
ReLU function: Bước tiến đột phá trong lĩnh vực học sâu

 04/12/2025
04/12/2025
ReLU function là một trong những hàm kích hoạt quan trọng và phổ biến nhất trong các mô hình học sâu hiện nay. Nó vừa giúp mạng học được quan hệ phi tuyến phức tạp, vừa làm cho việc huấn luyện nhanh và ổn định hơn so với nhiều hàm kích hoạt cũ như sigmoid/tanh.
Để huấn luyện một mô hình AI có độ chính xác cao, các nhà phát triển thường phải đối mặt với nhiều thách thức, trong đó có việc lựa chọn hàm kích hoạt phù hợp. Hàm ReLU (ReLU function) đã xuất hiện như một giải pháp hiệu quả, giúp tối ưu hóa quá trình học của mạng nơ-ron. Vậy ReLU function là gì, được ứng dụng như thế nào trong lĩnh vực học sâu? Hãy tham khảo bài viết dưới đây của VNPT AI để hiểu rõ hơn về sức mạnh của hàm kích hoạt này.
ReLU function là gì?
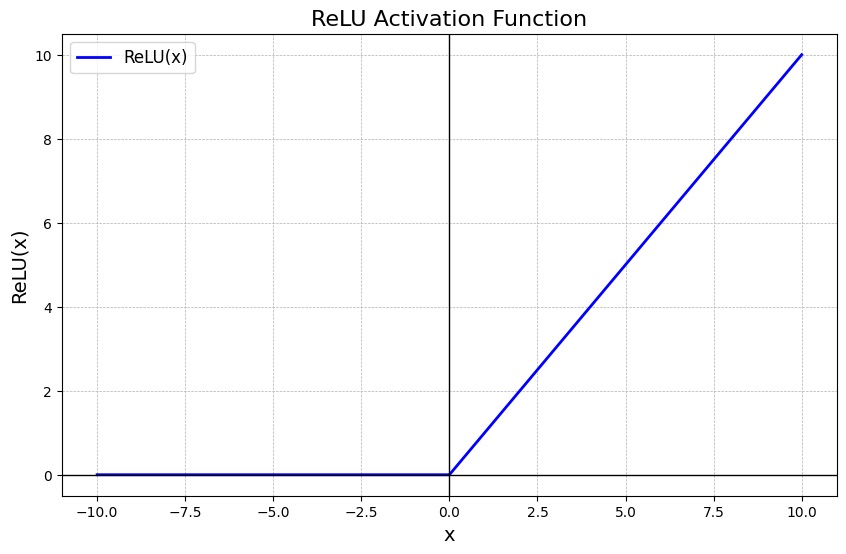
ReLU (Rectified Linear Unit) là một hàm kích hoạt phổ biến trong mạng nơ-ron nhân tạo, đặc biệt trong các mô hình học sâu. Đây là một hàm phi tuyến tính đơn giản, giúp đưa yếu tố phi tuyến tính vào mô hình bằng cách biến đổi đầu ra của nơ-ron trước khi truyền sang lớp kế tiếp. Công thức toán học của ReLU được biểu diễn như sau:
f(x) = max(0,x)
Trong đó:
- x là giá trị đầu vào của nơ-ron.
- Nếu giá trị đầu vào x > 0, hàm sẽ trả về chính giá trị đó (f(x) = x).
- Nếu giá trị đầu vào x ≤ 0, hàm sẽ trả về 0 (f(x) = 0).
Nhờ cấu trúc đơn giản, ReLU có tốc độ tính toán nhanh hơn nhiều so với các hàm kích hoạt khác như Sigmoid hay Tanh. Điều này cũng giúp giải quyết hiệu quả vấn đề "gradient biến mất" (vanishing gradient) - thường gặp trong quá trình huấn luyện mạng nơ-ron. Nhờ đó, các mạng sâu có thể học hiệu quả hơn, thúc đẩy quá trình phát triển của các mô hình Trí tuệ nhân tạo (AI) phức tạp.
Các biến thể và cải tiến của ReLU
Để khắc phục một số hạn chế của hàm ReLU, đặc biệt là vấn đề "nơ-ron chết" (dying ReLU), nhiều biến thể đã được phát triển. Trong đó, mỗi biến thể đều sở hữu những ưu điểm riêng, giúp tăng hiệu quả huấn luyện mạng nơ-ron.
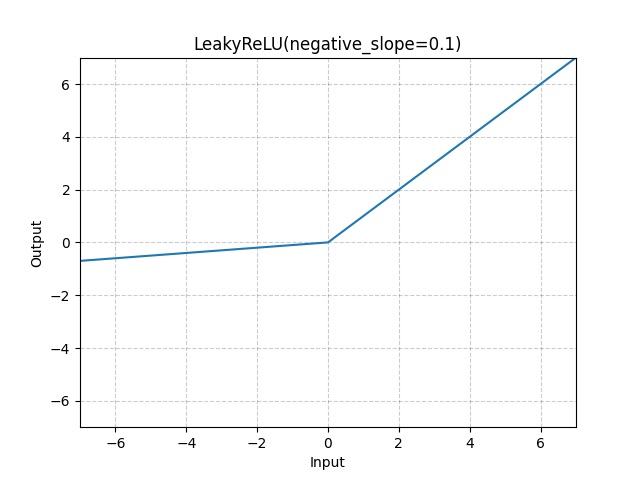
Leaky ReLU
Thay vì trả về 0 cho các giá trị âm, Leaky ReLU đưa vào một độ dốc nhỏ, không bằng 0. Điều này giúp các nơ-ron không bị "chết" hoàn toàn, cho phép gradient vẫn có thể lan truyền qua các nơ-ron có giá trị âm. Điều này giúp quá trình mạng nơ-ron trở nên ổn định và hiệu quả hơn.
Công thức của Leaky ReLU như sau:
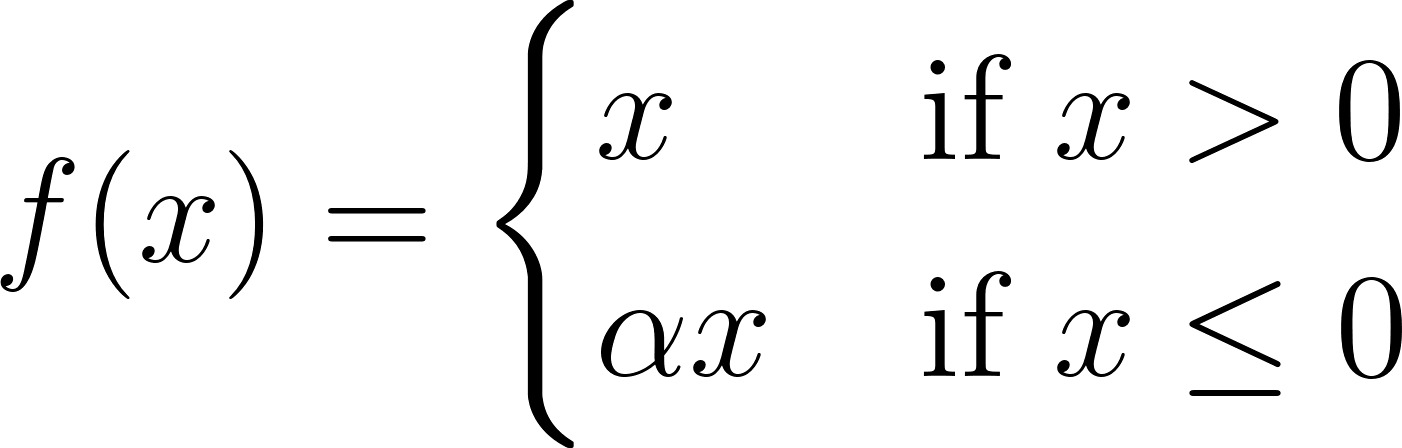
Trong đó α là một hằng số nhỏ (thường là 0.01).
Parametric ReLU (PReLU)
PReLU là một phiên bản mở rộng của Leaky ReLU. Thay vì sử dụng một hằng số cố định cho độ dốc ở phần âm, PReLU sẽ học giá trị của α trong quá trình huấn luyện. Điều này giúp mô hình linh hoạt hơn, có thể tự động điều chỉnh độ dốc tốt nhất cho từng nơ-ron, qua đó giúp nâng cao hiệu suất tổng thể.
Công thức của PReLU:
Trong đó, α là một tham số có thể học được.
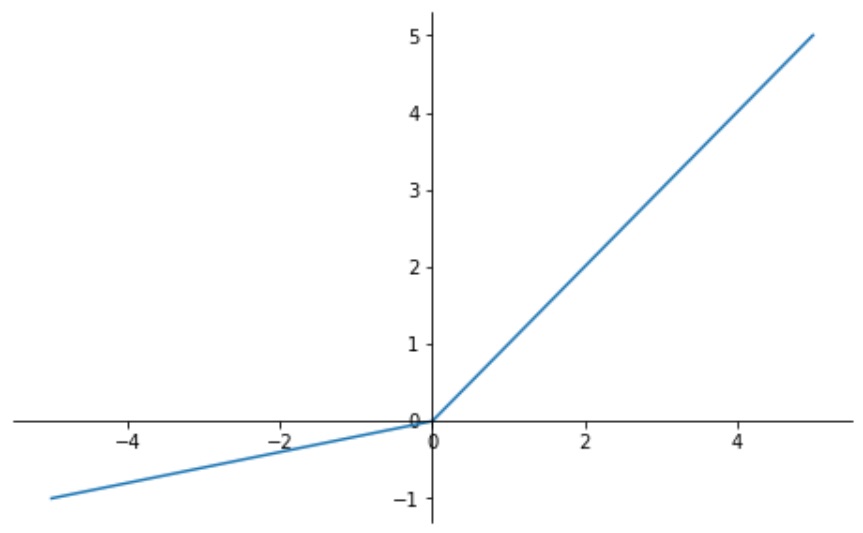
Exponential Linear Unit (ELU)
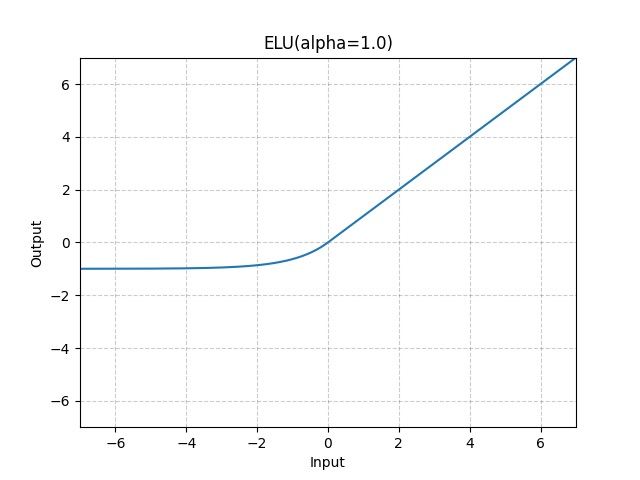
ELU là một biến thể khác của ReLU function mang lại độ mượt mà cao hơn. Với các giá trị âm, ELU sử dụng một hàm mũ, giúp giảm độ lệch trung bình (bias shift) của các giá trị đầu ra. ELU cũng được biết tới với khả năng tối ưu hóa, giúp các mô hình hội tụ nhanh hơn.
Công thức của ELU như sau:
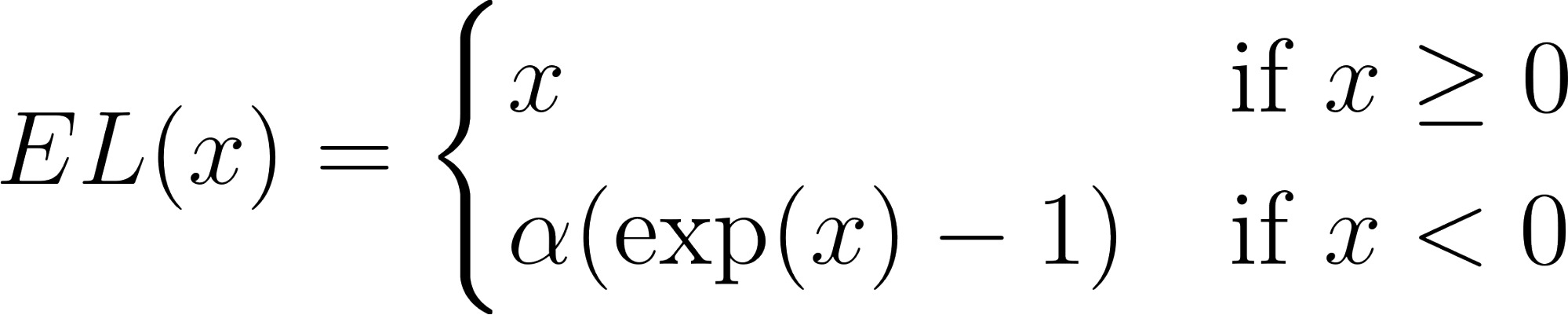
Trong đó α là một hằng số dương, thường được đặt bằng 1.
Ưu điểm và hạn chế của ReLU function
Ưu điểm
ReLU Function sở hữu nhiều ưu điểm nổi bật như:
- Tính toán nhanh chóng: ReLU chỉ cần một phép so sánh đơn giản (max(0, x)), giúp tiết kiệm tài nguyên và tối ưu hiệu suất trong các mạng nơ-ron sâu với hàng triệu tham số.
- Khả năng phi tuyến tính: Dù là hàm tuyến tính từng phần, ReLU vẫn duy trì tính phi tuyến cần thiết. Nhờ đó, mô hình có khả năng biểu diễn tốt hơn so với các hàm tuyến tính thuần túy.
- Giảm thiểu vấn đề mất gradient: Khác với các hàm khác như Sigmoid hay Tanh, ReLU giữ cho gradient ổn định với giá trị dương, từ đó khắc phục hiện tượng vanishing gradient.
- Tạo ra mạng thưa thớt: Khi nhận giá trị âm, ReLU sẽ trả về 0, tạo nên sự thưa thớt trong mạng. Nhờ vậy, quá trình tính toán trở nên hiệu quả và nhanh hơn, giảm thiểu tối đa chi phí.
- Tối ưu cho mạng sâu: Nhờ đặc tính đơn giản và ổn định trong tính toán, ReLU có thể hỗ trợ huấn luyện mạng nhiều lớp mà không làm tăng độ phức tạp tính toán.
Hạn chế
Bên cạnh lợi thế, ReLU vẫn tồn tại những điểm yếu cần lưu ý:
- Hiện tượng nơ-ron chết: Khi đầu vào âm lớn, nơ-ron có thể ngừng kích hoạt hoàn toàn. Kết quả trả về bằng 0 và đạo hàm cũng bằng 0, dẫn đến nơ-ron này sẽ không thể cập nhật trọng số trong quá trình huấn luyện và không thể học tiếp.
- Đầu ra không giới hạn: Do giá trị dương không bị chặn trên, mô hình dễ gặp vấn đề gradient bùng nổ, ảnh hưởng đến quá trình tối ưu.
- Gradient nhiễu: Nếu khởi tạo trọng số không hợp lý, gradient có thể dao động mạnh, làm chậm tốc độ học hoặc khiến mô hình mắc kẹt tại nghiệm kém tối ưu.
- Mất thông tin từ giá trị âm: Việc chuyển toàn bộ giá trị âm về 0 khiến mô hình không thể khai thác đầy đủ dữ liệu, buộc phải dùng đến các biến thể như Leaky ReLU hay PReLU để cải thiện.
Ứng dụng của ReLU function trong mạng neural và deep learning
Nhờ đặc tính đơn giản và hiệu quả, ReLU đã trở thành một phần quan trọng trong các mô hình học sâu hiện đại và được ứng dụng rộng rãi trong nhiều lĩnh vực như:
- Thị giác máy tính (Computer Vision): Vai trò của ReLU function trong Deep learning được thể hiện rõ ràng trong cấu trúc mạng tích chập (Convolutional Neural Networks - CNNs). Bằng cách đưa tính phi tuyến tính vào mạng, hàm ReLU giúp trích xuất nhanh các đặc trưng phức tạp của hình ảnh, từ đó nâng cao tính chính xác trong các tác vụ phân loại hình ảnh, nhận dạng vật thể,....
- Xử lý ngôn ngữ tự nhiên (Natural Language Understanding - NLP): ReLU được áp dụng để tăng tính phi tuyến cần thiết trong các kiến trúc như Mạng Nơ-ron Hồi quy (RNNs) và các mô hình Transformer. Điều này cho phép mô hình nắm bắt nhanh mối quan hệ phức tạp giữa các từ trong một chuỗi, tạo điều kiện cho các tác vụ nâng cao như nhận dạng giọng nói, xử lý âm thanh, và phân tích cảm xúc,...
- Hệ thống gợi ý: Trong hệ thống đề xuất, các mô hình học sâu sử dụng ReLU để mô hình hóa dữ liệu người dùng (sở thích, hành vi,...). Bằng cách xử lý hiệu quả lượng lớn dữ liệu phi tuyến tính, ReLU cho phép hệ thống tạo ra các đề xuất cá nhân hóa một cách nhanh chóng và chính xác, từ đó nâng cao trải nghiệm người dùng trên các nền tảng.

Kết luận
Qua bài viết trên đây của VNPT AI, có thể thấy hàm ReLU là một bước ngoặt quan trọng trong lĩnh vực học sâu. Nhờ công thức đơn giản nhưng hiệu quả, ReLU không chỉ rút ngắn thời gian tính toán mà còn khắc phục nhiều hạn chế của các hàm kích hoạt truyền thống. Chính điều đó đã khiến ReLU trở thành lựa chọn ưu tiên trong nhiều mô hình hiện nay, góp phần thúc đẩy sự phát triển của trí tuệ nhân tạo và các ứng dụng phức tạp.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá