
Text Normalization: Bước nền tảng trong xử lý ngôn ngữ tự nhiên

 11/11/2025
11/11/2025
Text Normalization giúp máy nhận diện các từ hoặc cụm từ tương tự một cách hiệu quả, giảm lỗi trong quá trình phân tích, tăng độ chính xác cho các tác vụ tìm kiếm như phân tích cảm xúc, dịch máy...
Trong kỷ nguyên dữ liệu số, văn bản được thu thập từ mạng xã hội, email hay các nền tảng giao tiếp trực tuyến có đặc điểm rất đa dạng, thiếu tính đồng nhất và chứa nhiều yếu tố “nhiễu” ngôn ngữ. Để các mô hình xử lý ngôn ngữ tự nhiên (NLP) có thể phân tích và hiểu chính xác, cần có một bước quan trọng gọi là Text Normalization – chuẩn hóa văn bản. Vậy Text Normalization là gì và có những công cụ kỹ thuật nào hỗ trợ? Hãy cùng VNPT AI tìm hiểu trong bài viết dưới đây..
Text Normalization là gì?
Text Normalization (chuẩn hóa văn bản) là quá trình chuyển đổi có hệ thống dữ liệu văn bản thô sang một định dạng đồng nhất và có thể dự đoán trước. Mục tiêu của bước này là giảm thiểu sự đa dạng ngôn ngữ trong dữ liệu, giúp mô hình tập trung vào nội dung và ngữ nghĩa thay vì bị nhiễu bởi các yếu tố bề mặt như:
- Khác biệt về chính tả hoặc cách viết hoa/thường
- Từ rút gọn, ký tự đặc biệt hay biểu tượng cảm xúc
- Dấu câu, ký hiệu và các yếu tố không mang nghĩa ngôn ngữ
Nhờ đó, các hệ thống xử lý ngôn ngữ tự nhiên có thể tập trung vào việc phân tích nội dung và ý nghĩa thay vì bị ảnh hưởng bởi các biến thể ngôn ngữ. Text Normalization chính là nền móng, góp phần nâng cao độ chính xác và hiệu quả cho các tác vụ xử lý văn bản ở giai đoạn sau.

Tại sao cần phải chuẩn hóa văn bản trong NLP?
Text Normalization là một bước thiết yếu trong xử lý ngôn ngữ tự nhiên. Kỹ thuật này được áp dụng rộng rãi trong các hệ thống nhận dạng giọng nói, tổng hợp văn bản thành giọng nói, lọc email rác và nhiều ứng dụng NLP khác.
Trong ngôn ngữ tự nhiên, cùng một khái niệm có thể được biểu đạt dưới nhiều hình thức khác nhau. Ví dụ: “collect”, “collection”, “collective” hay “collectively” – con người dễ dàng nhận ra chúng đều bắt nguồn từ cùng một gốc từ, nhưng máy tính thì không. Text Normalization giúp giảm bớt sự đa dạng này bằng cách đưa văn bản thô về dạng chuẩn, nhờ đó số biến đầu vào của mô hình học máy giảm xuống, từ đó tăng hiệu quả xử lý và giảm sai sót. Quá trình này cũng góp phần làm giảm độ phức tạp của các cấu trúc biểu diễn văn bản.
Các kỹ thuật trong Text Normalization
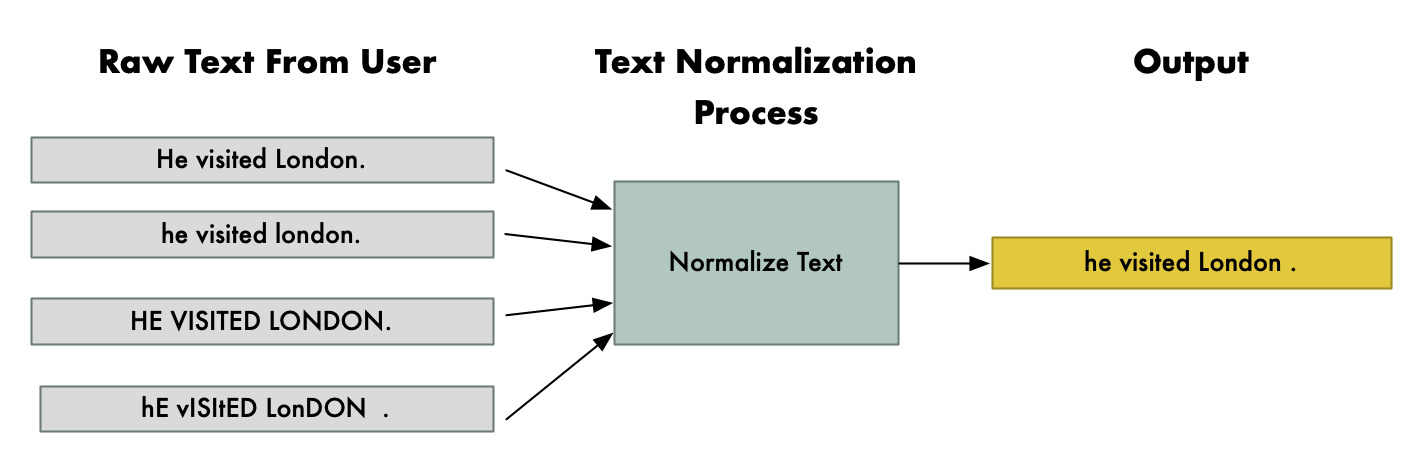
Có nhiều kỹ thuật khác nhau để chuẩn hóa văn bản trong NLP. Dưới đây là một số kỹ thuật phổ biến được sử dụng nhằm loại bỏ nhiễu, giảm độ phức tạp và giúp mô hình xử lý ngôn ngữ tự nhiên phân tích dữ liệu chính xác hơn:
- Chuẩn hóa chữ hoa - chữ thường: Chuyển toàn bộ văn bản về cùng một dạng chữ (thường là chữ thường) để loại bỏ sự khác biệt giữa chữ hoa và chữ thường. Ví dụ “Hà Nội” và “hà nội” sẽ được coi như nhau.
- Loại bỏ dấu câu: Xóa hoặc chuẩn hóa dấu câu như dấu chấm, phẩy, chấm hỏi, chấm than… nhằm giảm nhiễu, giúp mô hình tập trung vào từ ngữ chính.
- Bỏ các từ không cần thiết: Loại bỏ các từ ít mang ý nghĩa phân biệt (ví dụ “và”, “là”, “của” trong tiếng Việt hoặc “the”, “is”, “of” trong tiếng Anh) để làm gọn dữ liệu đầu vào.
- Rút gọn về từ gốc: Cắt bỏ hậu tố hoặc tiền tố để đưa từ về dạng cơ bản, ví dụ “running” → “run”.
- Tách từ: Tách văn bản thành các đơn vị nhỏ hơn (token), thường là từ, cụm từ hoặc câu. Đây là bước nền tảng để xử lý các kỹ thuật khác.
- Thay thế từ đồng nghĩa và viết tắt bằng dạng đầy đủ: Thay thế các từ đồng nghĩa hoặc viết tắt bằng dạng chuẩn/đầy đủ của chúng. Ví dụ “info” → “information”, “USA” → “United States of America”. Việc này giúp mô hình nhận diện được ý nghĩa thực sự thay vì coi đó là các biến thể khác nhau.
- Loại bỏ hoặc chuẩn hóa số và ký hiệu: Loại bỏ hoặc chuẩn hóa chữ số, đơn vị đo lường, ký hiệu đặc biệt (như “10k” → “10,000” hoặc xóa hoàn toàn tùy mục đích) để dữ liệu đồng nhất hơn.
- Loại bỏ các ký tự đặc biệt: Xóa bỏ các ký tự đặc biệt còn sót lại như emoji, hình ảnh, HTML tag hay ký tự không phải chữ.
Các công cụ và thư viện phổ biến hỗ trợ Text Normalization
Để thực hiện việc chuẩn hóa văn bản một cách hiệu quả, người dùng có thể phối hợp sử dụng các công cụ và thư viện hỗ trợ như:
- NLTK (Natural Language Toolkit): Đây là một thư viện giúp xử lý văn bản bằng Python. Nó có sẵn các công cụ để tách từ, bỏ dấu câu, bỏ từ thừa, rút gọn từ về gốc… giúp văn bản gọn gàng trước khi phân tích.
- spaCy: Một thư viện Python hiện đại, tối ưu về tốc độ và hiệu năng.. spaCy cũng có đầy đủ công cụ để làm sạch văn bản, tách từ, tìm dạng gốc của từ, loại bỏ từ ít quan trọng.
- TextBlob: Thư viện Python nhỏ gọn, dễ dùng, dựa trên NLTK. Phù hợp cho người mới bắt đầu, có thể tách từ, rút gọn từ, sửa lỗi chính tả, phân tích cảm xúc.
- Gensim: Thư viện giúp xử lý dữ liệu văn bản trước khi đưa vào các mô hình học máy, ví dụ biến văn bản thành danh sách từ, bỏ từ ít quan trọng, tính độ quan trọng của từ.
- Stanford CoreNLP: Bộ công cụ nổi tiếng của Đại học Stanford. Có thể cài trên máy tính và dùng nhiều ngôn ngữ. Nó giúp tách câu, tách từ, tìm dạng gốc của từ, phân tích cấu trúc câu.
- Thư viện cho tiếng Việt (Pyvi, Underthesea, VnCoreNLP): Các công cụ này được phát triển riêng cho tiếng Việt. Chúng có thể tách từ, chuẩn hóa dấu, làm sạch văn bản tiếng Việt trước khi phân tích.
Ứng dụng thực tế của Text Normalization
Nhờ tính tiện lợi và khả năng tối ưu hóa văn bản, Text Normalization được ứng dụng trong nhiều lĩnh vực khác nhau như:
- Dịch máy: Văn bản được chuẩn hóa giúp hệ thống nhận diện đúng dạng từ và ngữ cảnh, từ đó cho ra bản dịch chính xác và mượt mà hơn.
- Chatbot: Chuẩn hóa giúp hệ thống hiểu câu hỏi của người dùng dù họ viết có dấu hay không, viết tắt hay sai chính tả, nhờ đó phản hồi đúng ý hơn.
- Phân tích cảm xúc: Chuẩn hóa làm sạch dữ liệu bình luận, đánh giá hay bài đăng trên mạng xã hội để mô hình phân tích cảm xúc và xu hướng một cách chính xác, ít bị nhiễu hơn.

Thách thức và xu hướng phát triển của Text Normalization
Trong khi Text Normalization đã được ứng dụng nhiều trong xử lý ngôn ngữ tự nhiên, việc áp dụng nó trong môi trường thực tế vẫn tồn tại không ít thách thức. Cụ thể:
- Dữ liệu phi cấu trúc phức tạp: Văn bản thực tế (bình luận mạng xã hội, email, tin nhắn…) thường chứa lỗi chính tả, từ viết tắt, biểu tượng cảm xúc, ký tự đặc biệt nên việc chuẩn hóa sẽ trở nên khó khăn hơn so với văn bản chuẩn.
- Đa ngôn ngữ và biến thể ngôn ngữ: Mỗi ngôn ngữ có quy tắc chính tả, ngữ pháp, từ viết tắt khác nhau. Ngay trong cùng một ngôn ngữ cũng có biến thể vùng miền, tiếng lóng. Do vậy, việc xây dựng một bộ quy tắc chuẩn hóa chung trở nên phức tạp.
- Thiếu dữ liệu huấn luyện chất lượng cao: Để mô hình chuẩn hóa tốt cho nhiều ngôn ngữ cần nhiều dữ liệu gán nhãn chuẩn, tuy nhiên, việc thu thập và gán nhãn cho đa ngôn ngữ rất tốn kém.
Cùng với sự phát triển của các mô hình AI hiện đại như BERT hay GPT, cách tiếp cận đối với Text Normalization cũng đang thay đổi. Thay vì chỉ dựa vào các quy tắc thủ công do con người đặt ra, nhiều hệ thống hiện nay đưa thẳng bước chuẩn hóa văn bản vào trong toàn bộ quy trình xử lý dữ liệu (pipeline). Những mô hình thuộc nhóm “transformer” hay “pre trained models”, tức các mô hình đã được huấn luyện trước để hiểu ngôn ngữ, có thể tự động học được một phần các quy tắc chuẩn hóa, nhờ đó tăng hiệu quả xử lý văn bản.
Tạm kết
Qua bài viết trên, VNPT AI đã giúp bạn đọc hiểu những thông tin cơ bản về Text Normalization. Tóm lại, Text Normalization đóng vai trò nền tảng trong mọi hệ thống xử lý ngôn ngữ tự nhiên. Việc chuẩn hóa văn bản không chỉ giúp giảm nhiễu, làm dữ liệu nhất quán mà còn nâng cao hiệu quả của các mô hình phân tích và dự đoán. Trong bối cảnh khối lượng và độ phức tạp của dữ liệu ngày càng tăng, Text Normalization sẽ tiếp tục là bước chuẩn bị quan trọng, đảm bảo các ứng dụng NLP hoạt động chính xác và tối ưu.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá