
Mixture of Experts là gì? Ưu nhược điểm và những ứng dụng trong thực tế

 05/12/2025
05/12/2025
Mixture of Experts (MoE) giữ vai trò tring tâm trong việc cây dựng các mô hình nền tảng (đặc biệt là LLM) quy mô rất lớn mà vẫn kiểm soát được chi phí tính toán, với nhiều ứng dụng trong NLP, thị giác máy tính và hệ thống đa nhiệm.
Trong cuộc đua Trí tuệ nhân tạo (AI), mô hình càng lớn, hiệu suất càng cao, chi phí càng đắt đỏ. Mixture of Experts (MoE) xuất hiện như một giải pháp đột phá, giải quyết nhanh vấn đề này. Điển hình, kiến trúc MoE của mô hình GLaM đã chứng minh khả năng mở rộng lên tới 1,2 nghìn tỷ tham số nhưng chỉ yêu cầu mức tính toán tương đương mô hình 32 tỷ tham số, qua đó giúp tiết kiệm tới 2/3 năng lượng huấn luyện. Vậy MoE là gì, có ưu nhược điểm như thế nào và được ứng dụng ra sao trong thực tế? Hãy cùng VNPT AI đi tìm hiểu chi tiết trong bài viết dưới đây!
Mixture of experts là gì?
Mixture of Experts (MoE) là một phương pháp trong học máy, hoạt động theo cơ chế “chuyên môn hóa” các mô hình nhỏ để cùng giải quyết một nhiệm vụ lớn. Thay vì sử dụng một mạng nơ-ron duy nhất cho toàn bộ dữ liệu, MoE chia mô hình thành nhiều “expert” (chuyên gia), mỗi chuyên gia phụ trách một phần dữ liệu hoặc khía cạnh cụ thể của bài toán.
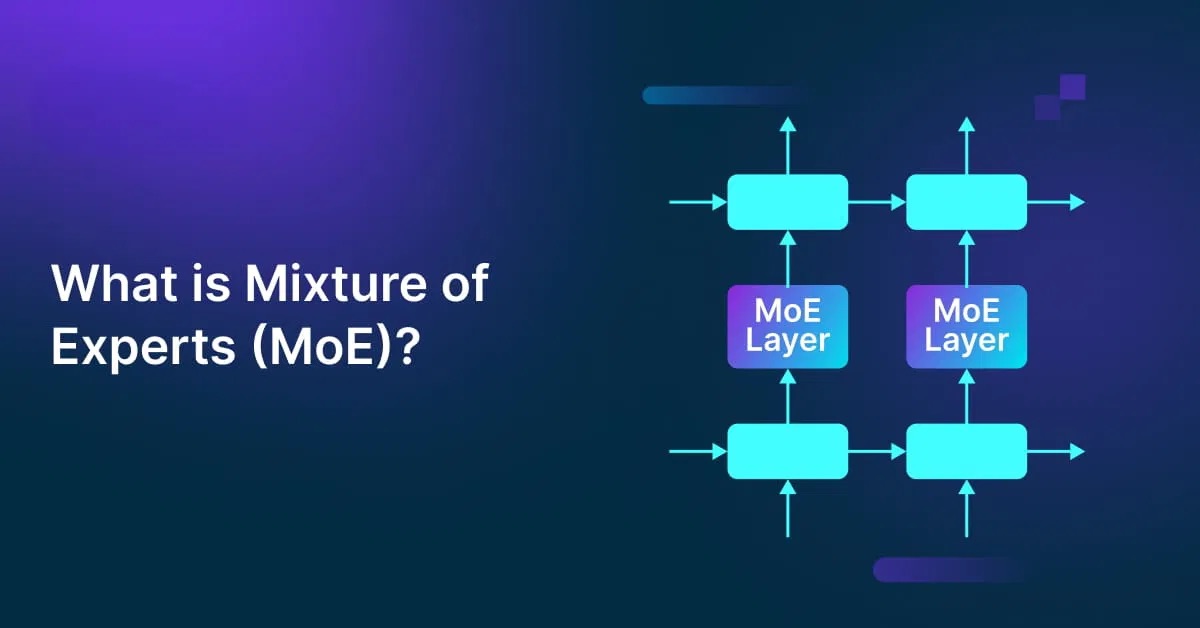
Cấu trúc này giúp mô hình xử lý thông tin chính xác và hiệu quả hơn. Khi nhận đầu vào, một mạng “gating” (mạng chọn cổng) sẽ quyết định chuyên gia nào phù hợp nhất để thực hiện tác vụ đó. Nhờ cơ chế kích hoạt chọn lọc, chỉ các chuyên gia cần thiết được sử dụng, giúp giảm chi phí tính toán và rút ngắn thời gian suy luận.
Mixture of Experts được xem là hướng tiếp cận tối ưu cho các mô hình AI quy mô lớn, cân bằng giữa hiệu năng cao và tính tiết kiệm tài nguyên. Nhiều mô hình ngôn ngữ hàng đầu hiện nay như Mixtral 8x7B hay GPT-4 cũng đang áp dụng kiến trúc MoE để tăng khả năng mở rộng và hiệu quả trong quá trình huấn luyện.
Nguyên lý hoạt động của Mixture of Experts (MoE)
Cơ chế hoạt động của Mixture of Experts
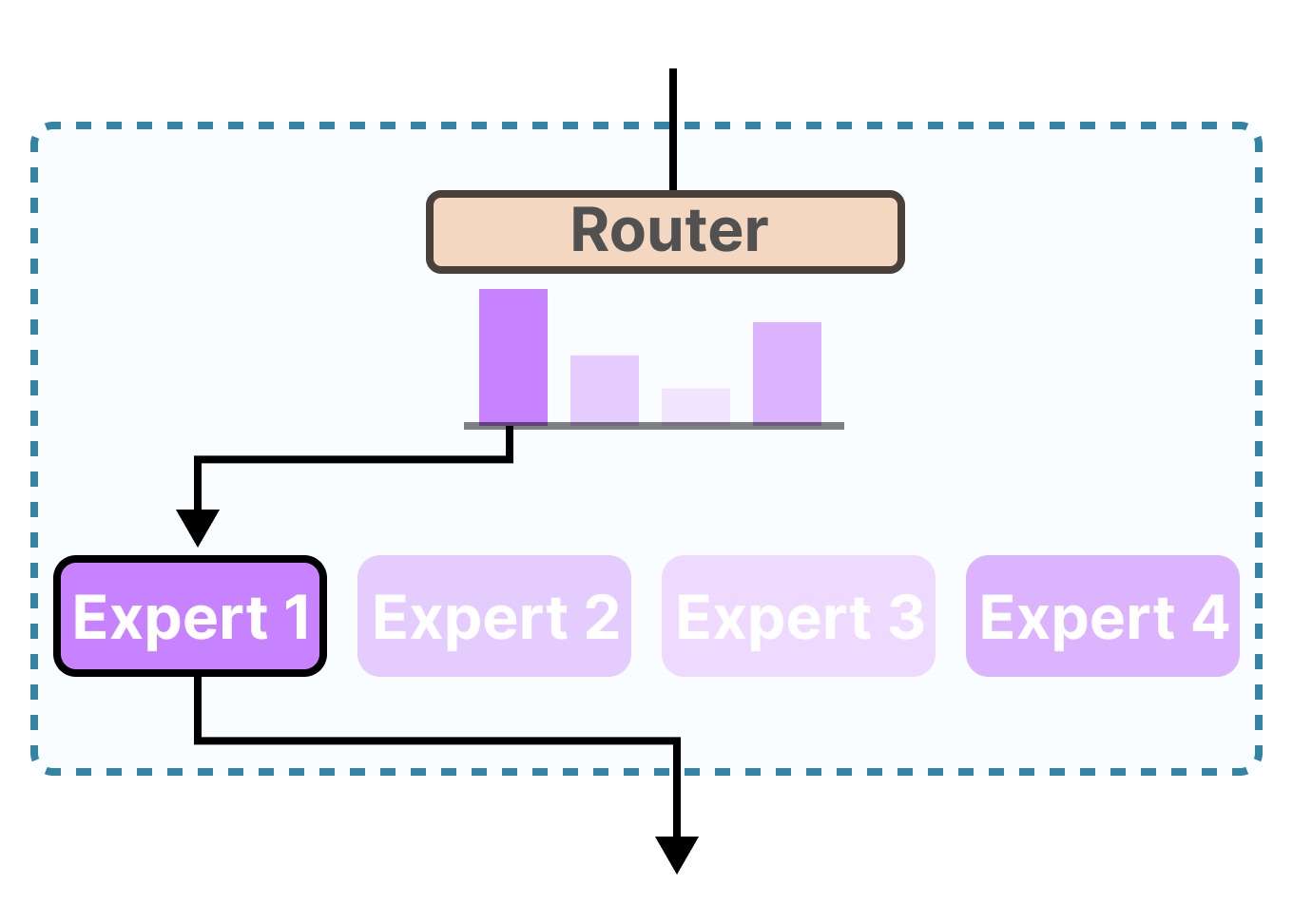
Mixture of Experts hoạt động dựa trên cơ chế chọn lọc chuyên gia, với 2 thành phần chính sau:
- Các chuyên gia (Experts): Là những mạng con được huấn luyện để xử lý một phần hoặc một khía cạnh nhất định của dữ liệu. Mỗi chuyên gia đảm nhận một vai trò riêng, ví dụ như phân tích ngữ nghĩa, nhận dạng hình ảnh hay suy luận ngữ cảnh.
- Mạng định tuyến (Gating Network): Đóng vai trò người điều phối, xác định chuyên gia nào nên được kích hoạt dựa trên đặc điểm của đầu vào.
Quy trình hoạt động của Mixture of Experts
Quy trình hoạt động của Mixture of Experts bao gồm các bước cơ bản như sau:
- Phân tách nhiệm vụ: Khi dữ liệu đầu vào được đưa vào hệ thống, mạng định tuyến sẽ đánh giá và chọn ra một hoặc vài chuyên gia có khả năng xử lý tốt nhất.
- Kích hoạt chọn lọc: Chỉ những chuyên gia được chọn mới hoạt động, thay vì huy động toàn bộ mạng như trong mô hình truyền thống.
- Kết hợp kết quả: Đầu ra của các chuyên gia được tổng hợp có trọng số để tạo ra kết quả cuối cùng.
Ưu nhược điểm của Mixture of Experts
Ở Mixture of Experts có một số ưu nhược điểm cơ bản mà bạn cần lưu ý khi ứng dụng:
Ưu điểm
Mixture of Experts sở hữu một số thế mạnh như:
- Hiệu suất vượt trội: MoE chỉ kích hoạt các chuyên gia liên quan đến từng tác vụ, giúp giảm chi phí tính toán, tiết kiệm tài nguyên và tăng tốc độ xử lý.
- Tính linh hoạt cao: Nhờ cấu trúc gồm nhiều chuyên gia độc lập, MoE có thể thích ứng tốt với nhiều loại dữ liệu và nhiệm vụ khác nhau.
- Khả năng mở rộng tốt: Mô hình dễ dàng mở rộng bằng cách thêm hoặc tinh chỉnh các chuyên gia mới mà không cần huấn luyện lại toàn bộ hệ thống.
- Chịu lỗi hiệu quả: Nếu một chuyên gia gặp lỗi, các chuyên gia khác vẫn có thể đảm nhận xử lý, đảm bảo kết quả đầu ra ổn định.
Nhược điểm
Mặc dù được đánh giá cao về hiệu suất, Mixture of Experts cũng còn tồn tại một số nhược điểm như:
- Huấn luyện phức tạp: Việc đồng bộ hàng chục hoặc hàng trăm chuyên gia cùng mạng định tuyến yêu cầu tài nguyên lớn và kỹ thuật tối ưu cao.
- Nguy cơ quá chuyên biệt: Một số chuyên gia có thể bị giới hạn trong phạm vi dữ liệu hẹp, dẫn đến hiện tượng overfitting (quá khớp) và giảm khả năng tổng quát hóa.
- Độ trễ trong suy luận: Quá trình định tuyến và chọn chuyên gia làm tăng độ phức tạp, gây chậm trễ trong một số tác vụ thời gian thực.
- Khó diễn giải: Cấu trúc đa tầng khiến việc hiểu rõ cách các chuyên gia và cơ chế định tuyến hoạt động trở nên khó khăn, gây khó trong kiểm thử và bảo trì.

Ứng dụng của Mixture of Experts (MoE)
Nhờ khả năng khả năng xử lý linh hoạt, Mixture of Experts được ứng dụng rộng rãi trong nhiều lĩnh vực trí tuệ nhân tạo hiện nay:
Xử lý ngôn ngữ tự nhiên (NLP)
MoE giúp huấn luyện các mô hình ngôn ngữ lớn (Large language model - LLM) nhanh và hiệu quả hơn bằng cách chỉ kích hoạt một phần mạng nơ-ron thay vì toàn bộ hệ thống. Qua đó, mô hình giúp tăng hiệu quả xử lý các tác vụ phức tạp trong lĩnh vực Xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP).
Ví dụ: GLaM đã sử dụng 1,2 nghìn tỷ tham số nhưng chỉ yêu cầu lượng tính toán tương đương với mô hình có 32 tỷ tham số. Điều này giúp giảm chi phí huấn luyện tổng thể trong khi vẫn duy trì được hiệu suất cao trên 29 tác vụ Xử lý ngôn ngữ tự nhiên.

Thị giác máy tính (Computer Vision)
Nhiều đơn vị đã triển khai Vision MoE (V-MoE) - kiến trúc dựa trên Vision Transformer để xử lý hình ảnh. Mô hình chia ảnh thành các mảnh nhỏ (patches), sau đó định tuyến đến chuyên gia phù hợp cho từng phần, giúp tăng độ chính xác và tối ưu hóa hiệu năng. Cách tiếp cận này còn linh hoạt khi có thể điều chỉnh số lượng chuyên gia được kích hoạt, tiết kiệm tài nguyên mà không cần huấn luyện lại mô hình.
Ví dụ: Microsoft đã giới thiệu mô hình DeepSpeed MoE cho việc phân loại hình ảnh quy mô lớn. Mô hình này cho thấy khả năng huấn luyện các mô hình thị giác có nhiều chuyên gia hơn so với các phương pháp trước đây, tăng hiệu quả khai thác GPU và hiệu suất xử lý.
Hệ thống gợi ý (Recommendation Systems)
Trong hệ thống đề xuất quy mô lớn (ví dụ quảng cáo, nội dung), MoE được triển khai dưới dạng MMoE (Multi-gate Mixture of Experts). Mô hình chia mục tiêu thành hai nhóm: tương tác và hài lòng để dự đoán hành vi người dùng dựa trên dữ liệu liên quan, ví dụ như: ngữ cảnh và đặc điểm cá nhân. Nhờ đó, hệ thống có thể cá nhân hóa đề xuất hiệu quả hơn mà vẫn đảm bảo tốc độ xử lý lớn.
Ví dụ: Google đã áp dụng MMoE trong các hệ thống gợi ý của mình để dự đoán sự tương tác (engagement) và mức độ hài lòng của người dùng trong dài hạn.

Thách thức và tương lai của Mixture of Experts
Trong quá trình triển khai Mixture of Experts bạn sẽ phải đối mặt với nhiều thách thức như:
Yêu cầu hạ tầng và bộ nhớ lớn
Một trong những thách thức lớn nhất của Mixture of Experts là nhu cầu bộ nhớ (VRAM) khổng lồ trong quá trình vận hành. Dù chỉ một số chuyên gia được kích hoạt cho mỗi lần suy luận, toàn bộ mạng chuyên gia vẫn phải được tải lên bộ nhớ GPU. Điều này khiến chi phí triển khai và bảo trì hệ thống trở nên đắt đỏ, đòi hỏi cụm GPU phân tán quy mô lớn.

Cân bằng tải giữa các chuyên gia
Cơ chế định tuyến (gating) cần đảm bảo việc phân bổ nhiệm vụ đồng đều giữa các chuyên gia. Tuy nhiên, trên thực tế, một số chuyên gia có thể bị kích hoạt quá mức trong khi những chuyên gia khác hầu như không được sử dụng. Sự mất cân bằng này gây quá tải cục bộ, làm chậm hiệu suất tổng thể và lãng phí tài nguyên.
Phức tạp trong huấn luyện và tinh chỉnh (Fine-tuning)
Huấn luyện MoE phức tạp hơn nhiều so với mô hình đơn khối do phải điều phối đồng thời giữa các chuyên gia và mạng gating. Việc tối ưu hóa hàm mất mát, chọn siêu tham số, hoặc điều chỉnh tốc độ học đều đều cần những chiến lược tinh vi để đảm bảo sự cân bằng và ổn định trong quá trình học. Chỉ một sai sót nhỏ cũng có thể khiến các chuyên gia không đạt được mức chuyên biệt hóa mong muốn, làm suy giảm đáng kể hiệu suất tổng thể của mô hình.

Hiệu quả suy luận và khả năng song song hóa
Trong giai đoạn suy luận, mô hình cần kích hoạt mạng gating để chọn chuyên gia phù hợp cho từng đầu vào. Quá trình này làm tăng độ trễ xử lý và tiêu tốn tài nguyên bổ sung. Ngoài ra, việc chạy song song nhiều chuyên gia yêu cầu hệ thống phân luồng và quản lý tài nguyên cực kỳ hiệu quả - điều không dễ đạt được trong môi trường tính toán giới hạn.
Giới hạn trong khả năng diễn giải và kiểm soát
Cấu trúc nhiều lớp của MoE khiến việc hiểu rõ cách mô hình đưa ra quyết định trở nên khó khăn. Người phân tích không chỉ cần xem xét đầu ra của từng chuyên gia, mà còn phải hiểu được cơ chế phân bổ của mạng gating. Điều này làm tăng độ mờ trong quá trình giám sát và kiểm chứng mô hình.
Tạm kết
Tóm lại, Mixture of Experts (MoE) là một bước tiến cách mạng, cho phép mô hình tăng trưởng quy mô tham số lên mức chưa từng có mà vẫn duy trì hiệu quả tính toán cao. Tuy nhiên, để khai thác triệt để, bạn cần lưu ý các thách thức về yêu cầu hạ tầng, khả năng tinh chỉnh và độ phức tạp trong cân bằng tải khi triển khai. Vượt qua những rào cản này, MoE sẽ dần trở nên hoàn thiện hơn, trở thành kiến trúc xương sống cho các dự án phát triển Trí tuệ nhân tạo trong tương lai.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá