mang lại nhiều lợi ích quan trọng trong cuộc sống, hỗ trợ đắc lực cho nhiều hạng mục công việc quan trọng:
- Tăng khả năng tiếp cận thông tin: TTS đặc biệt hữu ích cho người khiếm thị hoặc người gặp khó khăn trong việc đọc. Thay vì phải dựa vào chữ viết, họ có thể nghe nội dung một cách dễ dàng thông qua nội dung âm thanh. Điều này tạo điều kiện không nhỏ cho họ trong việc tiếp cận thông tin trên internet, sách, tài liệu và giao diện số mà không gặp trở ngại.
- Hỗ trợ giáo dục và học tập: Công nghệ này giúp học sinh và sinh viên, đặc biệt là những người gặp khó khăn trong đọc hiểu có thể tiếp thu kiến thức tốt hơn. Ngòi ra, việc nghe sách giáo khoa hoặc tài liệu học tập cũng giúp cải thiện khả năng ghi nhớ, đồng thời giảm mệt mỏi so với việc đọc văn bản truyền thống.
- Ứng dụng trong điều hướng và GPS: Text to Speech được tích hợp trong các ứng dụng bản đồ và hệ thống định vị, cung cấp chỉ đường bằng giọng nói theo thời gian thực. Điều này giúp tài xế hoặc người di chuyển dễ dàng nhận chỉ dẫn mà không cần nhìn hay tập trung vào màn hình, nhờ vậy nâng cao độ an toàn khi lái xe.
- Cải thiện trải nghiệm với trợ lý ảo: Các trợ lý giọng nói như Siri, Google Assistant hay Alexa đều sử dụng công nghệ chuyển đổi văn bản thành giọng nói để giao tiếp với người dùng. Công nghệ này giúp trợ lý ảo phản hồi bằng giọng nói tự nhiên, thân thiện hơn, tạo ra trải nghiệm tương tác thông minh và tiện lợi.
- Phát triển nội dung số và giải trí: Text to Speech giúp chuyển đổi sách viết thành sách nói, mở rộng khả năng tiếp cận cho những người thích nghe hơn đọc, người bận rộn không có nhiều thời gian. Ngoài ra, nó cũng được ứng dụng trong podcast, video thuyết minh, giúp nội dung dễ dàng tiếp cận hơn với nhiều nhóm đối tượng người dùng.
- Tăng hiệu quả làm việc và hỗ trợ đa nhiệm: Nhờ TTS, người dùng có thể nghe email, tin tức hoặc tài liệu ngay trong khi làm việc, khi dọn nhà,... qua đó giúp tối ưu hóa thời gian và tăng hiệu suất công việc. Công nghệ này cũng giúp những người bận rộn có thể tiếp cận thông tin nhanh chóng mà không cần dừng lại để đọc như cách thức tiếp cận thông tin truyền thống.

Những thách thức và hạn chế của Text to Speech
Công nghệ Text-to-Speech đã có những bước tiến lớn trong việc chuyển đổi văn bản thành giọng nói tự nhiên. Tuy nhiên, vẫn còn nhiều hạn chế cần khắc phục để nâng cao trải nghiệm người dùng và khả năng ứng dụng rộng rãi hơn.
Một số hạn chế của công nghệ Text to Speech
- Chất lượng giọng nói chưa tự nhiên: Mặc dù công nghệ TTS hiện đại đã cải thiện đáng kể, nhưng nhiều hệ thống vẫn “mắc lỗi” trong việc tạo ra giọng nói (âm sắc nghe như robot, đơn điệu, thiếu sự trôi chảy). Điều này khiến người dùng khó tập trung và giảm mức độ tương tác với nội dung được tiếp cận.
- Thiếu cảm xúc và sắc thái giọng nói: Con người có thể dễ dàng thể hiện cảm xúc qua giọng nói như vui vẻ, buồn bã, ngạc nhiên… nhưng Text to Speech lại gặp khó khăn trong việc truyền tải những sắc thái này. Điều này khiến TTS trở nên ít thậm chí là không phù hợp với các nội dung cần cảm xúc mạnh, như đọc truyện, thơ, thoại phim hoặc thuyết minh quảng cáo.
- Lỗi phát âm và đọc sai từ đặc biệt: TTS có thể phát âm sai tên riêng, tiếng lóng, thuật ngữ chuyên ngành, từ nước ngoài hoặc các từ đồng âm khác nghĩa. Điều này gây nhầm lẫn cho người nghe, đặc biệt trong các lĩnh vực chuyên môn như y tế, tài chính - ngân hàng, công nghệ,....
- Hiểu sai ngữ cảnh dẫn đến ngữ điệu không phù hợp: Công nghệ chuyển đổi văn bản sang giọng nói không có khả năng hiểu sâu ngữ cảnh như con người, dẫn đến sai sót trong nhấn nhá, ngắt nghỉ câu. Điều này làm giảm tính mạch lạc và gây khó khăn trong việc tiếp thu nội dung của người dùng.
- Xử lý chữ viết tắt không đồng nhất: Một số hệ thống chuyển văn bản thành giọng nói gặp lỗi dẫn đến đọc chữ viết tắt theo nhiều cách khác nhau, gây khó hiểu cho người nghe.

Những thách thức Text to Speech phải đối mặt
- Hỗ trợ đa ngôn ngữ chưa hoàn thiện: Dù nhiều hệ thống TTS đã có khả năng hỗ trợ đa ngôn ngữ, nhưng chúng vẫn gặp khó khăn khi xử lý văn bản có nhiều ngôn ngữ “pha trộn”. Điều này dẫn đến các từ ngoại lai trong một câu có thể bị phát âm sai hoặc không tự nhiên.
- Duy trì giọng điệu mạch lạc trong văn bản dài: Text to Speech có thể không duy trì được giọng điệu nhất quán trong các văn bản dài, dẫn đến ngữ điệu thay đổi bất thường, làm giảm trải nghiệm nghe.
- Đặt câu và nhấn nhá chưa chính xác: Việc ngắt câu không đúng vị trí, lên xuống giọng không phù hợp khiến nội dung khó hiểu hơn. Điều này đặc biệt quan trọng với các ngôn ngữ giàu sắc thái như tiếng Việt, tiếng Trung, tiếng Hàn hay tiếng Nhật.
- Yêu cầu tài nguyên phần cứng mạnh: Đây có lẽ là khó khăn lớn nhất khi tìm hiểu về các thách thức của công nghệ chuyển đổi văn bản thành giọng nói. Thực tế, các hệ thống TTS dựa trên AI hiện đại đòi hỏi nhiều tài nguyên tính toán, dẫn đến làm tăng chi phí vận hành. Điều này gây khó khăn không nhỏ cho các thiết bị di động hoặc hệ thống có hiệu suất thấp.
- Giới hạn trong cá nhân hóa giọng nói: Dù một số công nghệ TTS đã cho phép người dùng tùy chỉnh giọng đọc, nhưng việc tạo ra giọng nói cá nhân hóa hoàn toàn (ví dụ: mô phỏng giọng của một người cụ thể) vẫn là một thách thức lớn với công cụ này.

Ứng dụng thực tiễn của công nghệ chuyển đổi văn bản thành giọng nói
Tài chính ngân hàng
Text to Speech giúp khách hàng dễ dàng tiếp cận thông tin tài chính, đặc biệt là người khiếm thị hoặc gặp khó khăn trong đọc hiểu. Hệ thống tổng đài tự động và trợ lý ảo sử dụng TTS để hỗ trợ tra cứu số dư, nhắc nhở thanh toán và thông báo các giao dịch quan trọng. Điều này giúp ngân hàng cung cấp dịch vụ nhanh chóng và tiết kiệm chi phí hơn, qua đó nâng cao trải nghiệm khách hàng.
Marketing
Text to Speech giúp tạo nội dung quảng cáo tự động, tối ưu hóa chi phí sản xuất mà không cần thuê diễn viên lồng tiếng, đội xử lý âm thanh hiện trường. Ngoài ra, công nghệ này cũng hỗ trợ đọc tin tức, bài viết trên website giúp người dùng tiếp cận nội dung một cách linh hoạt hơn so với trước. Bên cạnh đó, trong lĩnh vực tiếp thị số, TTS cũng giúp cá nhân hóa trải nghiệm khách hàng thông qua email marketing và chatbot giọng nói.
Giáo dục
Trong giáo dục, công nghệ chuyển văn bản thành giọng nói hỗ trợ học sinh khiếm thị, người gặp khó khăn trong đọc hiểu và học ngoại ngữ dễ dàng hơn. Công nghệ này giúp chuyển đổi tài liệu học tập thành âm thanh, tạo điều kiện cho học viên học mọi lúc mọi nơi. Bên cạnh đó, TTS còn giúp cải thiện kỹ năng nghe, phát âm và hỗ trợ đánh giá bài tập thông qua việc đọc lại nội dung do học viên viết.

Y tế
Text to Speech giúp bệnh nhân tiếp cận thông tin y tế một cách dễ dàng hơn, đặc biệt là những người có thị lực kém hoặc gặp khó khăn trong đọc hiểu, người khó tiếp cận không nghệ. Hệ thống có thể đọc đơn thuốc, hướng dẫn sử dụng thuốc và thông báo lịch hẹn khám cho người bệnh. Ngoài ra, các thiết bị y tế thông minh cũng có thể sử dụng TTS để nhắc nhở bệnh nhân uống thuốc đúng giờ theo chỉ định.
Trợ lý ảo & Chatbot thông minh
TTS giúp các trợ lý ảo như Siri, Google Assistant, Alexa giao tiếp tự nhiên với người dùng. Nhờ công nghệ này, trợ lý ảo có thể đọc tin nhắn, thông báo trên điện thoại, thực hiện tìm kiếm thông tin bằng giọng nói và hỗ trợ dịch vụ khách hàng 24/7. Điều này giúp nâng cao tính tiện lợi và cải thiện hiệu suất công việc hàng ngày.
Thiết bị IoT và Nhà thông minh
Công nghệ chuyển đổi văn bản sang giọng nói được tích hợp vào các thiết bị IoT như loa thông minh, đồng hồ thông minh và hệ thống an ninh gia đình. Công nghệ này giúp các thiết bị giao tiếp với người dùng dễ dàng thông qua giọng nói, hoàn thành nhanh chóng các tác vụ như: thông báo thời tiết, nhắc lịch trình và cảnh báo an ninh. Nhờ đó, các thiết bị thông minh có thể cung cấp trải nghiệm tương tác tự nhiên và hiệu quả hơn.

Hỗ trợ điều hướng và bản đồ GPS
Text to Speech giúp các hệ thống GPS cung cấp chỉ dẫn bằng giọng nói trong thời gian thực, giúp tài xế tập trung lái xe mà không cần nhìn vào màn hình. Hệ thống có thể đọc tên đường, cảnh báo tình trạng giao thông và đề xuất tuyến đường thay thế tối ưu nhất. Điều này giúp cải thiện an toàn và tiện lợi khi di chuyển cho các bác tài.
Hỗ trợ người khuyết tật và cải thiện khả năng tiếp cận
TTS mang lại lợi ích lớn cho người khiếm thị, người có khó khăn trong đọc hiểu bằng cách “chuyển hóa” nội dung trên trang web, tài liệu, email và tin nhắn thành dạng âm thanh. Công nghệ này cũng được sử dụng trong các thiết bị hỗ trợ giao tiếp cho người mất khả năng nói, giúp họ dễ dàng trao đổi thông tin với người khác.
Các nền tảng và phần mềm Text to Speech tốt nhất hiện nay
Với sự phát triển không ngừng của khoa học công nghệ, hàng loạt các phần mềm chuyển văn bản thành giọng nói ra đời và được khai thác rộng rãi trong mọi lĩnh vực đời sống. Một số các phần mềm text to speech nổi bật hiện nay:
Phần mềm chuyển văn bản thành giọng nói có cảm xúc - Google Text-to-Speech
Google Text-to-Speech là một nền tảng TTS mạnh mẽ do Google phát triển, sử dụng công nghệ WaveNet để tạo ra giọng nói tự nhiên và giàu cảm xúc. Hệ thống hỗ trợ 57 ngôn ngữ và nhiều biến thể giọng đọc, giúp đáp ứng nhu cầu của người dùng trên toàn cầu. Google TTS được tích hợp trong Google Assistant, Android, các ứng dụng đọc sách, podcast, GPS và chatbot,.... Ngoài ra, nền tảng này còn cung cấp API dễ dàng tích hợp vào hệ thống doanh nghiệp.
- Ưu điểm: Giọng nói chân thực, nhiều tùy chọn tùy chỉnh (tốc độ, cao độ, âm lượng), hỗ trợ đa ngôn ngữ.
- Nhược điểm: Việc tích hợp API đòi hỏi kiến thức kỹ thuật, chi phí cao cho phiên bản cao cấp.
- Chi phí: Gói Standard 4$/1 triệu ký tự, gói Premium 16$/1 triệu ký tự.
Phần mềm Text To Speech online- OpenAI TTS
OpenAI TTS là một trong những hệ thống TTS tiên tiến nhất hiện nay, sử dụng công nghệ học sâu để tạo giọng nói tự nhiên, có cảm xúc và linh hoạt. OpenAI TTS hỗ trợ nhiều ngôn ngữ, biến thể giọng đọc và cung cấp khả năng tùy chỉnh tốc độ, nhịp điệu, cường độ giọng nói linh hoạt theo nhiều cấp độ khác nhau. Nền tảng này được sử dụng trong các công cụ trợ lý ảo, chatbot, giáo dục trực tuyến, marketing và giải trí.
- Ưu điểm: Giọng đọc chân thực, hỗ trợ nhiều phong cách giọng nói, khả năng tùy chỉnh cao.
- Nhược điểm: Chi phí cao hơn so với các dịch vụ khác, chưa có gói miễn phí hấp dẫn.
- Chi phí: Gói Standard 15$/1 triệu ký tự, gói Premium 30$/1 triệu ký tự.
Phần mềm TTS phổ biến - Narakeet
Narakeet là một công cụ TTS phổ biến bậc nhất hiện, cho phép người dùng chuyển đổi văn bản thành giọng nói mà không cần lập trình. Người dùng có thể nhập văn bản từ Markdown, Google Docs hoặc nhập trực tiếp. Với giao diện thân thiện, Narakeet phù hợp với mọi đối tượng, bao gồm cả người không có kỹ thuật chuyên sâu (người làm nội dung số, giảng viên và doanh nghiệp cần tạo nội dung tự động) nhưng vẫn muốn tạo nội dung âm thanh và video chuyên nghiệp. Nền tảng này hỗ trợ 80 ngôn ngữ, hơn 500 giọng đọc khác nhau, thích hợp để tạo sách nói, video hướng dẫn, bản tin âm thanh.
- Ưu điểm: Dễ sử dụng, hỗ trợ nhiều ngôn ngữ, không cần tích hợp API.
- Nhược điểm: Không hỗ trợ nhiều tùy chỉnh chuyên sâu như các nền tảng AI khác.
- Chi phí: Tính phí theo phút giọng đọc, giá dao động từ 5-20$ cho mỗi 30 phút.
Phần mềm chuyển văn bản thành giọng nói miễn phí - IBM Watson Text to Speech
IBM Watson TTS sử dụng trí tuệ nhân tạo để tạo ra giọng đọc tự nhiên và có thể cá nhân hóa. Hệ thống này hỗ trợ đa ngôn ngữ, nhiều phong cách giọng đọc khác nhau và có khả năng đọc hiểu ngữ cảnh để cải thiện độ chân thực của giọng nói. IBM Watson TTS hiện được ứng dụng nhiều trong chăm sóc khách hàng, giáo dục, y tế và trợ lý ảo.
- Ưu điểm: Giọng đọc mượt mà, hỗ trợ nhiều tùy chỉnh, dễ dàng tích hợp vào hệ thống doanh nghiệp.
- Nhược điểm: Giá thành cao hơn so với Google và Amazon, cần có kiến thức kỹ thuật để triển khai API.
- Chi phí: 20$/1 triệu ký tự, có gói miễn phí 10.000 ký tự/tháng.
Phần mềm Text to Speech Tiếng Việt - VNPT SmartVoice
VNPT SmartVoice là nền tảng chuyển văn bản thành giọng nói phát triển bởi tập đoàn VNPT, cung cấp giọng đọc tiếng Việt chuẩn ba miền Bắc - Trung - Nam. Hệ thống TTS VNPT AI này được ứng dụng rộng rãi trong các ứng dụng đọc sách nói, tổng đài tự động, trợ lý ảo và các dịch vụ công nghệ trong nước. Với khả năng tùy chỉnh cao, ngắt nghỉ tự nhiên, hỗ trợ cá nhân hóa giọng đọc, VNPT SmartVoice đang trở thành lựa chọn hàng đầu cho doanh nghiệp, các tổ chức Chính phủ và cá nhân tại Việt Nam.
- Ưu điểm: Giọng đọc tự nhiên, chuẩn tiếng Việt ba miền, dễ tích hợp vào ứng dụng trong nước
- Nhược điểm: Hỗ trợ ngôn ngữ còn hạn chế so với các nền tảng quốc tế.
- Chi phí: Đa dạng gói cước phí, tùy chỉnh dựa trên nhu cầu sử dụng của từng khách hàng, và có hỗ trợ API cho doanh nghiệp.
Xu hướng phát triển của công nghệ Text to Speech trong tương lai
Công nghệ chuyển đổi văn bản thành giọng nói đang phát triển mạnh mẽ nhờ những tiến bộ trong trí tuệ nhân tạo (AI), học sâu (Deep Learning) và xử lý ngôn ngữ tự nhiên (NLP). Trong tương lai, TTS sẽ trở nên tự nhiên hơn, cá nhân hóa hơn và ứng dụng rộng rãi hơn trong nhiều lĩnh vực. Dưới đây là những xu hướng quan trọng sẽ định hình sự phát triển của công nghệ này.
Tích hợp AI và học máy để nâng cao chất lượng giọng nói
Các mô hình AI tiên tiến như Transformers, WaveNet, Tacotron đang được ứng dụng mạnh mẽ vào TTS nhằm hoàn thiện thêm tính năng của công cụ này, đem đến giọng nói ngày càng chân thực và biểu cảm hơn. Nhờ học máy, TTS có thể hiểu ngữ cảnh, điều chỉnh ngữ điệu và tạo ra giọng nói gần giống con người. Bên cạnh đó, AI còn giúp cải thiện khả năng hiểu ngôn ngữ và văn hóa, giúp TTS phát âm chính xác hơn trong các tình huống giao tiếp tự nhiên.
Nhân bản giọng nói (Voice Cloning) - Cá nhân hóa giọng đọc
Công nghệ Voice Cloning cho phép sao chép giọng nói của một cá nhân và tái tạo giọng nói đó trong các ứng dụng Text to Speech. Điều này giúp cá nhân hóa trải nghiệm người dùng, mở ra nhiều tiện ích khác cho các công cụ sách nói, trợ lý ảo, hay tổng đài chăm sóc khách hàng.
AI lồng tiếng (AI Dubbing) - Cách mạng hóa nội dung đa phương tiện
AI Dubbing giúp đồng bộ giọng nói với chuyển động miệng trong video một cách tự nhiên, nhờ vậy giúp tối ưu hóa việc lồng tiếng phim, video giáo dục và nội dung trực tuyến. Công nghệ này giúp tự động chuyển đổi ngôn ngữ, tạo ra các bản dịch thoại sát với nguyên bản hơn so với trước đó.

Chuyển đổi giọng nói (Voice Conversion) - Linh hoạt hơn trong sáng tạo nội dung
Voice Conversion cho phép chuyển đổi giọng nói từ một người sang một giọng khác, giúp tạo ra giọng nói đa dạng hơn mà không cần tiến hành thu âm mới. Điều này đặc biệt hữu ích trong phát triển trò chơi điện tử, sáng tạo phim hoạt hình, podcast.
Cải thiện khả năng đọc, tăng tính xúc cảm - Giọng nói giàu biểu cảm hơn
Trong tương lai, công nghệ TTS sẽ cảm nhận được cảm xúc và điều chỉnh giọng nói phù hợp với từng bối cảnh cụ thể. Điều này giúp giọng nói trở nên mượt mà hơn, mang lại trải nghiệm chân thực hơn, đặc biệt lý tưởng khi ứng dụng trong các lĩnh vực như trợ lý ảo, chăm sóc khách hàng và sách nói.
Hỗ trợ đa ngôn ngữ tốt hơn - Giọng đọc “gần gũi” hơn với từng vùng miền
Các hệ thống TTS trong tương lai sẽ có khả năng xử lý nhiều ngôn ngữ cùng lúc, chuyển đổi mượt mà giữa các ngôn ngữ trong một văn bản. Đồng thời, chúng cũng có thể tùy chỉnh giọng đọc theo từng vùng miền, giúp người dùng cảm thấy quen thuộc và dễ tiếp nhận hơn.

Tạm kết
Những thông tin được chia sẻ trên đây của VNPT AI đã phần nào giúp bạn hiểu hơn về khái niệm Text to Speech là gì và những lợi ích công cụ này đem lại. Có thể thấy rằng, công nghệ chuyển văn bản thành giọng nói không chỉ giúp tự động hóa nội dung âm thanh mà còn mở ra nhiều cơ hội mới trong các lĩnh vực như giáo dục, kinh doanh và giải trí,.... Đặc biệt, với những nền tảng hàng đầu hiện nay, bạn có thể dễ dàng tạo ra giọng đọc tự nhiên, truyền cảm nhanh chóng, đáp ứng mọi nhu cầu sử dụng khác nhau.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan

.png)