
Khám phá Knowledge Graph: Cách xây dựng và ứng dụng hiệu quả trong thực tế

 08/12/2025
08/12/2025
Knowledge Graph đóng vai trò quan trọng trong cách biểu diễn tri thức dưới dạng mạng lưới thực thể, quan hệ và thuộc tính, giúp máy tính hiểu ngữ cảnh, suy luận và khai thác dữ liệu như con người.
Knowledge Graph (Sơ đồ tri thức) là một công cụ mạnh mẽ giúp tổ chức, kết nối và quản lý dữ liệu phức tạp từ nhiều nguồn khác nhau. Trong bài viết này, VNPT AI sẽ cùng doanh nghiệp tìm hiểu từng bước để xây dựng một Knowledge Graph – từ xác định mục tiêu ứng dụng đến duy trì và mở rộng hệ thống.
Knowledge Graph là gì?
Knowledge Graph (sơ đồ tri thức) là mô hình kết nối các thực thể trong thế giới thực như người, sự kiện, tổ chức, địa điểm… thông qua các mối quan hệ có ý nghĩa. Thông tin trong Knowledge Graph thường được lưu trữ trong cơ sở dữ liệu dạng đồ thị (graph database) và được trình bày dưới dạng sơ đồ với các thành phần chính là:
- Nút (nodes): Đại diện cho thực thể – có thể là người, tổ chức, sản phẩm, sự kiện…
- Cạnh (edges): Thể hiện mối quan hệ giữa các nút.
- Nhãn (labels): Là tên gọi hoặc mô tả cho các nút và cạnh.
Thuật ngữ này trở nên phổ biến từ khi Google ra mắt Google Knowledge Graph năm 2012. Tuy nhiên, vẫn có ý kiến cho rằng nó không khác nhiều so với ontology hay knowledge base. Trên thực tế, cách tổ chức và liên kết tri thức của Knowledge Graph mang lại hiệu quả vượt trội trong tìm kiếm và phân tích dữ liệu.
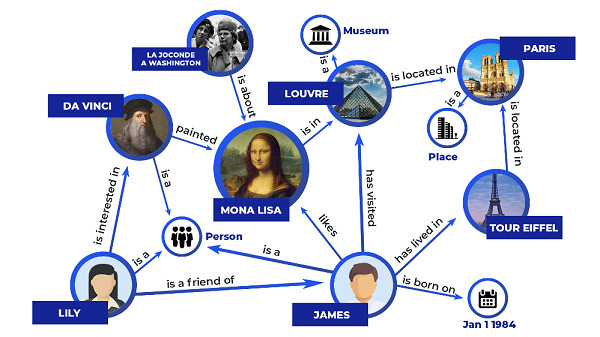
Trong các hệ thống RAG (Retrieval-Augmented Generation), Knowledge Graph đóng vai trò cơ sở tri thức có cấu trúc giúp mô hình dễ dàng truy xuất thông tin chính xác. Thay vì tìm kiếm văn bản thuần túy trong hàng triệu tài liệu, RAG có thể sử dụng sơ đồ tri thức để truy xuất mối quan hệ giữa các thực thể, từ đó tạo ra câu trả lời chính xác, mạch lạc và đúng ngữ cảnh hơn.
>>> Bạn có thể quan tâm: Embedding là gì?
Đặc điểm của Knowledge Graph
Knowledge Graph là sự kết hợp độc đáo giữa nhiều mô hình quản lý dữ liệu khác nhau. Về bản chất, nó vừa giống một cơ sở dữ liệu vì cho phép truy vấn dữ liệu có cấu trúc, vừa mang đặc tính của một đồ thị giúp phân tích các mối quan hệ như trong mạng lưới. Đồng thời, nó còn là một hệ thống tri thức với ngữ nghĩa rõ ràng, hỗ trợ diễn giải và suy luận từ dữ liệu gốc.
Khi được xây dựng trên nền tảng RDF (Resource Description Framework), Knowledge Graph phát huy khả năng biểu đạt mạnh mẽ. Nó có thể mô tả nhiều loại nội dung khác nhau như lược đồ dữ liệu, phân loại, từ vựng chuyên ngành, siêu dữ liệu, hay dữ liệu tham chiếu. Các phần mở rộng như RDF cũng giúp dễ dàng ghi chú nguồn gốc và siêu dữ liệu kèm theo từng thông tin.
Về hiệu năng, các đặc tả kỹ thuật trong Semantic Web đã được thiết kế và kiểm chứng thực tế để xử lý những đồ thị chứa hàng tỷ dữ kiện mà vẫn đảm bảo tốc độ truy vấn nhanh và ổn định. Đồng thời, hệ sinh thái công nghệ xoay quanh Knowledge Graph rất đa dạng và đồng bộ, từ giao thức truy cập như SPARQL, cơ chế quản lý đồ thị đến khả năng liên kết dữ liệu phân tán.
Knowledge Graph hoạt động như thế nào?
Knowledge Graph được hình thành từ nhiều nguồn dữ liệu khác nhau, với cấu trúc không đồng nhất. Ba thành phần chính giúp tổ chức và hiểu dữ liệu gồm: schema (định nghĩa cấu trúc), identity (xác định thực thể) và context (ngữ cảnh). Nhờ đó, hệ thống có thể phân biệt rõ các khái niệm giống tên như "Apple" là công ty hay "apple" là trái cây tùy theo ngữ cảnh.
Quá trình xây dựng Knowledge Graph thường sử dụng machine learning và xử lý ngôn ngữ tự nhiên (NLP) để tự động nhận diện thực thể, mối quan hệ và gắn nhãn – gọi là bổ sung ngữ nghĩa (semantic enrichment). Dữ liệu sau khi xử lý sẽ được kết nối và tích hợp với các tập dữ liệu liên quan khác.
Khi đã hoàn chỉnh, Knowledge Graph cho phép các hệ thống như công cụ tìm kiếm hoặc chatbot truy xuất thông tin chính xác, nhanh chóng và ngữ nghĩa hơn. Trong doanh nghiệp, nó giúp giảm thiểu thao tác thủ công và hỗ trợ ra quyết định hiệu quả hơn. Ngoài ra, nhờ khả năng kết nối dữ liệu, Knowledge Graph còn giúp khám phá mối quan hệ mới mà trước đó có thể chưa được nhận biết.
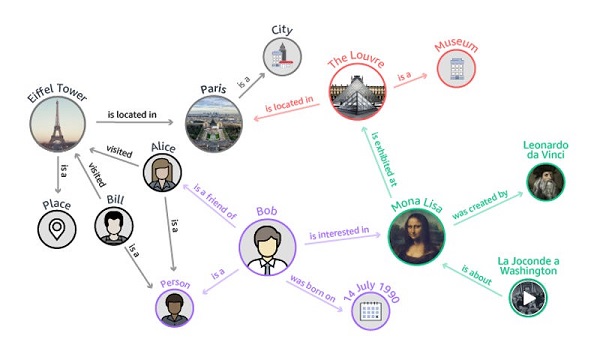
Sự khác biệt giữa Knowledge Graph và Ontology
Ontology tập trung vào việc định nghĩa khái niệm một cách chính xác và chặt chẽ trong một lĩnh vực. Chúng sử dụng các mô hình khái niệm và logic hình thức để mô tả quan hệ như “là một loại” (is-a). Đồng thời Ontology cũng thể hiện các thuộc tính đặc trưng nhằm phân biệt các khái niệm gần nhau. Ví dụ: “Viêm họng liên cầu” là một loại “viêm họng”, đồng thời là một dạng “nhiễm khuẩn” do Streptococcus pyogenes gây ra.
Ngược lại, Knowledge Graph sử dụng các khái niệm từ ontology nhưng hướng tới việc liên kết, tổ chức và lưu trữ thông tin phong phú hơn, bao gồm cả dữ liệu thực tế, ngữ cảnh, nguồn gốc thông tin và mức độ chắc chắn của các mối quan hệ. Nó không chỉ mô tả “viêm họng liên cầu là gì”, mà còn thể hiện “nó xảy ra khi nào, ở ai, điều trị ra sao, tỷ lệ kháng thuốc thế nào”.
Ứng dụng của Knowledge Graph
Knowledge Graph không chỉ được dùng trong các sản phẩm hướng tới người tiêu dùng, mà còn được ứng dụng rộng rãi trong nhiều lĩnh vực như:
Công cụ tìm kiếm và tri thức mở
Những hệ thống như DBPedia và Wikidata là ví dụ tiêu biểu về Knowledge Graph mã nguồn mở, thu thập dữ liệu từ Wikipedia. DBPedia chủ yếu trích xuất từ các infobox, còn Wikidata tập trung vào các thực thể có cấp độ trừu tượng cao hơn. Cả hai đều sử dụng định dạng RDF để xuất bản dữ liệu.
Google Knowledge Graph là một ứng dụng điển hình được tích hợp trong kết quả tìm kiếm Google (SERPs), cung cấp thông tin tóm tắt về hơn 500 triệu thực thể. Nguồn dữ liệu bao gồm Freebase, Wikipedia, CIA World Factbook… Những dữ liệu này giúp cải thiện trải nghiệm tìm kiếm theo ngữ nghĩa.
Bán lẻ và giải trí
Trong lĩnh vực bán lẻ, Knowledge Graph được dùng để xây dựng hệ thống gợi ý sản phẩm thông minh, từ đó triển khai chiến lược bán chéo (cross-sell) và tăng doanh thu trên từng khách hàng. Hệ thống có thể dựa trên hành vi mua sắm cá nhân và xu hướng tiêu dùng theo nhóm nhân khẩu học.
Trong ngành giải trí, các nền tảng như Netflix hay mạng xã hội tận dụng Knowledge Graph để gợi ý nội dung dựa trên hành vi nhấp chuột và tương tác trực tuyến của người dùng.

Tài chính và ngân hàng
Trong ngành tài chính, Knowledge Graph hỗ trợ các chương trình “biết khách hàng” (KYC) và phòng chống rửa tiền. Nó giúp các tổ chức tài chính hiểu rõ luồng giao dịch, phát hiện khách hàng có dấu hiệu vi phạm và điều tra các hành vi gian lận.
Y tế và chăm sóc sức khỏe
Trong y tế, Knowledge Graph giúp tổ chức và phân loại các mối liên hệ trong nghiên cứu y học, từ đó hỗ trợ chẩn đoán chính xác và xây dựng phác đồ điều trị phù hợp với từng bệnh nhân. Việc kết nối giữa triệu chứng, bệnh lý và thuốc điều trị trở nên mạch lạc và dễ truy xuất hơn.
Cách xây dựng một Knowledge Graph
Dưới đây là các bước cơ bản để tạo nên một Knowledge Graph hiệu quả và phù hợp với nhu cầu thực tế.
Bước 1: Xác định mục tiêu sử dụng
Trước khi bắt đầu, cần xác định rõ Knowledge Graph sẽ phục vụ mục đích gì: hệ thống gợi ý, phát hiện gian lận, tìm kiếm ngữ nghĩa (GraphRAG), hay quản lý dữ liệu chủ. Nên bắt đầu từ một bài toán cụ thể, phạm vi nhỏ, để dễ dàng kiểm thử và mở rộng sau này, thay vì cố gắng mô hình hóa toàn bộ lĩnh vực ngay từ đầu.
Bước 2: Chọn hệ quản trị cơ sở dữ liệu đồ thị
Có hai lựa chọn chính là triple store (RDF) và property graph. Triple store phù hợp cho việc biểu diễn ontology nhưng phức tạp khi mở rộng. Trong khi đó, property graph dễ hình dung, linh hoạt hơn, cho phép mô hình hoá dữ liệu với các node, quan hệ và thuộc tính – phù hợp với đa số bài toán thực tiễn.
Bước 3: Thiết kế mô hình dữ liệu đồ thị
Xác định các thực thể chính (node), mối quan hệ (edge) giữa chúng và các thuộc tính liên quan. Mỗi node đại diện cho một đối tượng như khách hàng, sản phẩm; trong khi mỗi quan hệ mô tả cách chúng tương tác. Có thể áp dụng nguyên tắc tổ chức như phân loại, phân tầng, hoặc ontology nếu cần cấu trúc chặt chẽ.
Bước 4: Chuẩn bị dữ liệu
Thu thập và làm sạch dữ liệu từ các nguồn có cấu trúc và phi cấu trúc. Quá trình này bao gồm chuẩn hóa định dạng, loại bỏ trùng lặp, xử lý dữ liệu thiếu và sửa lỗi. Một dữ liệu sạch sẽ giúp việc nạp vào Knowledge Graph trở nên chính xác và hiệu quả hơn.
Bước 5: Nạp dữ liệu vào hệ thống
Kết nối dữ liệu với mô hình đồ thị đã thiết kế. Dùng công cụ nhập dữ liệu để ánh xạ từng phần tử về đúng node, edge và property. Nên bắt đầu với một tập nhỏ để kiểm tra logic mô hình, sau đó mới mở rộng quy mô nạp dữ liệu đầy đủ.
Bước 6: Kiểm thử Knowledge Graph
Thực hiện các truy vấn mẫu để kiểm tra khả năng trả lời đúng mục tiêu đề ra. Nếu kết quả thiếu hoặc sai, cần rà soát lại mô hình, dữ liệu nguồn hoặc quy trình nhập. Kiểm thử là bước quan trọng để đảm bảo Knowledge Graph hoạt động thực tế và mang lại giá trị.
Bước 7: Duy trì và mở rộng
Knowledge Graph cần được cập nhật theo thời gian. Có thể thêm dữ liệu mới, mở rộng mô hình, cải thiện truy vấn hoặc tự động hóa cập nhật. Hệ thống cần đảm bảo khả năng mở rộng, hiệu suất ổn định và thích ứng với thay đổi trong kinh doanh hoặc dữ liệu.
>>> Đọc thêm: Knowledge base là gì?
Kết luận
Qua nội dung bài viết này của VNPT AI, có thể thấy Knowledge Graph không chỉ là một công nghệ hữu ích cho các công cụ tìm kiếm mà còn mang lại giá trị lớn trong nhiều lĩnh vực khác nhau. Việc hiểu và xây dựng Knowledge Graph giúp các doanh nghiệp tối ưu hóa quy trình, khai thác tri thức sâu rộng và ra quyết định chính xác hơn. Khi được xây dựng và duy trì đúng cách, Knowledge Graph có thể trở thành nền tảng quan trọng cho việc phát triển các hệ thống AI và phân tích dữ liệu trong tương lai.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá