
Multi-head Attention là gì? Cơ chế hoạt động, ưu nhược điểm và ứng dụng

 21/11/2025
21/11/2025
Multi-head Attention là giải pháp then chốt giúp các mô hình AI hiện đại đạt hiệu quả cao bằng cách cho các mô hình học các đặc trưng phức tạp và đa chiều từ dữ liệu.
Trong lĩnh vực trí tuệ nhân tạo, kiến trúc Transformer được xem là một bước ngoặt quan trọng, mở ra khả năng xử lý dữ liệu hiệu quả và chính xác hơn. Một trong những yếu tố then chốt tạo nên sức mạnh của Transformer chính là Multi-head Attention. Cơ chế Multi-head Attention cho phép mô hình đồng thời tập trung vào nhiều khía cạnh khác nhau của dữ liệu đầu vào. Nhờ đó, mô hình nâng cao khả năng hiểu ngữ cảnh và cải thiện hiệu suất trên nhiều tác vụ khác nhau. Hãy cùng VNPT AI tìm hiểu Multi-head Attention là gì và cơ chế hoạt động trong bài viết dưới đây.
Multi-head Attention là gì?
Multi-head Attention là một cơ chế cốt lõi trong kiến trúc Transformer, giúp mô hình học và nắm bắt các mối quan hệ phức tạp giữa các phần tử trong chuỗi dữ liệu đầu vào. Cơ chế này mở rộng từ khái niệm self-attention bằng cách sử dụng nhiều "head" attention song song thay vì chỉ một. Mỗi head thực hiện quá trình tính toán attention riêng biệt, bao gồm việc tạo ra ba vector Query (Q), Key (K) và Value (V) từ đầu vào, sau đó tính toán mức độ quan trọng của từng phần tử thông qua cơ chế Scaled Dot-Product Attention.
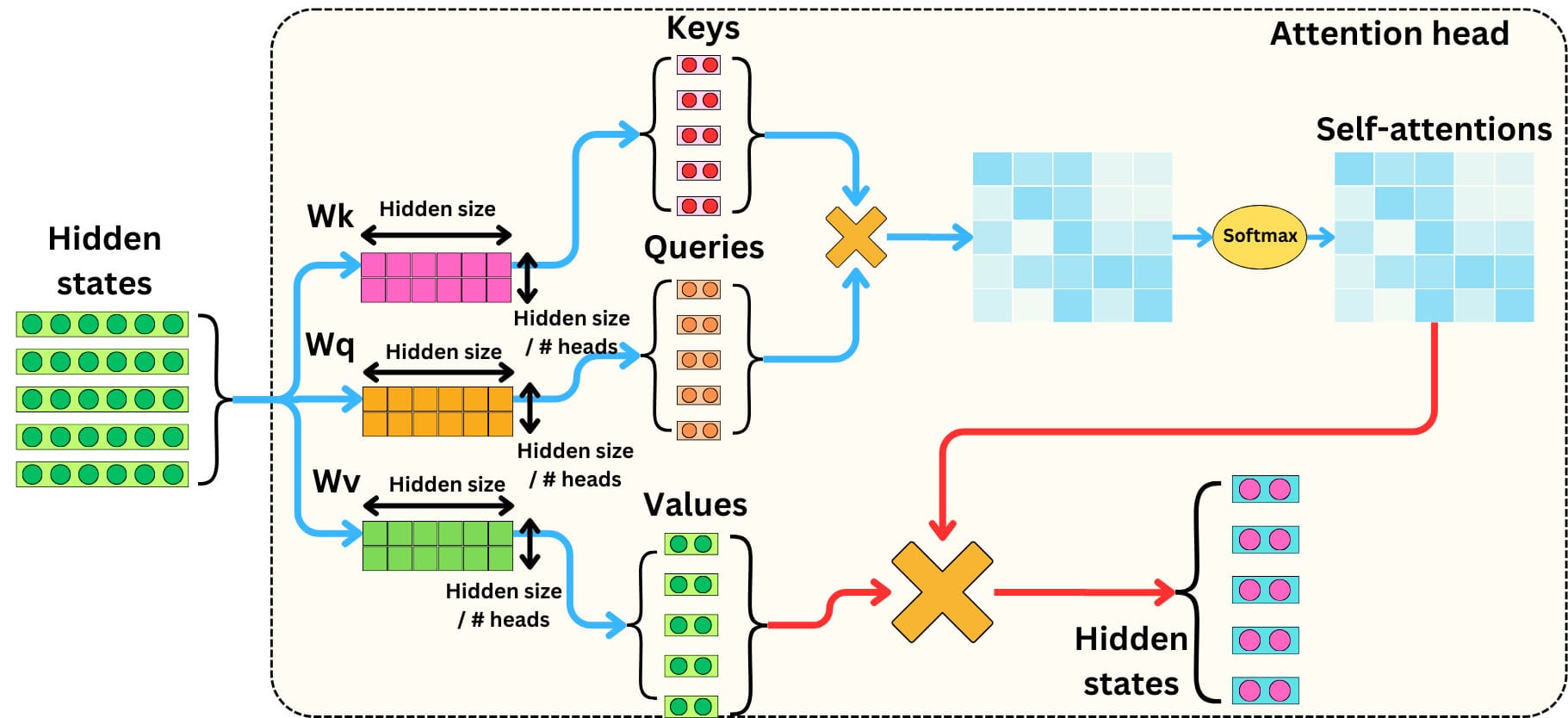
Các kết quả này được kết hợp lại và biến đổi tuyến tính để tạo thành đầu ra cuối cùng. Nhờ cách tiếp cận này, Multi-head Attention cho phép mô hình học được nhiều kiểu quan hệ khác nhau giữa các từ hoặc token, chẳng hạn như mối quan hệ gần, xa hay sự phụ thuộc ngữ cảnh. Điều này không chỉ giúp cải thiện khả năng biểu diễn ngữ cảnh mà còn hỗ trợ huấn luyện ổn định hơn, giảm nguy cơ bỏ sót thông tin và tối ưu hóa khả năng học.
Cơ chế hoạt động của Multi-head Attention
Multi-head Attention hoạt động thông qua một chuỗi bước liên kết, giúp mô hình xử lý và học được các mối quan hệ phức tạp trong dữ liệu đầu vào.
- Bước 1: Đầu vào được biến đổi tuyến tính thành ba ma trận Query (Q), Key (K) và Value (V); mỗi "head" attention sử dụng một tập trọng số riêng để thực hiện bước này.
- Bước 2: Mỗi head áp dụng cơ chế Scaled Dot-Product Attention, trong đó mức độ liên quan giữa các phần tử được tính bằng tích chấm giữa Q và K, sau đó chia cho căn bậc hai của kích thước Key nhằm ổn định quá trình huấn luyện.
- Bước 3: Kết quả này được chuẩn hóa bằng hàm Softmax, tạo ra các trọng số attention (attention weights). Những trọng số này được sử dụng để tính tổng có trọng số của V, từ đó làm nổi bật những thông tin quan trọng nhất trong chuỗi.
- Bước 4: Các đầu ra từ tất cả các head được nối lại và tiếp tục biến đổi tuyến tính để tạo thành đầu ra cuối cùng của Multi-head Attention.
Ưu nhược điểm của Multi-head Attention
Multi-head Attention mang lại nhiều lợi ích, giúp mô hình hoạt động hiệu quả và linh hoạt khi xử lý dữ liệu tuần tự:
- Khả năng học quan hệ đa chiều giữa các từ: Multi-head Attention giúp mô hình khám phá nhiều kiểu quan hệ phức tạp trong câu, từ liên kết ngữ pháp đến ý nghĩa ngữ cảnh.
- Hỗ trợ xử lý song song, cải thiện hiệu suất huấn luyện: Nhờ cơ chế chia nhỏ thành nhiều head, các phép tính attention có thể thực hiện đồng thời, rút ngắn thời gian training.
- Tăng khả năng khái quát hóa: Mô hình có thể học được các mẫu phụ thuộc đa dạng, từ đó áp dụng hiệu quả trên những dữ liệu mới chưa từng thấy trước đó.
Bên cạnh đó, Multi-head Attention cũng tồn tại một số hạn chế như:
- Độ phức tạp tính toán cao: Multi-head Attention có độ phức tạp bậc hai theo độ dài chuỗi, khiến quá trình xử lý trở nên chậm khi làm việc với các sequence dài.
- Tiêu tốn nhiều bộ nhớ: Cơ chế này yêu cầu nhiều phép biến đổi và lưu trữ cho các ma trận Q, K, V của từng head, dẫn đến mức sử dụng tài nguyên lớn hơn so với các dạng attention đơn giản.
- Khó diễn giải: Việc hiểu rõ mỗi attention head tập trung vào yếu tố nào trong chuỗi là một thách thức, khiến quá trình trực quan hóa và phân tích kết quả trở nên phức tạp.
Multi-head Attention và Self Attention khác nhau như thế nào?

Multi-head Attention và Self Attention có mối quan hệ chặt chẽ nhưng không hoàn toàn giống nhau. Hai cơ chế này có các điểm khác nhau như:
Multi-head Attention | Self-attention | |
| Khái niệm | Là sự mở rộng của self-attention, trong đó nhiều self-attention (head) được thực hiện song song, mỗi head học một kiểu quan hệ khác nhau, sau đó kết quả được kết hợp lại. | Là cơ chế attention trong đó Query (Q), Key (K) và Value (V) đều được lấy từ cùng một nguồn (chính chuỗi đầu vào). Nó giúp mô hình xác định mối quan hệ giữa các phần tử trong cùng một chuỗi. |
| Phạm vi áp dụng | Thường bao gồm nhiều self-attention head nhưng cũng có thể áp dụng cho cross-attention (Query khác nguồn với Key/Value). | Có thể được dùng riêng lẻ (như trong Encoder hoặc Decoder của Transformer). |
| Khả năng biểu diễn | Cho phép học nhiều quan hệ ngữ cảnh cùng lúc, giúp mô hình nắm bắt thông tin toàn diện hơn. | Chỉ học được một kiểu quan hệ tại một thời điểm, hạn chế khả năng biểu diễn. |
| Chi phí tính toán | Tốn nhiều tài nguyên hơn do tính toán đồng thời trên nhiều head. | Ít tốn tài nguyên hơn vì chỉ có một head. |
Ứng dụng của Multi-head Attention
Multi-head Attention được ứng dụng rộng rãi trong nhiều lĩnh vực như:
- Xử lý ngôn ngữ tự nhiên (NLP): cơ chế này được ứng dụng rộng rãi trong dịch máy như Google Translate, tóm tắt văn bản, hay các hệ thống Chatbot và AI hội thoại.
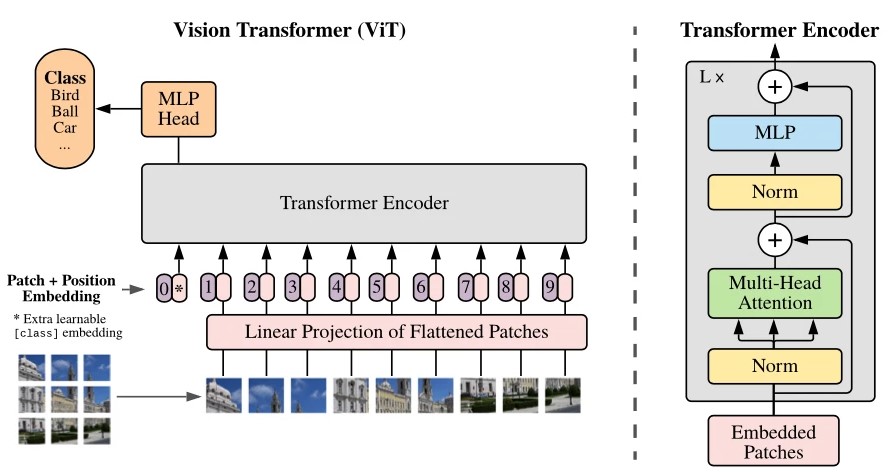
- Thị giác máy tính (Computer Vision): Multi-head Attention đóng vai trò nền tảng trong các Vision Transformer (ViT) để nhận diện và phân tích hình ảnh.
- Xử lý giọng nói: cơ chế này giúp cải thiện độ chính xác của các mô hình chuyển giọng nói thành văn bản, chẳng hạn như Whisper của OpenAI. Nhờ khả năng học biểu diễn tốt hơn và hiểu ngữ cảnh sâu hơn, Multi-head Attention đã góp phần nâng cao hiệu suất trên nhiều tác vụ khác nhau, từ văn bản, hình ảnh đến âm thanh.
Tạm kết
Như vậy, bài viết của VNPT AI đã giúp bạn đọc nắm những thông tin cơ bản về Multi-head Attention. Nhờ khả năng học nhiều mối quan hệ song song, nắm bắt ngữ cảnh đa chiều và cải thiện hiệu suất trên nhiều loại dữ liệu, cơ chế này không chỉ đóng vai trò cốt lõi trong Transformer mà còn mở ra nhiều hướng ứng dụng tiềm năng trong xử lý ngôn ngữ tự nhiên, thị giác máy tính và xử lý giọng nói. Trong tương lai, Multi-head Attention hứa hẹn sẽ tiếp tục được tối ưu để tăng tốc độ, giảm chi phí tính toán và được ứng dụng xử lý nhiều bài toán phức tạp hơn.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá