
Mô hình YOLO là gì? Cách hoạt động và ứng dụng nổi bật của mô hình Yolo

 02/07/2025
02/07/2025
Mô hình YOLO - mô hình phát hiện đối tượng nổi bật với khả năng xử lý nhanh và chính xác mà chỉ sử dụng một mạng CNN duy nhất để dự đoán vị trí và nhãn của đối tượng trong ảnh hoặc video theo thời gian thực.
Theo Grand View Research, thị trường nhận dạng hình ảnh toàn cầu được định giá ở mức 53,3 tỷ đô la Mỹ vào năm 2023 và dự kiến sẽ tăng trưởng ở tốc độ CAGR là 12,8% từ năm 2024 đến năm 2030. Trong bối cảnh đó, mô hình YOLO đã trở thành một công cụ không thể thiếu trong lĩnh vực thị giác máy tính nhờ khả năng phát hiện đối tượng nhanh chóng và chính xác. Vậy mô hình YOLO là gì và được ứng dụng ra sao trong thực tế? Cùng VNPT AI tìm hiểu trong bài viết dưới đây.
Mô hình YOLO là gì?
Mô hình YOLO (viết tắt của You Only Look Once) là một mô hình mạng nơ-ron tích chập (CNN) được sử dụng phổ biến trong lĩnh vực thị giác máy tính, đặc biệt để phát hiện và nhận dạng đối tượng trong ảnh hoặc video.

Điểm đặc biệt của kiến trúc YOLO nằm ở khả năng phát hiện tất cả các đối tượng trong một hình ảnh chỉ qua một lần lan truyền của mạng. Khác với các phương pháp truyền thống tách biệt bước đề xuất vùng và bước phân loại, YOLO xử lý toàn bộ ảnh đầu vào như một vấn đề hồi quy duy nhất, vừa dự đoán được vị trí (tọa độ) các đối tượng, vừa phân loại được chúng trong một lần duy nhất.
Nguyên lý hoạt động của YOLO
Mô hình YOLO hoạt động dựa trên nguyên tắc “nhìn một lần duy nhất”, tức là xử lý toàn bộ ảnh đầu vào chỉ trong một lần truyền qua mạng nơ-ron. Cụ thể như sau:
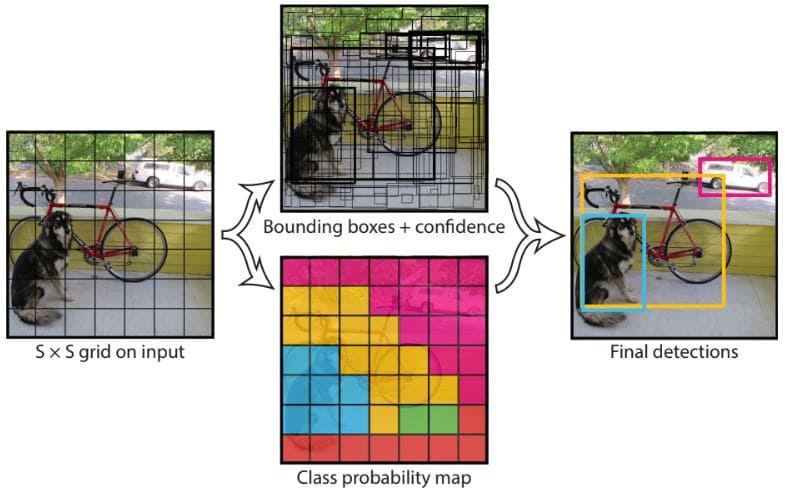
Chia ảnh thành lưới S x S
Hình ảnh đầu vào sẽ được chia thành một lưới có kích thước S × S. Mỗi ô trong lưới sẽ chịu trách nhiệm phát hiện đối tượng nếu tâm của đối tượng nằm trong ô đó. Đối với mỗi ô, mô hình sẽ dự đoán nhiều hộp giới hạn. Mỗi hộp đi kèm với một điểm tin cậy, thể hiện mức độ chắc chắn rằng trong hộp có một đối tượng và độ chính xác trong việc xác định vị trí của đối tượng đó.
Tiếp nhận và xử lý hình ảnh bằng CNN
Mạng CNN chính là xương sống của kiến trúc mô hình YOLO, trong đó 20 lớp tích chập đầu tiên được huấn luyện trước trên tập dữ liệu ImageNet. Ban đầu, mô hình được cắm thêm các lớp trung gian như lớp tổng hợp trung bình và lớp kết nối đầy đủ để phục vụ cho việc phân loại ảnh. Sau khi hoàn tất giai đoạn huấn luyện này, mô hình sẽ được điều chỉnh lại để phục vụ mục tiêu phát hiện đối tượng. Lúc này, lớp kết nối đầy đủ cuối cùng sẽ đồng thời dự đoán cả loại đối tượng và vị trí của các hộp giới hạn.
Dự đoán dựa trên độ trùng khớp
Trong quá trình huấn luyện, để đảm bảo mỗi đối tượng chỉ có một dự đoán chính xác nhất, YOLO chọn ra hộp giới hạn có độ trùng lặp cao nhất với thực tế (dựa trên chỉ số IOU - Intersection over Union) để đại diện cho đối tượng đó. Sau khi dự đoán, YOLO sử dụng kĩ thuật Non-Maximum Suppression (NMS) để loại bỏ các hộp chồng lặp, chỉ giữ lại một hộp đại diện tốt nhất cho mỗi đối tượng.
Các phiên bản của YOLO phổ biến hiện nay
Các phiên bản kiến trúc YOLO đang được sử dụng rộng rãi hiện nay bao gồm:
YOLO v2
YOLOv2, hay còn gọi là YOLO9000, được ra mắt vào năm 2016 như một phiên bản cải tiến của YOLO ban đầu. Mô hình này được tối ưu để nhanh, chính xác và phát hiện được nhiều loại đối tượng hơn. YOLOv2 sử dụng kiến trúc backbone mới là Darknet-19, đồng thời áp dụng anchor boxes - các khung hình có kích thước và tỷ lệ khác nhau, giúp mô hình dễ dàng phát hiện các đối tượng có hình dạng và kích cỡ đa dạng.
YOLO v3
YOLO v3 ra mắt năm 2018 với nhiều cải tiến giúp tăng độ chính xác trong việc phát hiện đối tượng, đặc biệt là với các đối tượng nhỏ. Mô hình sử dụng Darknet-53 làm xương sống - một kiến trúc sâu hơn và mạnh hơn so với Darknet-19, kết hợp giữa các lớp tích chập và các kết nối tương tự như trong mô hình kiến trúc mạng ResNet.
Một điểm nổi bật của YOLO v3 là khả năng dự đoán ở ba cấp độ khác nhau trong cùng một mạng, giúp mô hình nhận diện các đối tượng có kích thước khác nhau trong ảnh một cách chính xác hơn. Ngoài ra, mỗi cấp độ sử dụng các anchor boxes phù hợp để tăng độ linh hoạt trong phát hiện.
YOLO v4
YOLO v4 được ra mắt vào năm 2020 như một bước nâng cấp từ YOLO v3, với mục tiêu tăng độ chính xác mà vẫn giữ được tốc độ xử lý cao. Một điểm nổi bật của YOLO v4 là sử dụng kiến trúc CSPNet (Cross Stage Partial Network), được phát triển dựa trên ResNet. Kiến trúc này chia mạng thành nhiều phần nhỏ, sau đó kết hợp lại, giúp giảm khối lượng tính toán mà vẫn giữ được khả năng học đặc trưng tốt. Nhờ đó, mô hình có thể phát hiện đối tượng hiệu quả hơn.
>>> Bạn có thể quan tâm: Edge Detection - Công nghệ đột phá trong xử lý hình ảnh
Những ưu điểm nổi bật của mô hình YOLO
Nhờ nguyên lý hoạt động chặt chẽ và nâng cấp thường xuyên, thuật toán YOLO có những ưu điểm nổi bật sau:
- Tốc độ xử lý nhanh: YOLO nổi bật với khả năng xử lý ảnh cực nhanh nhờ thiết kế một bước duy nhất. Thay vì quét từng vùng nhỏ trong ảnh như nhiều phương pháp khác, mô hình này xử lý toàn bộ hình ảnh cùng lúc, giúp phát hiện đối tượng gần như tức thì. Ưu điểm này của mô hình phù hợp với các ứng dụng thời gian thực như giám sát an ninh, xe tự hành, drone,...
- Độ chính xác cao: Mặc dù ưu tiên tốc độ, các phiên bản mới của YOLO (đặc biệt từ YOLOv3 đến YOLOv8) vẫn duy trì độ chính xác cao nhờ cải tiến kiến trúc mạng, kỹ thuật huấn luyện tiên tiến và khả năng phát hiện đa tỷ lệ, giúp nhận diện tốt cả các đối tượng nhỏ, mờ hoặc bị che khuất.
- Khả năng tổng quát tốt: Khác với các mô hình chia nhỏ ảnh thành nhiều vùng để xử lý, YOLO phân tích toàn bộ hình ảnh một cách tổng thể, giúp mô hình hiểu ngữ cảnh và mối liên hệ giữa các đối tượng. Nhờ đó, mô hình có khả năng tổng quát tốt hơn và có thể nhận diện được các đối tượng trong những tình huống chưa từng gặp khi huấn luyện.
- Mã nguồn mở: Mô hình YOLO được phát triển và duy trì dưới dạng mã nguồn mở, giúp cộng đồng nghiên cứu và phát triển dễ dàng truy cập, sử dụng và tùy chỉnh.
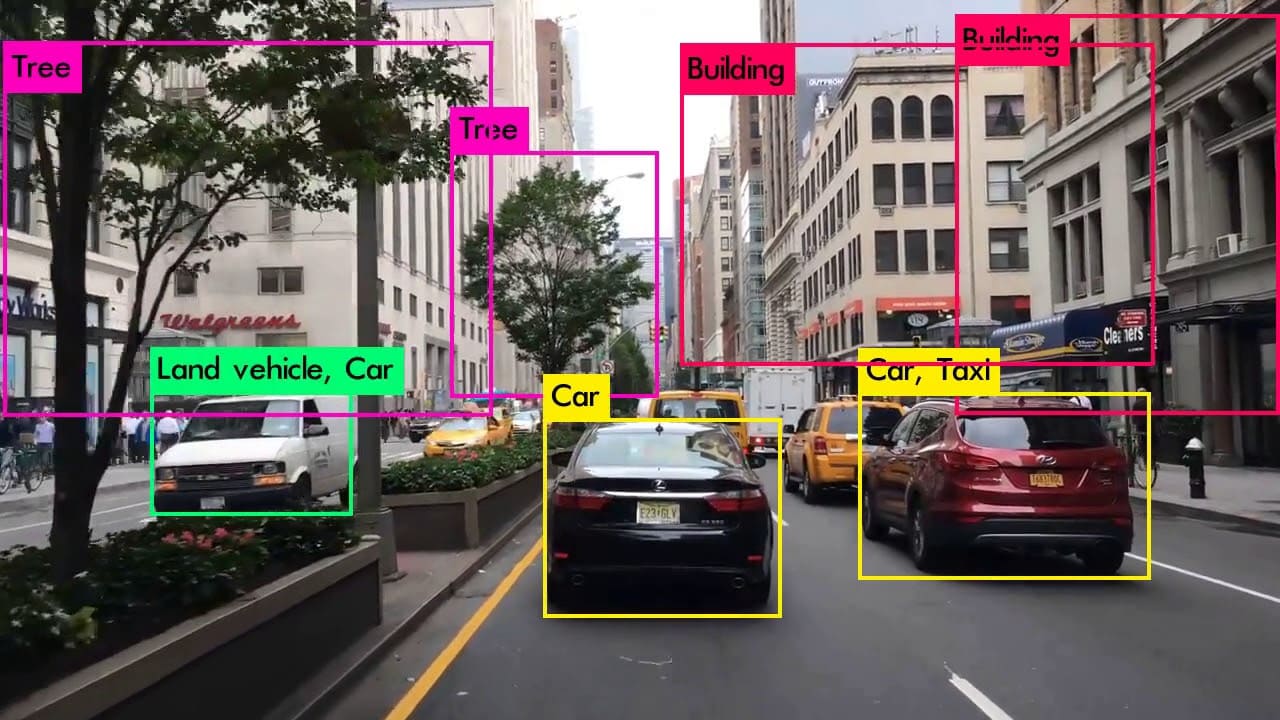
Các ứng dụng của YOLO trong thực tế
Với những ưu điểm nổi bật, mô hình YOLO đang được ứng dụng rộng rãi trong nhiều lĩnh vực khác nhau:
- Chăm sóc sức khỏe: Mô hình YOLO được ứng dụng để phát hiện nhanh các dấu hiệu bất thường trên hình ảnh y khoa như X-quang, CT hay MRI. Mô hình này hỗ trợ bác sĩ trong việc chẩn đoán chính xác và kịp thời các bệnh lý như ung thư, tổn thương mô hoặc các khối u nhỏ khó nhận biết bằng mắt thường.
- Robot và tự động hóa: Nhờ mô hình YOLO, robot có thể nhận diện và phân loại các vật thể trong môi trường xung quanh một cách nhanh chóng và chính xác. Nhờ đó, chúng có thể thực hiện các nhiệm vụ như phân loại hàng hóa trong kho, nhận biết chướng ngại vật để di chuyển an toàn, hoặc tương tác hiệu quả với con người.
- Giám sát an ninh: YOLO giúp nhận diện và theo dõi người, xe cộ hay vật thể khả nghi qua hệ thống camera. Nhờ khả năng phát hiện thời gian thực, YOLO hỗ trợ cảnh báo sớm các tình huống bất thường, giúp lực lượng an ninh phản ứng kịp thời và nâng cao hiệu quả bảo vệ an toàn cho các khu vực quan trọng.
- Mô hình xe tự lái: YOLO đóng vai trò quan trọng trong hệ thống nhận thức của xe tự hành, giúp phát hiện người đi bộ, xe cộ, biển báo giao thông và vật cản trên đường. Nhờ khả năng nhận diện thời gian thực, xe có thể phản ứng kịp thời trước các tình huống bất ngờ, đảm bảo an toàn khi vận hành
Tạm kết
Có thể thấy, YOLO không chỉ là một mô hình phát hiện đối tượng nhanh và mạnh mẽ, mà còn là một công cụ AI linh hoạt, dễ ứng dụng trong nhiều ngành nghề khác nhau. Bài viết trên của VNPT AI hy vọng đã cung cấp cho bạn đọc những thông tin cơ bản về mô hình YOLO. Với sự phát triển không ngừng của công nghệ, các phiên bản mới của YOLO như YOLLO v8 đang tiếp tục mở rộng giới hạn của thị giác máy tính, hứa hẹn đem lại nhiều đột phá hơn nữa trong các ứng dụng AI thực tế.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá