
Speech synthesis: Công nghệ tổng hợp giọng nói và những ứng dụng đột phá trong kỷ nguyên số

 28/10/2025
28/10/2025
Speech synthesis là công nghệ tổng hợp giọng nói, thường được dùng trong trợ lý ảo, sách nói, tổng đài tự động, hỗ trợ người khiếm thị và nhiều ứng dụng khác.
Công nghệ tổng hợp giọng nói (Speech Synthesis) ngày càng quan trọng trong giao tiếp người – máy, với ứng dụng phổ biến nhất là Text-to-Speech (TTS), giúp chuyển văn bản thành giọng nói tự nhiên. Theo MarketsandMarkets, thị trường TTS toàn cầu có thể đạt 5 tỷ USD vào năm 2026, với CAGR 14,6%. Con số này cho thấy nhu cầu tích hợp giọng nói thông minh vào sản phẩm và dịch vụ đang tăng mạnh trên toàn cầu. Bài viết sau đây của VNPT AI sẽ giải thích chi tiết hơn về Speech synthesis cùng các xu hướng phát triển trong tương lai.
Speech synthesis là gì?
Speech synthesis là công nghệ mô phỏng giọng nói con người bằng máy tính hoặc phần mềm tiên tiến. Cụ thể, đây chính là quá trình chuyển đổi văn bản thành giọng nói nhân tạo, còn được biết đến với tên gọi phổ biến là text-to-speech. Chất lượng giọng nói nhân tạo phụ thuộc nhiều vào độ chính xác của mô hình ngôn ngữ và mô hình âm học được sử dụng trong quá trình tổng hợp. Thay vì "hiểu ngữ cảnh" như con người, hệ thống dựa vào khả năng học từ dữ liệu để tạo ra ngữ điệu, nhấn nhá và biểu cảm phù hợp với nội dung văn bản.

>>> Tìm hiểu thêm: Nhận diện giọng nói (Speech Recognition) là gì?
Speech synthesis khác gì so với Text-to-speech?
Speech synthesis và Text-to-Speech (TTS) thường được dùng thay thế cho nhau nhưng trên thực tế vẫn có một sự khác biệt nhỏ như sau:
- Speech synthesis: Là khái niệm rộng, bao gồm toàn bộ quá trình tạo ra giọng nói nhân tạo. Chúng không chỉ dừng ở việc chuyển văn bản thành lời nói, mà còn bao gồm các kỹ thuật tái tạo ngữ điệu, cảm xúc, nhịp điệu và âm sắc để giọng nói trở nên tự nhiên hơn.
- Text-to-Speech (TTS): Là một phần cụ thể trong Speech synthesis, chuyên xử lý việc chuyển đổi văn bản thuần túy thành âm thanh giọng nói. Đây là ứng dụng phổ biến nhất của Speech synthesis trong thực tế.
Nói cách khác, text-to-speech tập trung vào việc “đọc” văn bản thành âm thanh, còn Speech synthesis là khái niệm rộng hơn, đề cập đến tổng hợp giọng nói một cách toàn diện và tự nhiên hơn.
Nguyên lý hoạt động của Speech synthesis
Speech synthesis hoạt động theo ba giai đoạn chính: chuyển văn bản thành từ, từ thành âm vị (phonemes) và từ âm vị thành âm thanh.
Chuyển văn bản thành từ
Ở bước này, hệ thống sẽ xử lý và chuẩn hóa văn bản đầu vào (như viết tắt, chữ số, ký hiệu…) để tránh gây nhầm lẫn trong quá trình chuyển đổi thành giọng nói. Việc này bao gồm chuyển đổi các số, ngày tháng, từ viết tắt, ký hiệu đặc biệt thành dạng từ ngữ dễ đọc. Quá trình này cũng xử lý các từ đồng âm khác nghĩa - những từ có cách viết giống nhau nhưng cách phát âm khác nhau tùy theo ngữ cảnh. Các mô hình như Hidden Markov hoặc mạng nơ-ron được sử dụng để xác định cách phát âm phù hợp nhất.
Chuyển từ thành âm vị
Sau khi xác định được từ, hệ thống sẽ phân tách từ thành các âm vị - những đơn vị âm thanh nhỏ nhất cấu thành nên từ đó. Ngoài ra, có thể phân tích từ theo các đơn vị chữ viết (graphemes) rồi áp dụng quy tắc để chuyển các đơn vị này thành âm vị tương ứng.
Chuyển âm vị thành âm thanh
Có ba cách phổ biến để tổng hợp âm thanh từ các âm vị:
- Concatenative synthesis: Sử dụng các đoạn ghi âm giọng người đã được lưu sẵn để ghép nối lại thành câu nói.
- Formant synthesis: Tạo âm thanh bằng cách mô phỏng các đặc điểm cộng hưởng trong giọng nói, không dùng dữ liệu ghi âm.
- Articulatory synthesis: Mô phỏng cơ chế phát âm của hệ thanh quản con người để tạo giọng nói một cách chi tiết và tự nhiên.
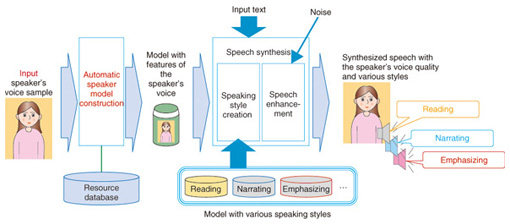
Các kỹ thuật tổng hợp giọng nói
Hiện nay, tổng hợp giọng nói thường dựa trên bốn kỹ thuật chính:
- Concatenative Synthesis (Tổng hợp nối ghép): Kỹ thuật này ghép nối các đoạn âm thanh đã được ghi âm từ giọng nói thật, sau đó xử lý để các đoạn nối liền mượt mà và tự nhiên hơn.
- Formant Synthesis (Tổng hợp cộng hưởng): Sử dụng các mô hình toán học để mô phỏng hoạt động của bộ phận phát âm trong cơ thể người, tạo ra âm thanh rõ ràng nhưng thường kém tự nhiên so với giọng thật.
- Articulatory Synthesis (Tổng hợp mô phỏng phát âm): Mô phỏng cách hoạt động của miệng, lưỡi và dây thanh quản khi phát âm giúp tạo ra giọng nói nhân tạo một cách chi tiết hơn.
- Deep Learning-Based Synthesis (Tổng hợp dựa trên học sâu): Áp dụng trí tuệ nhân tạo và mạng nơ-ron, sử dụng tập dữ liệu giọng nói quy mô lớn để học các mẫu nói tự nhiên, từ đó tạo ra giọng tổng hợp gần giống giọng người thật nhất.
Ứng dụng của công nghệ tổng hợp giọng nói
Công nghệ tổng hợp giọng nói đang thay đổi cách chúng ta giao tiếp, học tập và tương tác với thế giới số qua nhiều ứng dụng thiết thực như:
Công nghệ hỗ trợ người khuyết tật
Các nền tảng đầu tiên của công nghệ tổng hợp giọng nói bắt đầu xuất hiện từ cuối những năm 1960, nhưng phải đến thập niên 1980, TTS mới thực sự trở thành công cụ hỗ trợ hiệu quả cho người khuyết tật. Những hệ thống như Kurzweil Reading Machine hay DECtalk đã giúp người khiếm thị, người gặp khó khăn trong giao tiếp hoặc học tập có thể “nghe” được nội dung văn bản thông qua giọng nói nhân tạo. Hiện nay, công nghệ này đã được tích hợp trên hầu hết các thiết bị kỹ thuật số cá nhân. Nhờ đó, người dùng có thể tiếp cận thông tin một cách thuận tiện hơn. Đồng thời, nó cũng góp phần giảm bớt các rào cản trong giao tiếp.
Trợ lý ảo và thiết bị thông minh
Trợ lý ảo như Siri, Google Assistant hay Alexa sử dụng công nghệ tổng hợp giọng nói để giao tiếp với người dùng qua điện thoại, loa thông minh hay xe hơi. Với sự phát triển của trí tuệ nhân tạo, trợ lý ảo có thể tổng hợp giọng nói theo thời gian thực, mang đến trải nghiệm tự nhiên và sinh động hơn.
Giáo dục và đào tạo trực tuyến
Speech synthesis hỗ trợ tạo ra các nội dung đào tạo, video giảng dạy hoặc hướng dẫn sử dụng sản phẩm một cách nhanh chóng và hiệu quả. Trong môi trường doanh nghiệp, công nghệ này giúp cập nhật và truyền đạt các quy trình, chính sách mới dễ dàng hơn mà không tốn nhiều thời gian ghi âm thủ công.

Sáng tạo nội dung và marketing
Công nghệ tổng hợp giọng nói ngày càng trở thành công cụ quan trọng trong sáng tạo nội dung và tiếp thị. Với khả năng đa ngôn ngữ, các doanh nghiệp có thể mở rộng phạm vi tiếp cận khách hàng toàn cầu và cá nhân hóa trải nghiệm người dùng ở quy mô lớn.
Đặc biệt, các công nghệ tiên tiến như AI voice cloning cho phép tạo ra giọng nói mang đặc trưng của từng thương hiệu hoặc từng cá nhân, tạo sự gắn kết và nhận diện tốt hơn. Giọng nói giờ đây không chỉ "đọc" thông tin mà còn có thể truyền tải cảm xúc, ngữ điệu phù hợp với từng ngữ cảnh - từ quảng cáo đầy cảm hứng đến video giáo dục ấm áp, gần gũi.
Công nghệ này còn hỗ trợ sản xuất hàng loạt video, podcast, bản tin... một cách nhanh chóng, tiết kiệm chi phí mà vẫn đảm bảo chất lượng giọng nói tự nhiên, chân thực - điều mà trước đây cần đến thu âm phòng kín hoặc người lồng tiếng chuyên nghiệp.
Xu hướng phát triển của Speech synthesis trong tương lai
Công nghệ tổng hợp giọng nói đang bước vào giai đoạn chuyển mình mạnh mẽ nhờ sự phát triển của trí tuệ nhân tạo thế hệ mới. Các giải pháp như API video AI đang kết hợp giọng nói tự nhiên với khả năng tạo video theo thời gian thực. Nhờ đó, người dùng có thể tạo ra những trải nghiệm AI cá nhân hóa và sống động hơn, phù hợp với nhiều lĩnh vực như giáo dục, marketing, chăm sóc khách hàng và giải trí.
Nhờ đó, Speech synthesis không chỉ dừng lại ở việc chuyển văn bản thành giọng nói, mà còn mở rộng sang việc tạo ra các nội dung đa phương tiện như video có giọng nói tự động, avatar ảo phát biểu, hoặc bài giảng số có cảm xúc. Điều này giúp người dùng tương tác với máy móc theo cách trực quan và tự nhiên hơn bao giờ hết.
>>> Đọc thêm: Công cụ chuyển văn bản thành giọng nói
Kết luận
Qua bài viết của VNPT AI có thể thấy, Speech synthesis đang góp phần thu hẹp khoảng cách giữa con người và công nghệ, mang lại trải nghiệm giao tiếp tự nhiên và giàu cảm xúc hơn. Với sự phát triển mạnh mẽ của trí tuệ nhân tạo và các kỹ thuật tổng hợp giọng nói tiên tiến, Speech synthesis hứa hẹn sẽ ngày càng trở nên tự nhiên, đa dạng và ứng dụng sâu rộng hơn trong nhiều lĩnh vực khác nhau.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá