
Data Transformation là gì? Bí quyết khai phá tối đa sức mạnh dữ liệu

 23/06/2025
23/06/2025
Data Transformation là bước thiết yếu trong quy trình quản lý và xử lý dữ liệu, giúp doanh nghiệp khai thác dữ liệu hiệu quả hơn trong phân tích, báo cáo và ra quyết định
Trong kỷ nguyên dữ liệu số, việc thu thập thông tin chỉ là bước khởi đầu. Bởi điều quan trọng hơn cả là làm thế nào để xử lý và chuyển đổi những dữ liệu đó thành nguồn tài nguyên có giá trị. Đây cũng chính là lý do cho sự ra đời của Data Transformation (chuyển đổi dữ liệu). Vậy Data Transformation là gì? Quá trình chuyển đổi dữ liệu diễn ra với các bước như thế nào? Hãy cùng VNPT AI đi khám phá chi tiết trong bài viết dưới đây!
Data Transformation là gì?
Data Transformation (Chuyển đổi dữ liệu) là quá trình chuyển đổi, làm sạch và chuẩn hóa dữ liệu nhằm đảm bảo tính nhất quán, phù hợp với hệ thống đích và sẵn sàng cho quá trình phân tích. Đây là bước quan trọng trong ETL (Extract - Transform - Load) và ELT (Extract - Load - Transform), có nhiệm vụ tối ưu hóa dữ liệu để phục vụ các ứng dụng như thiết lập kho dữ liệu, phân tích kinh doanh và đào tạo mô hình trí tuệ nhân tạo.

Nhờ Data Transformation, doanh nghiệp có thể tích hợp thông tin từ nhiều nguồn khác nhau, nâng cao chất lượng và độ chính xác của dữ liệu, qua đó hỗ trợ ra quyết định nhanh chóng và chuẩn xác dựa trên dữ liệu đã được tối ưu và phân tích chuyên sâu.
>>> Đọc thêm: Data Intergration là gì? Quy trình và ứng dụng của tích hợp dữ liệu
Các loại Data Transformation phổ biến
Data Transformation được phát triển dưới nhiều dạng khác nhau, tùy biến để đáp ứng các mục tiêu sử dụng cụ thể. Vậy các kỹ thuật Data Transformation là gì? Dưới đây là các loại phổ biến:
- Làm sạch và lọc dữ liệu (Data Cleaning & Filtering): Dữ liệu nguồn đa phần thường chứa lỗi, trùng lặp hoặc bị thiếu thông tin. Do đó, quá trình làm sạch cần được thực hiện để loại bỏ các bản ghi dư thừa, xử lý giá trị bị thiếu bằng cách thay thế (imputation) hoặc loại bỏ hoàn toàn. Nhờ đó, dữ liệu trở nên sạch hơn, nhất quán và sẵn sàng cho các bước xử lý tiếp theo.
- Chuẩn hóa dữ liệu (Data Normalization): Chuẩn hóa giúp đưa dữ liệu về cùng một quy chuẩn, ví dụ như điều chỉnh tất cả giá trị số về cùng một khoảng (0 đến 1 hoặc -1 đến 1) hoặc đảm bảo định dạng ngày tháng đồng nhất (M/D/Y hoặc D/M/Y). Đây là một bước quan trọng để cải thiện hiệu suất của các mô hình học máy và phân tích dữ liệu về sau.
- Tổng hợp dữ liệu (Data Aggregation): Khi làm việc với tập dữ liệu lớn, việc tổng hợp sẽ giúp đơn giản hóa và tóm tắt thông tin tối ưu hơn. Ví dụ, thay vì lưu dữ liệu theo từng ngày, ta có thể tổng hợp thành dữ liệu theo tuần hoặc tháng để dễ dàng phân tích hơn.
- Mã hóa dữ liệu (Data Encoding): Dữ liệu dạng văn bản hoặc danh mục cần được chuyển đổi sang dạng số để có thể sử dụng trong các thuật toán. Và để làm được điều này, người ta thường sử dụng một số phương pháp mã hóa phổ biến như One-Hot Encoding, Label Encoding hoặc Ordinal Encoding,...
- Phân nhóm và rời rạc hóa dữ liệu (Data Discretization & Binning): Dữ liệu liên tục có thể được chia thành các nhóm rời rạc để dễ phân tích hơn. Ví dụ, thay vì sử dụng tuổi cụ thể của từng khách hàng, ta có thể phân nhóm theo độ tuổi như "Thanh thiếu niên", "Trung niên" và "Người cao tuổi".
- Làm giàu dữ liệu (Data Enrichment): Dữ liệu có thể được mở rộng bằng cách bổ sung thông tin từ các nguồn bên ngoài. Chẳng hạn, tập dữ liệu khách hàng có thể được “làm giàu” bằng cách thêm thông tin nhân khẩu học từ nhiều nguồn khác.
- Thay đổi định dạng dữ liệu (Format Conversion): Việc chuyển đổi dữ liệu giữa các định dạng khác nhau giúp đảm bảo khả năng tương thích giữa các hệ thống. Ví dụ, chuyển đổi tệp CSV sang JSON, hoặc thay đổi mã hóa ký tự để đảm bảo hiển thị chính xác.
- Biến đổi logarit và Power Transform: Khi dữ liệu có phân phối lệch, áp dụng phép biến đổi logarit hoặc các kỹ thuật như Box-Cox, Yeo-Johnson sẽ giúp đưa dữ liệu về phân phối chuẩn, qua đó cải thiện hiệu suất phân tích thống kê và mô hình học máy (machine learning).
- Tạo thuộc tính mới (Feature Engineering): Khai thác thông tin từ dữ liệu hiện có để tạo ra các thuộc tính mới giúp nâng cao hiệu suất mô hình. Ví dụ, từ dữ liệu giao dịch, ta có thể tính toán số lần mua hàng trung bình hay chi tiêu trung bình mỗi tháng để tạo thêm một biến đầu vào hữu ích.
- Trực quan hóa dữ liệu (Data Visualization): Biểu diễn dữ liệu dưới dạng đồ thị giúp phát hiện xu hướng, nhận biết điểm bất thường hoặc mô hình hóa các biến đổi, điều mà các số liệu “thô” khó thể hiện rõ ràng.
Quy trình thực hiện chuyển đổi dữ liệu
Chuyển đổi dữ liệu được thực hiện qua nhiều bước, trong đó mỗi giai đoạn lại đóng vai trò khác nhau đảm bảo dữ liệu được xử lý chính xác và hiệu quả, như sau:
Bước 1: Khám phá và phân tích dữ liệu (Data Discovery & Profiling)
Bước đầu tiên trong quy trình Data Transformation là xác định và thu thập dữ liệu nguồn. Dữ liệu có thể đến từ nhiều nguồn khác nhau, bao gồm cơ sở dữ liệu SQL, API, tệp nội bộ hoặc luồng dữ liệu thời gian thực,.... Trong quá trình này, chuyên gia dữ liệu sẽ tiến hành phân tích cấu trúc và đặc điểm của dữ liệu, qua đó giúp nhận diện các vấn đề tiềm ẩn như dữ liệu thiếu, lỗi định dạng hoặc dữ liệu không đồng nhất.
Bước 2: Làm sạch và kiểm tra chất lượng dữ liệu trước khi xử lý (Data Cleaning & Preprocessing)
Sau khi dữ liệu được thu thập, quá trình làm sạch sẽ được tiến hành để loại bỏ các lỗi, đảm bảo các bước tiếp theo diễn ra suôn sẻ và giảm thiểu sai sót trong quá trình phân tích. Cụ thể, có một số lỗi phổ biến sau:
- Giá trị trùng lặp (Duplicate Values): Xóa bỏ các bản ghi trùng lặp để tránh làm sai lệch kết quả phân tích.
- Giá trị bị thiếu (Missing Values): Áp dụng kỹ thuật thay thế (imputation) hoặc loại bỏ dữ liệu không hợp lệ.
- Xử lý ngoại lệ (Outliers Handling): Xác định và điều chỉnh các giá trị bất thường để đảm bảo tính toàn vẹn của dữ liệu.

Bước 3: Ánh xạ và chuyển đổi dữ liệu (Data Mapping & Transformation)
Trong giai đoạn này, các chuyên gia dữ liệu sẽ phân tích sâu để thiết lập mối quan hệ giữa dữ liệu nguồn và dữ liệu đích bằng cách xây dựng sơ đồ ánh xạ (schema mapping), đảm bảo dữ liệu có cấu trúc rõ ràng, dễ tích hợp và sử dụng trong các hệ thống dữ liệu lớn. Các phép biến đổi bao gồm:
- Chuẩn hóa dữ liệu (Normalization): Đưa dữ liệu về cùng một quy chuẩn, giúp tăng tính nhất quán.
- Tổng hợp dữ liệu (Aggregation): Tóm tắt dữ liệu từ mức độ chi tiết cao xuống các cấp độ tổng quan hơn.
- Mã hóa dữ liệu (Encoding): Chuyển đổi dữ liệu danh mục sang dạng số để phục vụ phân tích và mô hình học máy.
Bước 4: Xây dựng mã chuyển đổi dữ liệu (Code Generation)
Sau khi hoàn tất giai đoạn ánh xạ dữ liệu, quá trình sinh mã sẽ được thực hiện. Trong đó, có các công cụ chuyên biệt như ETL hoặc viết mã tùy chỉnh bằng các ngôn ngữ lập trình như Python, SQL, Spark có thể được sử dụng.
Bước 5: Thực thi chuyển đổi dữ liệu (Execution & Data Loading)
Tại bước này, mã chuyển đổi sẽ được thực thi, trong đó dữ liệu gốc được biến đổi theo các quy tắc đã thiết lập từ trước, sau đó được tải lên hệ thống đích như Data Warehouse hoặc Data Lake.
Cụ thể, trong các hệ thống truyền thống, mô hình ETL được sử dụng khá phổ biến. Tuy nhiên, với sự phát triển của điện toán đám mây, phương pháp ELT ngày càng được ưa chuộng hơn, cho phép chuyển đổi dữ liệu ngay khi cần sử dụng.
Bước 6: Kiểm tra và đánh giá chất lượng dữ liệu (Validation & Review)
Sau khi dữ liệu được chuyển đổi và tải vào hệ thống, quá trình đánh giá chất lượng tiếp tục được tiến hành, bằng cách:
- Xác thực tính toàn vẹn: Kiểm tra xem dữ liệu có bị mất mát hoặc bị thay đổi ngoài ý muốn không.
- So sánh với dữ liệu nguồn: Đối chiếu dữ liệu đầu vào và đầu ra để đảm bảo tính nhất quán.
- Đánh giá độ chính xác: Kiểm tra xem dữ liệu sau khi chuyển đổi có đáp ứng yêu cầu kinh doanh và kỹ thuật không.
Nếu phát hiện sai sót, chuyên gia dữ liệu sẽ thực hiện điều chỉnh, đảm bảo rằng dữ liệu đầu ra hoàn toàn đáp ứng tiêu chuẩn.
Lợi ích và thách thức khi triển khai Data Transformation
Như bất kỳ công nghệ hay kỹ thuật tiên tiến nào, Data Transformation cũng sở hữu những lợi thế và thách thức riêng. Vậy cụ thể lợi ích và thách thức của Data Transformation là gì?
Lợi ích
Lợi ích của Data Transformation là điều không thể phủ nhận, có thể thấy rất rõ trong các khía cạnh như:
- Cải thiện chất lượng dữ liệu: Quá trình Data Transformation giúp chuẩn hóa và làm sạch dữ liệu, loại bỏ các giá trị trùng lặp, xử lý dữ liệu bị thiếu và đảm bảo tính toàn vẹn của dữ liệu. Khi dữ liệu có chất lượng cao, các hệ thống phân tích và dự đoán sẽ hoạt động chính xác hơn, đồng thời giúp doanh nghiệp giảm thiểu sai sót trong báo cáo và ra quyết định.
- Tăng khả năng tương thích và tích hợp dữ liệu: Dữ liệu thu thập từ nhiều nguồn thường có cấu trúc khác nhau, gây ra khó khăn không nhỏ trong việc tích hợp. Data Transformation giúp chuẩn hóa định dạng dữ liệu, đồng bộ cấu trúc và đơn vị đo lường, nhờ vậy hệ thống có thể dễ dàng hợp nhất dữ liệu từ nhiều nguồn khác nhau. Điều này được cho là đặc biệt hữu ích đối với các tổ chức sử dụng nhiều nền tảng khác nhau như cơ sở dữ liệu SQL, hệ thống ERP, CRM hoặc các dịch vụ đám mây.

- Tối ưu hóa khả năng truy xuất và khai thác dữ liệu: Sau khi được chuyển đổi, dữ liệu sẽ có cấu trúc rõ ràng hơn, giúp tăng tốc độ truy xuất và giảm thời gian xử lý. Việc chuẩn hóa dữ liệu cũng giúp người dùng cuối dễ dàng tìm kiếm, truy vấn và khai thác thông tin mà không cần sự can thiệp của bộ phận IT.
- Hỗ trợ phân tích dữ liệu và ra quyết định: Dữ liệu sau khi được chuyển đổi có thể khai thác và sử dụng dễ dàng cho các công cụ như BI (Business Intelligence) hoặc phân tích dữ liệu nâng cao. Việc chuẩn hóa dữ liệu đồng thời cùng giúp các mô hình phân tích hoạt động chính xác hơn, cung cấp thông tin chi tiết về hiệu suất kinh doanh, xu hướng thị trường và hành vi khách hàng. Nhờ đó, doanh nghiệp có thể đưa ra quyết định dựa trên dữ liệu thay vì chỉ hành động cảm tính.
- Cải thiện bảo mật, đảm bảo tuân thủ các quy định hiện hành: Data Transformation cũng bao gồm các biện pháp như mã hóa, ẩn danh dữ liệu và kiểm soát truy cập, nhờ vậy giúp bảo vệ thông tin nhạy cảm tối ưu hơn. Điều này đặc biệt hữu ích đối với các ngành chịu sự quản lý chặt chẽ như tài chính, y tế và thương mại điện tử - nơi việc tuân thủ các tiêu chuẩn bảo mật như GDPR, HIPAA là điều bắt buộc.
- Tăng khả năng mở rộng và linh hoạt: Dữ liệu được chuẩn hóa và tổ chức tốt sẽ giúp doanh nghiệp chủ động hơn trong các tình huống thực tế. Cụ thể, khi doanh nghiệp có định hướng mở rộng về quy mô, lượng dữ liệu cũng đồng thời gia tăng nhanh chóng, đòi hỏi hệ thống phải có khả năng mở rộng linh hoạt. Lúc này, Data Transformation chính là chìa khóa giúp giải quyết vấn đề, đảm nhiệm tối ưu hóa việc lưu trữ và xử lý dữ liệu, giúp tổ chức nhanh chóng thích nghi với sự thay đổi của môi trường kinh doanh.
Thách thức
Song song với những lợi ích đem lại, chuyển đổi dữ liệu cũng phải đối mặt với những thách thức nhất định. Vậy thách thức của Data Transformation là gì?
- Chi phí triển khai cao: Việc xây dựng hệ thống Data Transformation đòi hỏi sự đầu tư rất lớn vào hạ tầng, phần mềm và phát triển nhân sự. Các tổ chức cần mua sắm công cụ ETL hoặc nền tảng ELT hiện đại, đồng thời thuê chuyên gia dữ liệu để thiết lập và giám sát quá trình. Chi phí này có thể trở thành thách thức lớn cho các doanh nghiệp vừa và nhỏ.
- Rủi ro lỗi và không nhất quán dữ liệu: Nếu không có quy trình quản lý chặt chẽ, việc chuyển đổi dữ liệu có thể gây lỗi, làm sai lệch thông tin và ảnh hưởng đến các báo cáo quan trọng. Ví dụ, lỗi trong quá trình ánh xạ dữ liệu có thể dẫn đến mất dữ liệu hoặc dữ liệu bị chuyển đổi sai lệch. Điều này đòi hỏi phải có các cơ chế kiểm tra, giám sát và xác thực dữ liệu sau khi chuyển đổi.
- Khó khăn trong tuyển dụng và duy trì nhân sự: Chuyển đổi dữ liệu đòi hỏi chuyên môn sâu về khoa học dữ liệu, kỹ thuật dữ liệu và quản trị hệ thống. Tuy nhiên, số lượng các chuyên gia trong lĩnh vực này có thể nói là rất khan hiếm và chi phí tuyển dụng thường khá cao, đi kèm là những phúc lợi đặc biệt khác. Đây có thể nói là một bài toán khó đối với các doanh nghiệp khi dự định triển khai mô hình Data Transformation.
- Yêu cầu tài nguyên lớn: Quá trình chuyển đổi dữ liệu thường tiêu tốn nhiều tài nguyên tính toán, đặc biệt khi xử lý dữ liệu lớn (Big Data). Nếu chỉ triển khai trên hệ thống tại chỗ (on-premises), vấn đề vẫn chưa thể được giải quyết hoàn toàn. Bởi việc chạy các tác vụ chuyển đổi có thể làm chậm hiệu suất của các hệ thống khác. Đồng thời, mặc dù điện toán đám mây đã được ứng dụng để giảm bớt nặng này, nhưng chi phí vận hành và mở rộng vẫn là điều đáng để suy ngẫm.

- Tính phức tạp khi làm việc với dữ liệu phi cấu trúc: Sự gia tăng của dữ liệu phi cấu trúc như văn bản, hình ảnh, video, cảm biến IoT khiến quá trình Data Transformation trở nên khó khăn hơn. Trong khi đó, các mô hình truyền thống thường chỉ phù hợp với dữ liệu có cấu trúc. Điều này đòi hỏi doanh nghiệp cần trang bị thêm các công cụ và phương pháp chuyên biệt để xử lý nguồn dữ liệu đa dạng hình thái này.
- Vấn đề bảo mật trong quá trình chuyển đổi dữ liệu: Dữ liệu trong quá trình chuyển đổi có thể dễ bị lộ hoặc tấn công nếu không có biện pháp bảo vệ thích hợp. Theo đó, các tổ chức cần triển khai áp dụng các phương pháp mã hóa riêng, giám sát truy cập, xác thực hai yếu tố để đảm bảo an toàn trong toàn bộ chu trình Data Transformation.
- Lựa chọn công cụ phù hợp: Thị trường có rất nhiều công cụ Data Transformation, từ các nền tảng mã nguồn mở như Apache Spark, Talend đến các giải pháp thương mại như Informatica, Microsoft Azure Data Factory. Thế nhưng, việc lựa chọn công cụ nào lại không phải điều dễ dàng. Doanh nghiệp cần cân nhắc nhiều yếu tố liên quan như: chi phí, khả năng mở rộng, tính dễ sử dụng và khả năng tích hợp với hệ thống hiện có,....
Ứng dụng của Data Transformation trong các lĩnh vực
Ngày này, khái niệm Data Transformation - Chuyển đổi dữ liệu là gì không còn quá xa lạ, bởi kỹ thuật này đã được khai thác và ứng dụng trong nhiều lĩnh vực đời sống như:
Kinh doanh thông minh (Business Intelligence - BI)
Trong lĩnh vực Business Intelligence, Data Transformation đóng vai trò quan trọng trong việc chuẩn hóa và làm sạch dữ liệu từ nhiều nguồn khác nhau, giúp tạo ra các báo cáo phân tích chính xác. Nhờ đó, doanh nghiệp có thể xây dựng các bảng điều khiển (dashboard) trực quan, cập nhật dữ liệu theo thời gian thực và đưa ra các quyết định dựa trên dữ liệu một cách hiệu quả.
Khoa học dữ liệu (Data Science) và học máy (Machine Learning)
Data Transformation là gì trong khoa học dữ liệu? Đây là quá trình giúp chuẩn bị dữ liệu một cách có hệ thống, với nhiều tác vụ quan trọng như: làm sạch dữ liệu, chuyển đổi định dạng, xử lý các giá trị thiếu. Dữ liệu đã qua chuyển đổi sẽ giúp các thuật toán Machine Learning hoạt động chính xác hơn, nâng cao độ tin cậy của mô hình phân tích và dự đoán.

Phân tích dữ liệu lớn (Big Data Analytics)
Trong thời đại số, khối lượng dữ liệu khổng lồ từ nhiều nguồn khác nhau đòi hỏi doanh nghiệp phải có hệ thống phân tích dữ liệu lớn để khai thác triệt để giá trị từ dữ liệu. Data Transformation giúp chuẩn hóa và tổ chức dữ liệu trước khi đưa vào phân tích, từ đó hỗ trợ các doanh nghiệp hiểu rõ xu hướng thị trường, hành vi khách hàng và đưa ra chiến lược kinh doanh phù hợp.
Quản lý quan hệ khách hàng (Customer Relationship Management - CRM)
Trong các hệ thống CRM, dữ liệu khách hàng thường đến từ nhiều nguồn như website, mạng xã hội, email và hệ thống bán hàng. Việc áp dụng Data Transformation giúp hợp nhất và làm sạch dữ liệu, qua đó cải thiện khả năng phân tích hành vi khách hàng, tối ưu hóa trải nghiệm cá nhân hóa và xây dựng chiến lược tiếp thị hiệu quả.
Ứng dụng trong Internet of Things (IoT)
Hệ sinh thái IoT bao gồm hàng loạt thiết bị thu thập dữ liệu theo thời gian thực, tạo ra một lượng dữ liệu tuy nhiên lại không đồng nhất và khá phức tạp để "hiểu". Nhờ Data Transformation, dữ liệu từ các thiết bị IoT có thể được xử lý, chuẩn hóa và chuyển đổi thành định dạng phù hợp để phân tích, giúp các doanh nghiệp khai thác thông tin hữu ích, tối ưu hóa vận hành và nâng cao hiệu suất hệ thống.
Lưu kho dữ liệu và di chuyển dữ liệu (Data Warehousing & Data Migration)
Data Transformation cũng đóng vai trò quan trọng trong quá trình lưu kho dữ liệu (Data Warehouse) và di chuyển dữ liệu (Data Migration). Trong đó, trước khi dữ liệu được lưu trữ trong kho hoặc chuyển sang nền tảng đám mây, chúng sẽ được chuyển đổi (Data Transformation) để đảm bảo tính tương thích và dễ dàng truy vấn. Điều này giúp doanh nghiệp tối ưu hóa việc lưu trữ và truy xuất dữ liệu một cách hiệu quả.
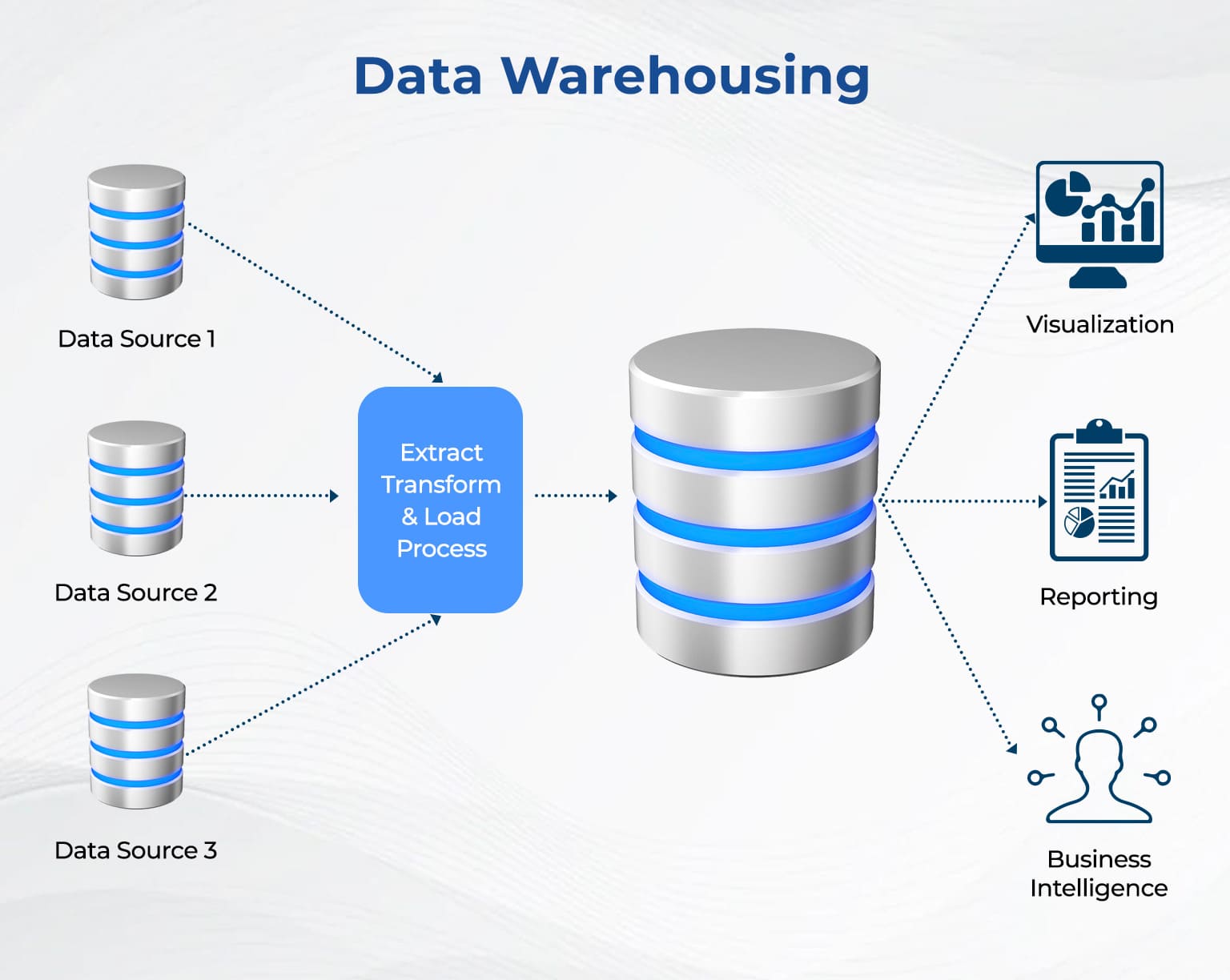
Các công cụ hỗ trợ Data Transformation phổ biến hiện nay
Dưới đây tổng hợp các công cụ Data Transformation phổ biến nhất hiện nay, giúp hỗ trợ toàn diện cho việc chuyển đổi hóa dữ liệu:
IBM DataStage
IBM DataStage là một trong những công cụ chuyển đổi dữ liệu mạnh mẽ, có hỗ trợ cả cho mô hình ETL và ELT, đồng thời cung cấp dữ liệu đã chuyển đổi đến nhiều đích khác nhau như: dịch vụ web, hệ thống nhắn tin và kho dữ liệu. Với giao diện trực quan, IBM DataStage giúp doanh nghiệp dễ dàng thiết lập các pipeline chuyển đổi dữ liệu phức tạp, qua đó giúp tối ưu hóa việc kiểm soát và quản lý dữ liệu.
Ưu điểm nổi bật của IBM DataStage:
- Dịch vụ dữ liệu và AI toàn diện: Tích hợp nhiều dịch vụ dữ liệu và AI trên nền tảng IBM Cloud Pak for Data, bao gồm khoa học dữ liệu, ảo hóa dữ liệu và kho dữ liệu.
- Tự động hóa quy trình triển khai: Hỗ trợ CI/CD, giúp giảm thời gian phát triển và tối ưu chi phí vận hành.
- Xử lý dữ liệu phân tán: Cho phép thực thi dữ liệu trên nhiều nền tảng đám mây, giúp giảm độ trễ và tối ưu hóa hiệu suất.
Datameer
Datameer là một công cụ SaaS chuyên biệt dành cho nền tảng Snowflake Cloud, cung cấp giải pháp toàn diện từ khám phá, chuyển đổi, triển khai đến tài liệu hóa dữ liệu. Công cụ này hỗ trợ cả SQL và No Code, giúp người dùng linh hoạt thao tác với dữ liệu mà không cần kỹ năng lập trình chuyên sâu.
Ưu điểm nổi bật của Datameer:
- Quản lý vòng đời dữ liệu: Hỗ trợ đầy đủ các giai đoạn từ khám phá, chuyển đổi, triển khai đến giám sát, giúp doanh nghiệp tối ưu hóa quy trình làm việc.
- Kho dữ liệu thông minh: Cung cấp Data Catalog (danh mục dữ liệu) tích hợp, giúp truy cập nhanh vào tài liệu và siêu dữ liệu để tối ưu hóa việc di chuyển dữ liệu.
- Pipeline nâng cao: Cho phép kiểm soát phiên bản, triển khai và theo dõi dữ liệu mà không cần viết mã, mang lại trải nghiệm chuyên sâu cho cả kỹ thuật viên và nhà phân tích dữ liệu.
- Kiểm soát toàn diện: Quản lý toàn bộ metadata với hệ thống tag, mô tả và thuộc tính, đảm bảo dữ liệu luôn minh bạch với tính năng lineage (theo dõi và ghi lại nguồn gốc dữ liệu) và audit trail (dấu vết kiểm toán).
Apache Airflow
Apache Airflow là một nền tảng mã nguồn mở, giúp điều phối và giám sát quy trình biến đổi dữ liệu bằng giao diện trực quan. Với hệ thống DAG (Directed Acyclic Graphs), Apache Airflow cho phép xây dựng và kiểm soát các pipeline dữ liệu một cách linh hoạt. Ngoài ra, công cụ này hỗ trợ lập lịch tự động, theo dõi tiến trình và tích hợp với nhiều hệ thống khác nhau, giúp đảm bảo dữ liệu luôn được xử lý đúng quy trình và hiệu quả. Công cụ này đặc biệt phù hợp với các doanh nghiệp cần tích hợp với các dịch vụ đám mây như AWS, GCP, Azure và xử lý dữ liệu quy mô lớn.
Ưu điểm của Apache Airflow:
- Quản lý workflow (quy trình làm việc) trực quan: Cung cấp giao diện UI hiện đại giúp theo dõi, giám sát và kiểm soát quy trình dữ liệu dễ dàng.
- Tích hợp đa nền tảng: Hỗ trợ tích hợp với AWS, GCP, Azure và nhiều dịch vụ khác thông qua các plugin có sẵn.
- Kiến trúc DAG linh hoạt: DAG cho phép xác định, giám sát và tối ưu hóa luồng dữ liệu một cách logic và dễ mở rộng.
Nexla
Nexla là một nền tảng không cần lập trình, giúp đơn giản hóa việc chuẩn bị dữ liệu với thư viện phong phú các chức năng biến đổi. Công cụ này cung cấp một hệ thống tích hợp toàn diện, hỗ trợ nhiều phương thức biến đổi dữ liệu khác nhau.
Ưu điểm của Nexla:
- Quy trình tích hợp toàn diện: Hỗ trợ streaming, ETL, ELT, reverse ETL, API integration trong một quy trình thống nhất.
- Chất lượng và quản lý dữ liệu: Cung cấp các tính năng về chất lượng và quản trị dữ liệu nhằm đảm bảo tính chính xác và sự tuân thủ của dữ liệu. Các tính năng này bao gồm xác thực lược đồ, xác thực kiểu dữ liệu và lập hồ sơ dữ liệu.
- Xử lý dữ liệu thời gian thực: Hỗ trợ cả dữ liệu batch và streaming, giúp đưa ra quyết định nhanh chóng dựa trên dữ liệu cập nhật liên tục.

Tạm kết:
Thông qua những thông tin về khái niệm Data Transformation là gì và quá trình chuyển đổi dữ liệu được thực hiện như thế nào, có thể thấy đây không chỉ là một bước trong quy trình xử lý dữ liệu mà còn là yếu tố cốt lõi giúp doanh nghiệp khai thác tối đa giá trị từ những thông tin này. Việc chuyển đổi dữ liệu đúng cách giúp nâng cao độ chính xác, tính nhất quán và khả năng phân tích, từ đó hỗ trợ doanh nghiệp/ tổ chức đưa ra quyết định chiến lược hiệu quả hơn
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá