
Tokenization là gì? Khám phá cách hoạt động và ứng dụng

 13/03/2025
13/03/2025
Tokenization là một bước quan trọng trong Xử lý Ngôn ngữ Tự nhiên, đóng vai trò nền tảng giúp máy tính hiểu và phân tích văn bản.
Theo MarketsandMarkets, thị trường tokenization toàn cầu dự kiến sẽ tăng từ 2,3 tỷ USD năm 2021 lên 5,6 tỷ USD vào năm 2026, cho thấy tầm quan trọng của các giải pháp tokenization ngày càng lớn. Không chỉ dừng lại ở việc tách câu thành từ, tokenization còn là một bước quan trọng trong NLP (Natural Language Processing), giúp phân tích ngữ nghĩa, cảm xúc và ngữ cảnh của văn bản. Trong bài viết này, VNPT AI sẽ giải đáp chi tiết cho bạn về "Tokenization là gì", cách thức hoạt động cùng xu hướng phát triển của Tokenization trong tương lai.
Tokenization là gì?
Ngày nay, khái niệm Tokenization đã trở nên khá phổ biến, thường xuyên được nhắc tới trong rất nhiều lĩnh vực quan trọng như bảo mật dữ liệu (bảo vệ dữ liệu thẻ tín dụng, thông tin tài khoản ngân hàng), Tiền điện tử, hay quản lý quyền truy cập,... và đặc biệt là trong NLP.
Tokenization là quá trình chia nhỏ văn bản thành các đơn vị nhỏ hơn gọi là token. Trong lĩnh vực Xử lý Ngôn ngữ tự nhiên (NLP), token có thể là các từ, cụm từ, hoặc thậm chí là các phần nhỏ hơn của từ, tùy thuộc vào cách thức phân tách.
Tokenization đóng vai trò như một bước đầu tiên và nền tảng trong quy trình NLP. Nó giúp phân tách văn bản chưa cấu trúc thành các phần nhỏ dễ hiểu hơn, từ đó có thể được sử dụng cho các tác vụ khác như phân tích văn bản, tạo mô hình ngôn ngữ, dịch máy, và nhiều ứng dụng NLP khác. Ví dụ, trong một câu văn, mỗi từ có thể được coi là một token và mỗi câu có thể là một token trong đoạn văn.
Sau khi văn bản đã được phân tách thành các token, chúng có thể được sử dụng như các đặc trưng (features) trong các mô hình học máy giúp máy tính đưa ra các quyết định và phản ứng thông minh hơn.
Cách thức hoạt động của Tokenization NLP
Tokenization trong NLP có vai trò chia nhỏ các đoạn văn bản thô thành những đơn vị nhỏ hơn dễ hiểu và có thể phân tích được như từ hoặc cụm từ, quá đó giúp máy tính có thể hiểu được và xử lý chính xác. Vậy cụ thể, cách thức hoạt động của Tokenization là gì?
Tokenization bắt đầu khi máy tính nhận được một chuỗi dữ liệu, chẳng hạn như một câu văn. Mục tiêu là phân tách câu này thành những phần có nghĩa để máy tính có thể hiểu rõ từng phần trong câu cũng như toàn bộ câu.
Ví dụ, xét câu sau: "Tokenization in NLP":
Để máy tính có thể hiểu câu này, tokenization sẽ phân tách nó thành các từ riêng biệt như sau: ["Tokenization", "in", "NLP"].
Mặc dù việc chia câu thành từng từ có vẻ đơn giản nhưng chính việc phân tách này lại cho phép máy tính hiểu rõ hơn về mỗi từ riêng biệt, cũng như cách mà chúng kết hợp và tương tác trong ngữ cảnh câu. Điều này đặc biệt quan trọng khi xử lý văn bản dài, vì máy tính có thể đếm được tần suất xuất hiện của các từ và xác định các vị trí mà các từ này xuất hiện thường xuyên.
Các loại Tokenization phổ biến
Có nhiều phương pháp tokenization khác nhau trong NLP, mỗi phương pháp có ưu điểm và nhược điểm riêng, phù hợp với từng bài toán cụ thể. Cùng tìm hiểu về cách thức và đặc điểm của từng loại Tokenization là gì nhé!
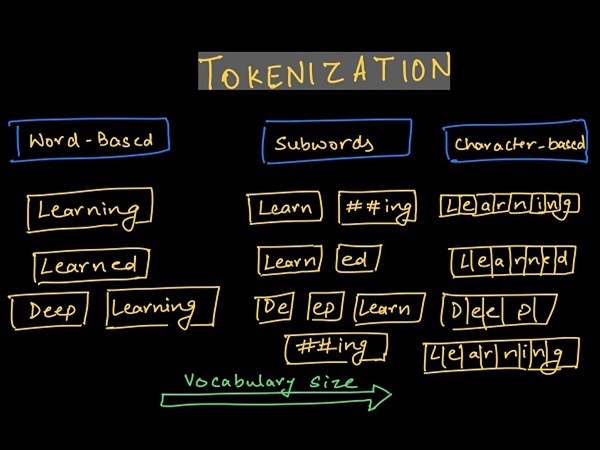
Phân tách theo từ (Word Tokenization)
Phân tách theo từ (Word Tokenization) là một trong các loại Tokenization phổ biến nhất trong NLP. Phương pháp này được ứng dụng trong khá nhiều tác vụ như: Dự đoán từ tiếp theo dựa trên ngữ cảnh, Phân tích và phân loại văn bản,...
Vậy cụ thể phương pháp Word Tokenization là gì và nó hoạt động như thế nào? Trên thực tế, Word Tokenization chia một đoạn văn bản thành các từ riêng biệt, dựa vào các dấu phân cách tự nhiên như khoảng trắng, dấu chấm câu hoặc các ký tự đặc biệt khác. Ví dụ, câu "Các nhà hàng gần đây" sẽ được phân tách thành các từ: 'Các', 'nhà', 'hàng', 'gần', 'đây'.
Mặc dù đây là kỹ thuật đơn giản và dễ hiểu nhưng vẫn tồn tại một số hạn chế khi phải xử lý các từ không có trong từ điển (OOV - Out of Vocabulary) hoặc các từ không rõ ràng, sai chính tả. Để giải quyết vấn đề này, phương pháp tokenization sẽ sử dụng kỹ thuật mã hóa dựa trên ký tự.

Phân tách theo câu (Sentence Tokenization)
Phân tách theo câu (Sentence Tokenization) là kỹ thuật tách văn bản thành các câu riêng biệt. Đây là bước quan trọng trong quá trình tiền xử lý văn bản giúp máy tính hiểu được cấu trúc câu và phân tích ngữ nghĩa chính xác hơn. Phương pháp này thường sử dụng các dấu câu như dấu chấm, dấu chấm hỏi hoặc dấu chấm than để xác định các câu.
Phân tách theo ký tự (Character Tokenization)
Phân tách theo ký tự (Character Tokenization) chia văn bản thành các ký tự riêng lẻ thay vì các từ. Kỹ thuật này giúp giải quyết một số vấn đề mà phân tách theo từ gặp phải như việc xử lý các từ không có trong từ điển hay các từ sai chính tả. Ví dụ, câu "Các nhà hàng gần đây" khi áp dụng phân tách theo ký tự sẽ trở thành: 'C', 'á', 'c', ' ', 'n', 'h', 'à', ' ', ...
Điều này giúp giảm thiểu tình trạng OOV nhưng cũng làm tăng độ dài của văn bản sau khi phân tách, vì mỗi từ sẽ bị chia thành nhiều ký tự. Điều này có thể dẫn đến việc xử lý văn bản khá cồng kềnh và tốn tài nguyên hơn, đặc biệt khi văn bản dài hoặc phức tạp. Ngoài ra, phân tách theo ký tự còn có thể khiến cho việc hiểu câu và ngữ cảnh trở nên khó khăn hơn.
Phân tách theo từ phụ (Subword Tokenization)
Phân tách theo từ phụ (Subword Tokenization) là một phương pháp kết hợp ưu điểm của phân tách theo từ và phân tách theo ký tự. Thay vì chia văn bản thành các từ hoàn chỉnh, phương pháp này chia các từ thành các đơn vị nhỏ hơn như tiền tố (prefix), hậu tố (suffix) hoặc các phần gốc của từ.
Ví dụ, câu "What is the tallest building?" có thể được chia thành các phần: 'what', 'is', 'the', 'tall', 'est', 'ing'.
Phương pháp này giúp giảm bớt kích thước từ vựng so với phân tách theo từ, đồng thời giúp mô hình có thể hiểu được các từ chưa gặp trước đó (OOV) bằng cách kết hợp các phần từ đã học. Subword Tokenization thường được sử dụng trong các mô hình hiện đại như BERT, GPT-2 và nhiều các mô hình khác, tăng hiệu quả xử lý các ngôn ngữ phức tạp.
Lợi ích nổi bật của Tokenization
Nhờ vào việc áp dụng các phương pháp tokenization hiệu quả, các mô hình NLP có thể cải thiện khả năng xử lý ngôn ngữ của máy tính. Vậy, những lợi ích của Tokenization là gì? Cùng tìm hiểu chi tiết sau đây:
Phân tích văn bản hiệu quả hơn
Tokenization giúp chia nhỏ các câu văn phức tạp thành các phần đơn giản hơn, từ đó giúp dễ dàng phân tích và hiểu được ngữ nghĩa của văn bản. Điều này hỗ trợ rất lớn khi hệ thống cần hiểu sâu về cấu trúc câu, ngữ nghĩa của các từ hoặc mối quan hệ giữa các từ trong văn bản.
Cải thiện quá trình tiền xử lý NLP
Tokenization là một bước quan trọng trong quá trình chuẩn hóa các dữ liệu đầu vào giúp quá trình huấn luyện mô hình học máy (machine learning) trở nên hiệu quả hơn. Khi dữ liệu được phân tách thành các token rõ ràng, mô hình dễ dàng tiếp nhận và xử lý, từ đó nâng cao độ chính xác và hiệu quả của các thuật toán.
Tính linh hoạt
Tokenization có thể được áp dụng cho nhiều ngôn ngữ và định dạng khác nhau, góp phần khiến quá trình xử lý ngôn ngữ tự nhiên trở nên linh hoạt, dễ dàng và tùy chỉnh cho các ứng dụng cụ thể. Đây là một yếu tố quan trọng khi làm việc với các ngôn ngữ đa dạng và các loại văn bản khác nhau.

Quản lý dữ liệu hiệu quả
Tokenization giúp tổ chức văn bản thành các đơn vị riêng biệt, giúp các mô hình NLP quản lý và xử lý các tập dữ liệu lớn trở nên dễ dàng hơn. Việc phân tách văn bản thành các token cũng giúp các mô hình học máy và các ứng dụng NLP có thể xử lý một cách mượt mà, hiệu quả hơn.
Tăng độ chính xác trong việc hiểu ngữ nghĩa
Bằng cách tách văn bản thành các đơn vị nhỏ, tokenization giúp các thuật toán NLP cải thiện độ chính xác trong các tác vụ như phân tích cảm xúc, mô hình hóa chủ đề, nhận diện thực thể, v.v. Việc phân tách rõ ràng giúp máy tính hiểu sâu hơn về ngữ nghĩa và mối quan hệ giữa các phần trong văn bản.
Thách thức và hạn chế của Tokenization
Tương tự như các công cụ khác, bên cạnh những thế mạnh thì tokenization vẫn còn tồn tại một số hạn chế mà các nhà phát triển đang tìm kiếm hướng giải quyết:
Mơ hồ về từ vựng
Quá trình tokenization thường gặp khó khăn với các từ vựng đồng nghĩa, chẳng hạn như từ “lead” động từ là hành động dẫn dắt nhưng danh từ có nghĩa là kim loại. Việc token hóa đúng ngữ nghĩa của từ đòi hỏi mức độ hiểu rõ ngữ cảnh và đây vẫn là “bài toán” khó cho các mô hình tokenization hiện tại.
Khó khăn khi xử lý các từ "Out-of-Vocabulary" (OOV)
Tokenization trong NLP trước đây gặp nhiều kho khăn khi xử lý các từ không có trong từ điển (OOV) hoặc chưa từng thấy trước đó. Mặc dù hiện nay các kỹ thuật tokenization như BPE (Byte Pair Encoding) đã giải quyết phần nào vấn đề này nhưng vẫn cần tiếp tục hoàn thiện hơn.
Tokenization trong môi trường đa ngôn ngữ
Việc thực hiện tokenization trở nên khó khăn hơn khi xử lý các mô hình đa ngôn ngữ. Vì các ngôn ngữ có cấu trúc ngữ pháp, từ vựng và cách tạo ra từ ngữ khác nhau, nên không thể áp dụng một phương pháp tokenization chung cho tất cả các ngôn ngữ.
Ký tự đặc biệt và Emoji
Trong các văn bản trực tuyến, việc sử dụng emoji và các ký tự đặc biệt ngày càng phổ biến. Để các mô hình NLP có thể hiểu và phân tích chính xác những yếu tố này, đòi hỏi các phương pháp tokenization cần phải linh hoạt và có khả năng xử lý những ký tự không phải chữ cái hoặc số.
Hình thái học và từ ghép
Một số ngôn ngữ như tiếng Đức có những từ ghép dài, ví dụ như từ “Donaudampfschifffahrtsgesellschaftskapitän” (thuyền trưởng của công ty tàu hơi nước sông Danube) không thể xử lý tách nhỏ bằng phương pháp tokenization thông thường vì chúng chứa nhiều ý nghĩa trong một từ duy nhất.
Hiệu suất và tốc độ
Tokenization là bước đầu tiên trong quy trình NLP nên cần phải diễn ra nhanh chóng, hiệu quả. Nếu quá trình này bị gián đoạn, nó sẽ gây tắc nghẽn toàn bộ quy trình học máy, làm giảm hiệu quả và tốc độ xử lý của mô hình này.

Nhận thức theo ngữ cảnh
Các công cụ tokenization hiện nay còn hạn chế trong việc hiểu được ngữ cảnh của từ trong câu, dẫn đến trường hợp phân tích sai nghĩa của các từ hoặc cụm từ có nhiều nghĩa khác nhau. Ví dụ, một từ có thể có nhiều nghĩa tùy thuộc vào ngữ cảnh giao tiếp và tokenization chưa thể phân biệt và xử lý tốt từng trường hợp. Tuy nhiên với các mô hình NLP hiện đại như transformer-based models, vấn đề này có thể được giải quyết thông qua kỹ thuật embeddings và cơ chế attention, giúp mô hình hiểu sâu hơn về nghĩa của từ trong từng bối cảnh cụ thể.
Ứng dụng thực tế của Tokenization
Tokenization rất cần thiết trong nhiều ứng dụng công nghệ và công nghiệp, giúp nâng cao hiệu quả trong việc phân tích và hiểu dữ liệu. Dưới đây là một số ứng dụng của Tokenization:
Tiền xử lý NLP
Tokenization là bước nền tảng trong việc chuẩn bị dữ liệu văn bản cho các phân tích tiếp theo. Nhờ vào việc chia nhỏ văn bản, các thuật toán có thể xử lý ngôn ngữ với độ chính xác cao hơn, giúp việc phân tích dữ liệu trở nên dễ dàng và hiệu quả hơn.
Phân tích cảm xúc
Thông qua việc phân tách văn bản thành các token, tokenization đóng vai trò quan trọng trong quá trình phân tích cảm xúc của các bài review, đánh giá sản phẩm hoặc bài đăng trên mạng xã hội. Điển hình như trong một hệ thống phân tích cảm xúc cho nền tảng thương mại điện tử, các đánh giá của người dùng sẽ được token hóa để xác định xem người dùng đang bày tỏ cảm xúc tích cực, trung lập hay tiêu cực. Qua đó, thương hiệu có thể nắm bắt được thái độ của khách hàng và đưa ra chiến lược ứng phó kịp thời.
Ví dụ: Đánh giá: "Sản phẩm này tuyệt vời, nhưng giao hàng thì chậm." Sau khi token hóa: ["Sản", "phẩm", "này", "tuyệt", "vời", ",", "nhưng", "giao", "hàng", "thì", "chậm", "."]. Các token "tuyệt vời" và "chậm" sẽ được xử lý để gán nhãn cảm xúc hỗn hợp, từ đó cung cấp thông tin có giá trị cho các doanh nghiệp.
Tìm kiếm thông tin
Tokenization có ý nghĩa quan trọng trong việc lập chỉ mục và tìm kiếm dữ liệu văn bản. Nhờ vào việc phân tách văn bản thành các token, các công cụ tìm kiếm như Google, CocCoc,… có thể xử lý và tìm ra kết quả chính xác hơn khi người dùng nhập các truy vấn tìm kiếm.
Dịch máy
Trong việc dịch văn bản từ ngôn ngữ này sang ngôn ngữ khác, tokenization giúp xác định các cụm từ và nghĩa chính xác của chúng. Bằng cách chia văn bản thành các token, các công cụ dịch máy như Google Translate có thể dịch các phần riêng lẻ rồi ghép lại thành văn bản hoàn chỉnh, chính xác hơn.
>>> Có thể bạn quan tâm: Machine Translation là gì? Khám phá các lợi ích và ứng dụng của dịch máy
Phát triển Chatbot AI
Tokenization giúp chatbot AI hiểu và trả lời các câu hỏi của người dùng hiệu quả hơn. Ví dụ, khi người dùng yêu cầu một chatbot AI cung cấp thông tin hoặc hỗ trợ, chatbot sẽ sử dụng tokenization để phân tích và xác định yêu cầu của người dùng, từ đó đưa ra câu trả lời chính xác.
Ví dụ, một chatbot AI hỗ trợ khách hàng có thể token hóa câu hỏi sau: "Tôi muốn biết về Tokenization là gì"
Câu này sẽ được token hóa thành: ["Tôi", "muốn", "biết", "Tokenization", "là", "gì"].
Việc phân tách này giúp chatbot ai hiểu được mục đích của người dùng ("tìm hiểu về Tokenization") và trả lời phù hợp, chẳng hạn như cung cấp liên kết hoặc hướng dẫn.

Nhận diện giọng nói
Các trợ lý giọng nói như Siri và Alexa phụ thuộc rất nhiều vào tokenization. Khi bạn đưa ra yêu cầu hoặc câu hỏi, những lời nói của bạn sẽ được chuyển thành văn bản. Sau đó, văn bản này sẽ được token hóa giúp hệ thống hiểu và thực hiện yêu cầu của bạn.
>>> Xem thêm: Nhận diện giọng nói là gì? 5 phần mềm Speech Recognition nổi bật nhất hiện nay
Xu hướng phát triển của Tokenization trong tương lai
Với sự phát triển không ngừng của NLP và học máy, tokenization sẽ tiếp tục là một phần quan trọng trong quy trình xử lý ngôn ngữ tự nhiên. Tuy nhiên, thay vì chỉ dừng lại ở việc chia văn bản thành các token như trước đây, các kỹ thuật tokenization trong tương lai có thể trở nên linh hoạt và tối ưu hơn.
Không chỉ đơn thuần là tách từ hoặc ký tự, các phương pháp tokenization mới sẽ hướng đến mục tiêu mã hóa văn bản sao cho mô hình có thể nắm bắt tốt hơn ý nghĩa, sắc thái cảm xúc và ngữ cảnh. Điều này giúp thu hẹp khoảng cách giữa cách con người sử dụng ngôn ngữ và cách máy móc xử lý văn bản, mở ra những tiềm năng lớn trong việc ứng dụng NLP vào thực tế.
Trong tương lai, các mô hình NLP có thể kết hợp tokenization một cách mượt mà hơn, giảm bớt nhu cầu xử lý dữ liệu trước (preprocessing) và giúp các mô hình “hiểu” ngôn ngữ một cách tự nhiên, chính xác hơn. Điều này đồng nghĩa với việc các mô hình xử lý ngôn ngữ sẽ trở nên mạnh mẽ hơn, có khả năng thích nghi với nhiều kiểu dữ liệu hơn và đưa ra những phản hồi chính xác hơn trong các tình huống phức tạp.
Ngoài ra, với tốc độ đổi mới công nghệ ngày càng nhanh, các phương pháp tokenization trở nên tinh vi và linh hoạt hơn. Điều này sẽ mở ra cơ hội cho các nhà phát triển học máy có thể giải quyết các bài toán ngôn ngữ phức tạp, áp dụng được cho nhiều lĩnh vực và ngôn ngữ khác nhau.
Kết luận
Nhìn chung, Tokenization là một bước không thể thiếu trong quá trình xử lý ngôn ngữ tự nhiên (NLP), đóng vai trò quan trọng trong việc giúp các hệ thống AI hiểu và phân tích văn bản một cách chính xác. Mặc dù vẫn tồn tại những thách thức nhất định, đặc biệt là khi xử lý các ngôn ngữ phức tạp nhưng với sự phát triển liên tục của công nghệ, tokenization hứa hẹn sẽ ngày càng hoàn thiện và mở rộng ứng dụng trong nhiều lĩnh vực khác nhau. Mong rằng với những chia sẻ từ VNPT AI đã giúp bạn hiểu rõ Tokenization là gì và có được cái nhìn sâu sắc hơn về các công nghệ, tiềm năng phát triển của Tokenization trong tương lai.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan
.jpg)



.jpg)