
Data Labeling: Nền tảng cho những bước tiến vượt bậc trong Trí tuệ nhân tạo

 12/08/2025
12/08/2025
Data Labeling là bước nền, không thể thiếu đối với các hệ thống AI và machine learning trong việc hiểu và học học dữ liệu, từ đó đưa ra các dự đoán chính xác.
Data labeling là bước quan trọng trong quá trình phát triển các mô hình học máy và trí tuệ nhân tạo. Việc gán nhãn một cách chính xác không chỉ giúp hệ thống AI hiểu đúng bản chất của dữ liệu, mà còn là tiền đề để xử lý thông tin một cách hiệu quả, từ đó nâng cao độ chính xác của các mô hình dự đoán. Bài viết dưới đây của VNPT AI sẽ giúp doanh nghiệp hiểu rõ về nguyên lý cũng như lợi ích và thách thức của data labeling.
Data Labeling là gì?
Data labeling (gán nhãn dữ liệu) là quá trình nhận diện và gắn nhãn cho các mẫu dữ liệu thô như văn bản, hình ảnh, âm thanh hoặc video. Đây là bước tiền xử lý không thể thiếu trong quá trình phát triển các mô hình học máy (machine learning).

Mục đích của việc gán nhãn là cung cấp ngữ cảnh rõ ràng để mô hình học máy (machine learning) có thể “hiểu” dữ liệu và từ đó học cách đưa ra dự đoán chính xác. Quá trình này có thể được thực hiện thủ công hoặc có sự hỗ trợ của phần mềm.
Nguyên lý hoạt động của Data Labeling
Quy trình data labeling được triển khai thông qua sự kết hợp giữa phần mềm chuyên dụng, quy trình tổ chức dữ liệu khoa học và sự tham gia của con người. Dữ liệu thô sẽ được làm sạch, cấu trúc lại và gắn nhãn, từ đó tạo thành tập dữ liệu huấn luyện.
Các nhãn dữ liệu đóng vai trò quan trọng để các chuyên gia phân tích tách biệt các biến trong tập dữ liệu, xác định được những yếu tố dự đoán có giá trị nhất cho mô hình. Việc gán nhãn chính xác giúp mô hình học máy xác định đúng các đặc trưng (vector dữ liệu) cần thiết để học và dự đoán hiệu quả.

Quá trình này thường không hoàn toàn tự động mà có sự tham gia của con người vào việc gán nhãn, kiểm tra và hiệu chỉnh dữ liệu, được gọi là “Human-in-the-Loop” (HITL). Vai trò của người gán nhãn (data labeler) là cung cấp cho mô hình những tập dữ liệu phù hợp nhất với mục tiêu của dự án, hỗ trợ mô hình trong các giai đoạn từ huấn luyện đến kiểm thử.
Phân loại Data Labeling phổ biến hiện nay
Tùy thuộc vào loại dữ liệu được xử lý, data labeling được phân thành ba nhóm chính. Mỗi loại sẽ có phương pháp gán nhãn riêng phù hợp với mục tiêu huấn luyện mô hình học máy cụ thể.
Xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP)
Với dữ liệu văn bản, việc gán nhãn thường bắt đầu bằng cách đánh dấu các phần tử trong câu như từ loại, tên riêng (người, địa điểm, tổ chức) hoặc xác định cảm xúc và ý định của văn bản. Trong một số trường hợp, dữ liệu văn bản được trích xuất từ hình ảnh hoặc tài liệu PDF thông qua việc tạo vùng chọn (bounding box), sau đó được phiên âm thủ công thành văn bản. Dữ liệu đã gán nhãn được sử dụng để huấn luyện các mô hình xử lý ngôn ngữ tự nhiên, phục vụ các ứng dụng như phân tích cảm xúc, nhận diện thực thể, hay nhận dạng ký tự quang học (OCR).
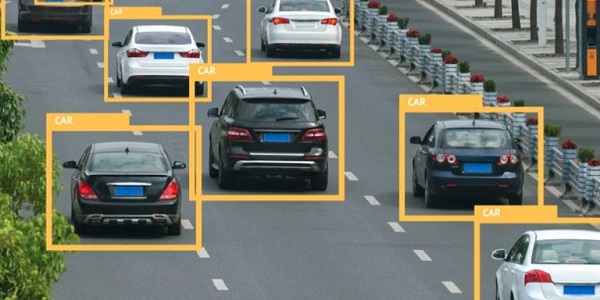
Thị giác máy tính (Computer Vision)
Đối với dữ liệu hình ảnh hoặc video, quá trình gán nhãn bao gồm các hoạt động như:
- Phân loại hình ảnh theo nội dung (ví dụ: ảnh sản phẩm hoặc ảnh ngoài đời thực)
- Vẽ bounding box để khoanh vùng các đối tượng trong ảnh hoặc video
- Đánh dấu keypoints để chỉ ra các điểm đặc trưng trên hình ảnh
- Phân đoạn ảnh ở cấp độ pixel
Tập dữ liệu được gán nhãn sẽ được dùng để huấn luyện mô hình thị giác máy tính. Sau đó mô hình tự động phân loại ảnh, phát hiện vị trí vật thể, nhận dạng điểm đặc trưng hoặc tách nền, chia vùng chính xác.
Xử lý âm thanh (Audio Processing)
Xử lý âm thanh sẽ chuyển âm thanh thành văn bản (transcription). Sau đó, các đoạn âm thanh được gán nhãn theo nội dung, loại âm thanh hoặc ngữ cảnh. Một số loại dữ liệu âm thanh được xử lý khá phổ biến như:
- Giọng nói con người
- Âm thanh tự nhiên (tiếng chó sủa, còi báo, tiếng chim hót…)
- Âm thanh trong nhà (kính vỡ, máy quét, báo động…)
Các mô hình học máy sử dụng dữ liệu âm thanh đã gán nhãn để hỗ trợ nhận dạng giọng nói, tạo trợ lý ảo và các ứng dụng chuyển giọng nói thành văn bản.
Các phương pháp Data Labeling
Có nhiều phương pháp để thực hiện data labeling bao gồm:
Gán nhãn nội bộ (Internal labeling)
Các chuyên gia khoa học dữ liệu trong công ty trực tiếp thực hiện gán nhãn để đảm bảo độ chính xác và kiểm soát chất lượng tốt hơn. Tuy nhiên, phương pháp này thường tốn nhiều thời gian và phù hợp với các doanh nghiệp lớn có nguồn lực dồi dào.
Gán nhãn tổng hợp (Synthetic labeling)
Phương pháp này tạo ra dữ liệu mới từ các bộ dữ liệu hiện có, góp phần cải thiện chất lượng và rút ngắn thời gian chuẩn bị dữ liệu. Tuy nhiên, gán nhãn tổng hợp cũng đòi hỏi sức mạnh tính toán lớn, dẫn đến tăng chi phí đầu tư.
Gán nhãn tự động bằng chương trình (Programmatic labeling)
Sử dụng các đoạn mã tự động để gán nhãn dữ liệu, tiết kiệm thời gian và giảm nhu cầu gán nhãn thủ công. Tuy nhiên, máy móc không phải lúc nào cũng hiểu dữ liệu đúng như con người, nên việc gán nhãn tự động có thể dẫn đến sai sót. Vì vậy, phương pháp này cần có sự tham gia của con người trong một quy trình gọi là “Human-in-the-Loop” (HITL), tức là con người sẽ kiểm tra, chỉnh sửa và huấn luyện lại hệ thống để đảm bảo dữ liệu được gán nhãn chính xác hơn qua từng vòng lặp.

Thuê ngoài (Outsourcing)
Đây là lựa chọn phù hợp cho các dự án có tính chất tạm thời và đòi hỏi nhân lực lớn. Tuy nhiên, việc phát triển và quản lý quy trình làm việc với đội ngũ thuê ngoài có thể khá phức tạp và mất thời gian.
Gán nhãn qua đám đông (Crowdsourcing)
Phương pháp này tận dụng sức mạnh của cộng đồng trực tuyến để hoàn thành các nhiệm vụ nhỏ một cách nhanh chóng và tiết kiệm chi phí. Tuy nhiên, chất lượng nhân sự, quy trình kiểm soát chất lượng và quản lý dự án có thể dao động tùy từng nền tảng. Một ví dụ nổi bật là hệ thống Recaptcha, người dùng được yêu cầu xác định các hình ảnh có chứa xe hơi để xác nhận họ không phải robot, đồng thời góp phần tạo cơ sở dữ liệu gán nhãn ảnh hiệu quả.
Lợi ích và thách thức khi thực hiện Data Labeling
Việc gán nhãn dữ liệu mang lại nhiều lợi ích nhưng cũng đi kèm với không ít thách thức cần được giải quyết như:
Lợi ích
- Cải thiện độ chính xác của mô hình: Dữ liệu được gán nhãn đúng là điều kiện quan trọng để mô hình học máy học hiệu quả và đưa ra dự đoán chính xác hơn.
- Tăng khả năng sử dụng dữ liệu: Giúp dữ liệu dễ xử lý và tối ưu hóa mô hình, từ hình ảnh đến văn bản.
- Thúc đẩy đổi mới sáng tạo: Việc chuẩn hóa và tự động hóa một phần quy trình gán nhãn giúp tiết kiệm thời gian, cho phép đội ngũ phát triển tập trung vào các hoạt động có giá trị cao hơn như xây dựng mô hình và triển khai ứng dụng.
Thách thức
- Tốn kém thời gian và chi phí: Quá trình gán nhãn, đặc biệt khi thực hiện thủ công, đòi hỏi nhiều nguồn lực. Ngay cả khi áp dụng tự động hóa, vẫn cần chuẩn bị hệ thống và kỹ thuật hỗ trợ.
- Sai sót do con người: Lỗi gán nhãn gây giảm chất lượng dữ liệu, ảnh hưởng đến mô hình, cần kiểm soát chất lượng kỹ lưỡng.
Ứng dụng của Data Labeling trong các lĩnh vực
Data labeling đóng vai trò quan trọng trong nhiều lĩnh vực như:
- Thị giác máy tính: Data labeling giúp huấn luyện mô hình nhận diện hình ảnh, phân đoạn đối tượng và xác định vị trí chi tiết trong ảnh. Ứng dụng rộng rãi trong sản xuất, ô tô, năng lượng và nhiều ngành công nghiệp khác.
- Xử lý ngôn ngữ tự nhiên (NLP): Gán nhãn văn bản hỗ trợ phân tích cảm xúc, nhận diện thực thể và chuyển đổi chữ viết thành giọng nói, dùng trong chatbot, trợ lý ảo và dịch máy.
- Phương tiện tự lái: Dữ liệu được gán nhãn cho phép xe tự hành nhận biết người đi bộ, biển báo và vật thể trên đường, đảm bảo an toàn khi vận hành.
- Y tế: Gán nhãn hình ảnh y khoa đóng vai trò trò quan trọng trong việc phát hiện khối u và bất thường trên MRI, X-quang, đồng thời hỗ trợ phân tích hồ sơ sức khỏe điện tử để ra các quyết định điều trị chính xác hơn.
- Thương mại điện tử: Hệ thống gợi ý sản phẩm dựa trên dữ liệu gán nhãn hành vi và sở thích khách hàng, từ đó tăng trải nghiệm người dùng và doanh số bán hàng.
- Mạng xã hội: Việc gán nhãn nội dung hỗ trợ phát hiện và loại bỏ các bài đăng hoặc bình luận vi phạm, góp phần duy trì môi trường mạng an toàn và lành mạnh.
- Dịch vụ tài chính: Dữ liệu giao dịch được gán nhãn để đánh giá rủi ro và phát hiện gian lận, bảo vệ khách hàng và tổ chức tài chính hiệu quả hơn.
- Dịch thuật: Việc gán nhãn văn bản nâng cao độ chính xác của hệ thống dịch máy, góp phần cải thiện hiệu quả chuyển đổi ngôn ngữ tự nhiên.
Kết luận
Qua bài viết của VNPT AI có thể thấy data labeling không chỉ đơn thuần là công đoạn chuẩn bị dữ liệu mà còn là cầu nối quan trọng để trí tuệ nhân tạo phát triển thông minh hơn từng ngày. Dù còn nhiều thách thức nhưng với sự tiến bộ về công nghệ và quy trình, data labeling sẽ ngày càng mở rộng phạm vi ứng dụng, đem lại giá trị thiết thực và góp phần thay đổi cách con người tương tác với thế giới.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá