
QLoRA là gì? Giải pháp tối ưu bộ nhớ và tinh chỉnh LLM hiệu quả

 23/10/2025
23/10/2025
QLoRA là phiên bản cải tiến của LoRA được thiết kế để tinh chỉnh mô hình ngôn ngữ lớn LLM một cách hiệu quả hơn về bộ nhớ và tốc độ, đặc biệt chỉ khi có GPU tầm trung hoặc thấp.
Trong kỷ nguyên AI bùng nổ, việc tinh chỉnh LLM hiệu quả trên phần cứng phổ thông là yêu cầu cấp thiết. Đây chính là lúc kỹ thuật QLoRA khẳng định vai trò tiên phong của mình. Phương pháp này tạo ra bước tiến đột phá, cho phép doanh nghiệp cá nhân hóa các mô hình ngôn ngữ lớn mà không cần đầu tư hạ tầng GPU khổng lồ. Vậy QLoRA là gì, hoạt động như thế nào và có những hạn chế gì khi áp dụng? Hãy để VNPT AI cung cấp đến bạn câu trả lời chi tiết nhất!
QLoRA là gì?
QLoRA (Quantized Low-Rank Adaptation) là một kỹ thuật tinh chỉnh (fine-tuning) tiên tiến dành cho các mô hình ngôn ngữ lớn (Large Language Model - LLMs). Phương pháp này được phát triển nhằm giải quyết bài toán chi phí bộ nhớ và tài nguyên tính toán, vốn là hai rào cản lớn khi huấn luyện các mô hình AI hiện đại.
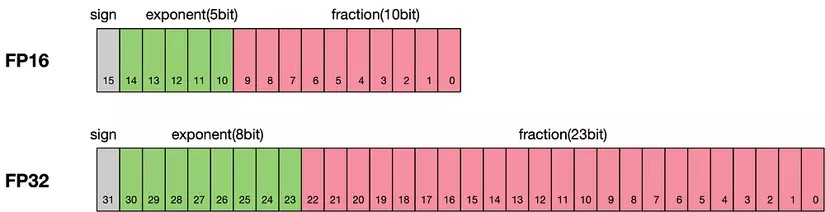
Khác với các phương pháp truyền thống - vốn tiêu tốn lượng lớn RAM hoặc VRAM, QLoRA kết hợp giữa kỹ thuật lượng tử hóa (quantization) và phương pháp thích ứng hạng thấp (Low-Rank Adaptation - LoRA). Sự kết hợp này cho phép giảm đáng kể độ chính xác số học trong quá trình lưu trữ, trong khi vẫn duy trì độ chính xác cao khi tính toán và học sâu.
QLoRA hoạt động như thế nào?
QLoRA hoạt động dựa trên quy trình gồm 3 bước chính như sau:
Bước 1: Lượng tử hóa mô hình nền
Trước tiên, mô hình ngôn ngữ lớn được lượng tử hóa xuống định dạng 4-bit, thay vì sử dụng các trọng số độ chính xác cao (như float32). Việc này giúp giảm đáng kể kích thước mô hình cũng như lượng bộ nhớ cần thiết để lưu trữ và vận hành.
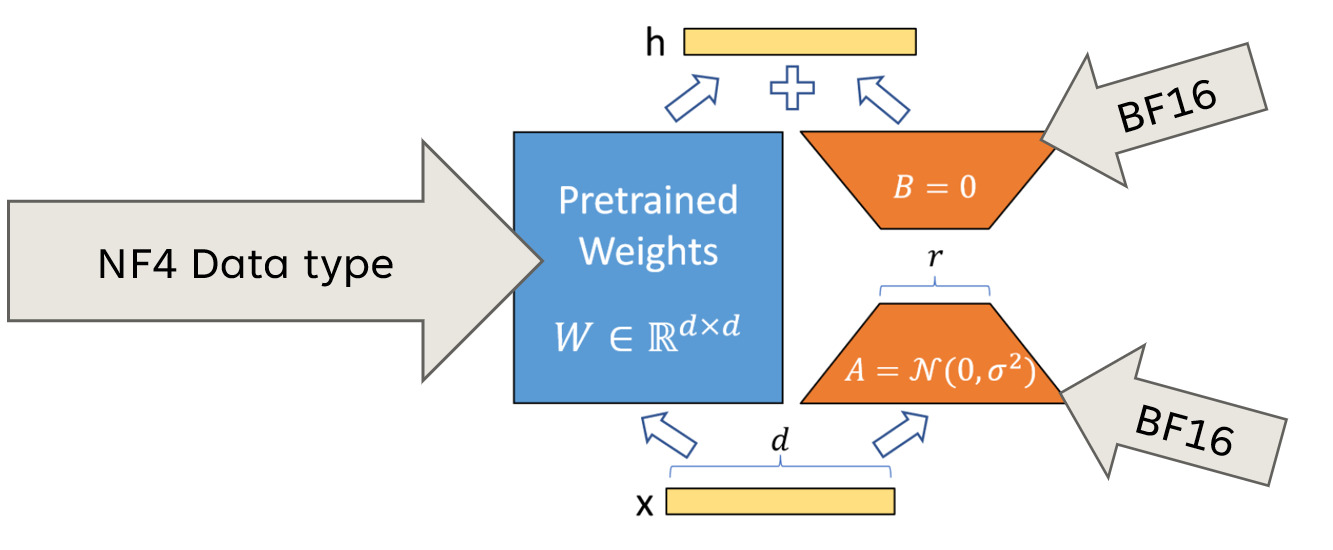
Đặc biệt, kỹ thuật 4-bit Normal Float (NF4) được sử dụng để đảm bảo độ chính xác sau lượng tử hóa bằng cách phân bố trọng số thành các "bucket" giá trị và ánh xạ về dải chuẩn [-1, 1].
Bước 2: Áp dụng bộ điều chỉnh LoRA hạng thấp
Tiếp theo, bộ điều chỉnh hạng thấp (LoRA adapters) được chèn vào các lớp trọng yếu trong mô hình. Các adapter này chỉ tác động đến một phần nhỏ tham số, nhưng vẫn mang lại hiệu quả tinh chỉnh mạnh mẽ. Nhờ vậy, mô hình có thể học thêm thông tin mới mà không cần cập nhật toàn bộ trọng số.
Trong QLoRA, các ma trận điều chỉnh LoRA được giữ ở độ chính xác cao hơn (float16), giúp bù đắp sai số sinh ra từ bước lượng tử hóa.
Bước 3: Tinh chỉnh tiết kiệm bộ nhớ
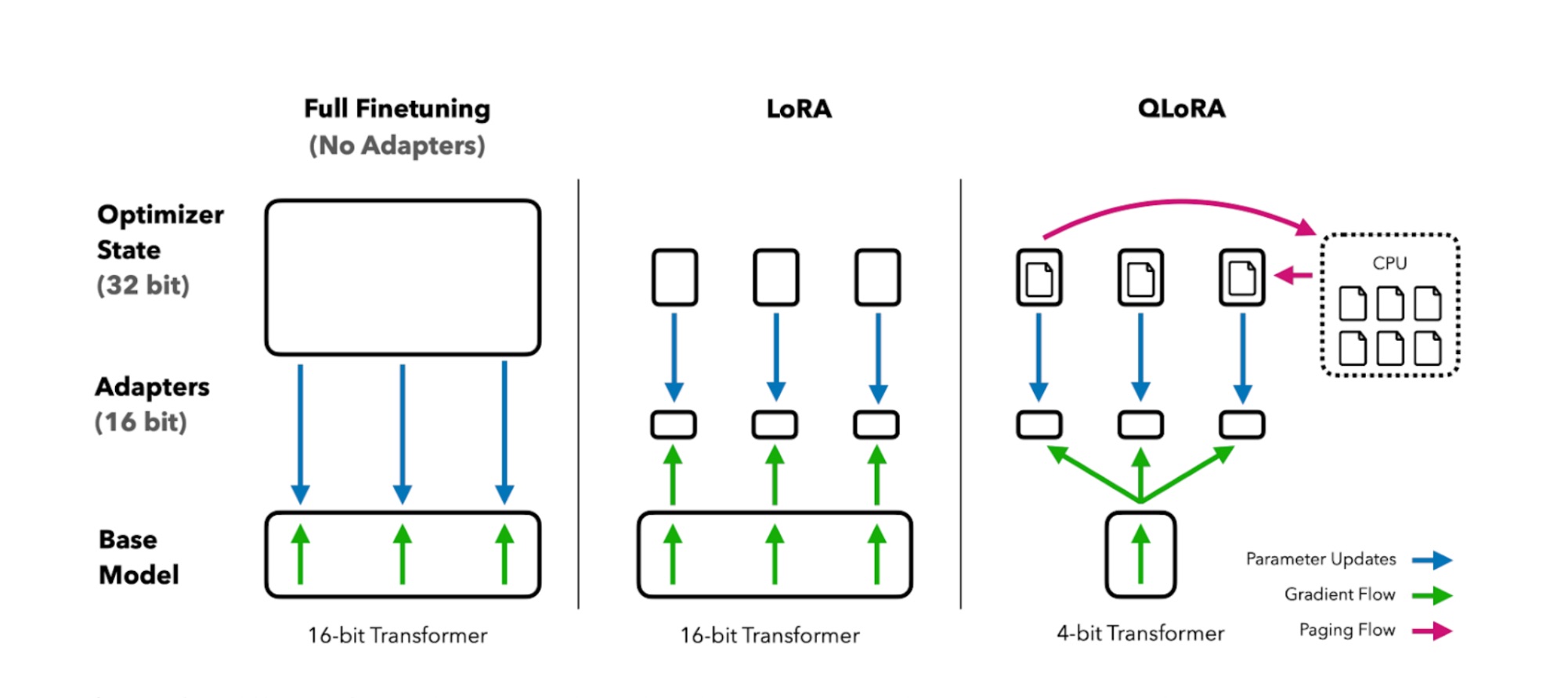
Cuối cùng, mô hình đã lượng tử hóa kết hợp với adapter hạng thấp được tinh chỉnh trên tập dữ liệu mục tiêu. Việc này diễn ra với mức tiêu tốn bộ nhớ và tính toán thấp hơn đáng kể so với các phương pháp fine-tune truyền thống. Ví dụ: Mô hình GPT-3 có thể có hàng trăm tỷ tham số, nếu ta sử dụng 32-bit để lưu trữ các trọng số, thì bộ nhớ cần dùng cơ bản sẽ rất lớn (lên tới hàng trăm GB). Sau khi lượng tử hóa xuống 8-bit, bộ nhớ yêu cầu có thể giảm một nửa, trong khi hiệu suất mô hình vẫn được duy trì ở mức chấp nhận được.
Ngoài ra, QLoRA còn ứng dụng các kỹ thuật tối ưu như Double Quantization (lượng tử hóa kép) và Paged Optimizer nhằm giảm dung lượng lưu trữ hơn nữa mà vẫn giữ được hiệu suất mô hình.
Ưu điểm của QLoRA
QLoRA được xem như một giải pháp tối ưu cho việc tinh chỉnh mô hình ngôn ngữ lớn nhờ vào ưu thế nổi bật sau:
- Tối ưu bộ nhớ: QLoRA kết hợp hai kỹ thuật: lượng tử hóa và điều chỉnh hạng thấp giúp giảm đáng kể dung lượng bộ nhớ của mô hình. Điều này cho phép triển khai các mô hình LLM trên thiết bị có tài nguyên hạn chế như GPU dung lượng thấp hoặc thiết bị biên (edge device).
- Hiệu quả tính toán cao: Việc giảm kích thước mô hình đi kèm với sử dụng adapter nhỏ gọn giúp giảm tải cho phần cứng trong cả quá trình huấn luyện lẫn suy luận.
- Tinh chỉnh tiết kiệm tài nguyên: Thay vì huấn luyện lại toàn bộ mô hình, QLoRA chỉ cập nhật một lượng nhỏ tham số thông qua các adapter. Nhờ vậy, quá trình fine-tune trở nên nhanh hơn, tốn ít chi phí hơn và phù hợp cả với phần cứng phổ thông.
- Duy trì chất lượng mô hình: Dù áp dụng lượng tử hóa 4-bit, QLoRA vẫn giữ được hiệu suất gần tương đương với mô hình gốc dùng độ chính xác đầy đủ. Đặc biệt, khi được tinh chỉnh theo tác vụ cụ thể, QLoRA cho thấy khả năng thích nghi tốt và sai số rất thấp.

Sự khác nhau giữa QLoRA và LoRA
Cả QLoRA và LoRA đều là kỹ thuật fine-tune ưu việt, thường được áp dụng cho các mô hình ngôn ngữ lớn. Tuy nhiên ở cả 2 có sự khác biệt cơ bản nằm ở khả năng tối ưu bộ nhớ, cơ chế hoạt động và mức độ phù hợp với các điều kiện phần cứng. Cụ thể:
Đặc điểm | LoRA | QLoRA |
Mô hình gốc | Tải lên GPU ở định dạng 16-bit hoặc 32-bit | Được lượng tử hóa xuống 4-bit trước khi tải lên GPU |
Bộ nhớ GPU yêu cầu | Cao, đặc biệt với các mô hình lớn | Thấp hơn đáng kể (chỉ cần khoảng 1/4 bộ nhớ so với LoRA) |
Phần được đào tạo | Chỉ cập nhật các ma trận LoRA nhỏ | Chỉ cập nhật ma trận LoRA, nhưng tương tác với mô hình đã lượng tử |
Cơ chế đào tạo | Gradient descent trực tiếp trên ma trận LoRA | Kết hợp kỹ thuật double quantization và paged optimizer để tối ưu bộ nhớ |
Độ phức tạp của kỹ thuật | Trung bình | Cao hơn do cần quản lý quá trình lượng tử hóa và giải lượng tử hóa |
Phù hợp cho | Máy chủ có VRAM lớn | Thiết bị phần cứng hạn chế VRAM, máy trạm cá nhân, GPU tầm trung |
Các trường hợp sử dụng QLoRA
QLoRA ngày càng chứng tỏ tính ứng dụng cao trong thực tiễn, điển hình với 3 trường hợp dưới đây:
- Triển khai trên thiết bị biên (Edge Devices): Nhờ khả năng lượng tử hóa 4-bit cùng cơ chế thích nghi thông minh, QLoRA giúp thu gọn mô hình ngôn ngữ lớn đủ mức để vận hành trực tiếp trên các thiết bị có tài nguyên hạn chế như smartphone, IoT hay camera thông minh,.... Giải pháp này vừa đảm bảo được hiệu suất xử lý, vừa kéo dài thời lượng pin, đồng thời hoạt động mượt mà ngay cả khi mất kết nối internet.
- Tinh chỉnh tiết kiệm chi phí: Trong bối cảnh chi phí GPU ngày càng cao, QLoRA mang lại giải pháp tối ưu cho các đơn vị nghiên cứu, startup hoặc doanh nghiệp nhỏ. Phương pháp này cho phép tinh chỉnh mô hình ngôn ngữ lớn (LLM) một cách hiệu quả, ngay cả khi triển khai trên phần cứng phổ thông như GPU 24GB. Điều này giúp doanh nghiệp tối ưu hóa nguồn lực và giảm đáng kể nhu cầu đầu tư vào hạ tầng máy chủ lớn, có thể thử nghiệm nhanh nhiều phiên bản mô hình khác nhau,...
- Suy luận thời gian thực: Nhờ mô hình nhẹ hơn sau tinh chỉnh, QLoRA hỗ trợ suy luận hiệu quả với độ trễ tối thiểu, tiết kiệm tối đa chi phí vận hành. Kỹ thuật này được cho là phù hợp hơn cho các hệ thống đề xuất đòi hỏi khả năng phản hồi nhanh, mượt mà như chatbot, trợ lý ảo,..

Những thách thức và hạn chế của QLoRA
Dù mang lại nhiều đột phá trong việc tối ưu mô hình ngôn ngữ lớn, QLoRA vẫn tồn tại một số hạn chế như:
- Nhiễu do lượng tử hóa: Việc áp dụng lượng tử hóa 4-bit khiến QLoRA có thể tạo ra nhiễu số học, ảnh hưởng đến độ chính xác của mô hình trong một số tác vụ chuyên biệt.
- Khả năng thích ứng còn hạn chế: QLoRA chủ yếu chỉnh sửa một phần nhỏ tham số thông qua các adapter. Do đó phạm vi tùy biến của mô hình có thể bị giới hạn trong những tác vụ đòi hỏi sự điều chỉnh sâu hoặc mang tính đặc thù cao.
- Độ trễ do giải lượng tử: Trong quá trình suy luận, việc phải giải lượng tử để chuyển đổi dữ liệu từ định dạng 4-bit về chuẩn tính toán có thể gây ra độ trễ nhỏ, làm ảnh hưởng phần nào đến tốc độ phản hồi, đặc biệt trong các hệ thống thời gian thực.
- Tính đặc thù theo tác vụ: Hiệu quả của QLoRA không đồng đều giữa các lĩnh vực. Một số mô hình khi tinh chỉnh bằng QLoRA có thể hoạt động tốt với tác vụ ngôn ngữ tổng quát. Tuy nhiên các mô hình này lại kém hiệu quả hơn ở các tác vụ chuyên ngành như y tế, pháp luật, tài chính - nơi yêu cầu mức hiểu ngữ cảnh rất sâu.
- Khả năng mở rộng trong tương lai: Khi quy mô mô hình tiếp tục tăng lên, QLoRA khó có thể giữ được tính khả thi về mặt hiệu suất và chi phí. Ngoài ra, việc mở rộng QLoRA để tương thích với các kiến trúc mới và mô hình siêu lớn vẫn đang là điều cần được xem xét kỹ.

Tạm kết:
QLoRA là một kỹ thuật tinh chỉnh tiên tiến, giúp giải quyết hiệu quả bài toán tài nguyên và chi phí trong kỷ nguyên mô hình ngôn ngữ lớn. Nhờ cơ chế lượng tử hóa 4-bit kết hợp với Low-Rank Adaptation, QLoRA cho phép các doanh nghiệp tối ưu hóa bộ nhớ và khai thác LLM trên cả phần cứng phổ thông. Tuy nhiên, khi triển khai kỹ thuật này cần lưu ý các hạn chế về nhiễu lượng tử hóa và khả năng thích ứng theo từng tác vụ chuyên biệt, nhằm đảm bảo mô hình vẫn giữ được độ chính xác mong muốn
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá