
Data Mining là gì? Quy trình và các kỹ thuật của khai phá dữ liệu

 22/01/2025
22/01/2025
Trong kỷ nguyên số hóa, Data Mining (khai phá dữ liệu) nổi lên như một công cụ mạnh mẽ, cho phép chuyển hóa dữ liệu thô thành tri thức và giá trị thực tiễn.
Trong kỷ nguyên số hóa, dữ liệu không chỉ đơn thuần là những con số khô khan mà đã trở thành nguồn tài nguyên chiến lược, chứa đựng những giá trị tiềm ẩn. Tuy nhiên, để biến dữ liệu thô sơ thành thông tin có ý nghĩa, chúng ta cần đến Data Mining - một lĩnh vực tiên tiến giúp khai mở những tri thức ẩn sâu trong khối dữ liệu khổng lồ. Vậy Data Mining là gì, và vì sao nó được xem là chìa khóa của sự đổi mới? Hãy cùng tìm hiểu quy trình, kỹ thuật và ứng dụng thực tế của khai phá dữ liệu để khám phá cách công nghệ này đang định hình tương lai của mọi ngành nghề trong bài viết dưới đây của VNPT AI!
Data Mining là gì?
Data Mining (khai phá dữ liệu) là một phần của quá trình Khám phá Tri thức trong Cơ sở dữ liệu (Knowledge Discovery in Databases), tập trung vào nhiệm vụ phân tích và xử lý một lượng lớn dữ liệu thô để nhận diện các mẫu, xu hướng, mối tương quan hoặc thông tin hữu ích ẩn sâu trong dữ liệu. Quá trình này không chỉ giúp phát hiện những tri thức tiềm ẩn mà còn mở ra các giá trị thực tiễn cho doanh nghiệp và tổ chức trong thời đại số.
Để thực hiện Data Mining, các công cụ hiện đại như trí tuệ nhân tạo (AI) và học máy (ML) thường được tích hợp để phân tích dữ liệu thông qua các thuật toán phức tạp. Chẳng hạn, dữ liệu được chia nhỏ thành các phần, sau đó hệ thống tìm kiếm mối quan hệ hoặc sự bất thường giữa các phần dữ liệu. Phương pháp này có thể xác định các xu hướng và mẫu mà con người khó có khả năng nhận diện, từ đó hỗ trợ ra quyết định hiệu quả hơn.

Các kỹ thuật khai phá dữ liệu (Data Mining)
Các kỹ thuật khai phá dữ liệu được áp dụng nhằm phân tích, trích xuất và tổ chức thông tin một cách hiệu quả. Dưới đây là một số phương pháp khai phá dữ liệu quan trọng và phổ biến:
Kỹ thuật phân tích phân loại - Classification Analysis
Phân loại là một trong các kỹ thuật khai phá dữ liệu được ứng dụng rộng rãi nhất, cho phép nhóm một đối tượng vào các lớp đã xác định sẵn dựa trên những thuộc tính cụ thể. Kỹ thuật này thường được sử dụng để trích xuất các thông tin quan trọng từ dữ liệu, phục vụ cho việc đưa ra các dự đoán hoặc phân tích xu hướng.
Ví dụ, Gmail sử dụng thuật toán phân loại để xác định một email là hợp pháp hay spam. Hoặc trong quảng cáo - tiếp thị, marketers có thể phân loại khách hàng dựa trên độ tuổi, sở thích hoặc hành vi mua sắm, từ đó tối ưu hóa chiến lược tiếp cận theo hướng phù hợp hơn, đảm bảo hiệu quả tiếp thị tốt nhất.
Kỹ thuật học luật kết hợp - Association Rule Learning
Kỹ thuật này tập trung vào việc tìm kiếm mối liên hệ giữa các biến trong cơ sở dữ liệu, giúp phát hiện các mẫu ẩn tiềm năng. Đây là phương pháp khai phá dữ liệu lý tưởng để kiểm tra và dự đoán hành vi mua sắm của khách hàng trong lĩnh vực bán lẻ.
Ví dụ, thông qua phân tích thông tin giỏ hàng, thuật toán các sàn thương mại điện tử có thể xác định rằng khách hàng thường mua kèm cushion với kem che khuyết điểm. Từ đó, họ có thể triển khai các chương trình khuyến mãi phù hợp hoặc đề xuất mặt hàng kem che khuyết điểm bán chạy nhất sau khi khách hàng bỏ giỏ hàng sản phẩm cushion để kích thích lượt mua. Ngoài ra, trong lĩnh vực công nghệ, kỹ thuật này thường được sử dụng để phát triển các thuật toán Machine Learning.

Kỹ thuật phát hiện bất thường - Anomaly Detection
Kỹ thuật phát hiện bất thường trong Data Mining tập trung vào việc tìm kiếm những điểm dữ liệu khác biệt hoặc ngoại lệ trong tập dữ liệu. Đây là công cụ đắc lực để phát hiện các vấn đề tiềm ẩn, chẳng hạn như gian lận tài chính, xâm nhập hệ thống, hoặc các biến động bất thường trong dữ liệu kinh doanh.
Ví dụ, trong lĩnh vực sản xuất, kỹ thuật này có thể được dùng để theo dõi dây chuyền sản xuất tự động, trường hợp phát hiện dấu hiệu bất thường, hệ thống sẽ báo lại với người điều hành. Hoặc trong lĩnh vực bảo mật, kỹ thuật này cũng được ứng dụng để phát giác các cuộc tấn công nguy hiểm có thể xảy ra, qua đó giúp ngăn chặn sớm nhất.
Kỹ thuật phân tích cụm - Clustering Analysis
Phân cụm là một trong các phương pháp khai phá dữ liệu giúp nhóm các đối tượng tương đồng thành từng cụm. Các đối tượng trong cùng một cụm sẽ có đặc điểm chung, hỗ trợ việc phân tích dữ liệu và ra quyết định.
Ví dụ, Trong marketing, kỹ thuật này thường được sử dụng để phân khúc khách hàng thành các nhóm có đặc điểm chung giống nhau, giúp doanh nghiệp hiểu rõ hơn về nhu cầu của từng nhóm khách hàng cụ thể. Ngoài ra, nó còn được áp dụng để xây dựng hồ sơ khách hàng trong các ngành bán lẻ, tài chính - ngân hàng để có phương án chăm sóc và tiếp cận phù hợp.
Kỹ thuật phân tích hồi quy - Regression Analysis
Hồi quy là một kỹ thuật quan trọng giúp xác định và phân tích mối quan hệ giữa các biến. Phương pháp này thường được dùng để dự đoán giá trị liên tục, chẳng hạn như doanh thu, chi phí hoặc nhu cầu trong tương lai.
Ví dụ, một doanh nghiệp sản xuất ứng dụng các phương pháp khai phá dữ liệu hồi quy để dự đoán doanh thu và lợi nhuận thu về từ số sản phẩm bán được ra thị trường. Công cụ này cho phép doanh nghiệp có thể kiểm soát dễ dàng chi phí bỏ ra và thu về, hỗ trợ doanh nghiệp hiệu quả trong việc lên kế hoạch và xây dựng chiến lược dài hạn.
Kỹ thuật dự báo - Prediction
Dự báo là một kỹ thuật khai phá dữ liệu đặc biệt, giúp phát hiện mối quan hệ giữa các biến độc lập và phụ thuộc để đưa ra dự đoán trong tương lai. Ví dụ, trong kinh doanh, dự báo doanh số có thể dựa trên xu hướng mua sắm hiện tại của khách hàng. Phương pháp này không chỉ giúp các doanh nghiệp tối ưu hóa nguồn lực mà còn cải thiện khả năng đáp ứng nhu cầu thị trường.

>>> Có thể bạn quan tâm: Predictive Analytics là gì? Giải pháp phân tích dự đoán trong tương lai
Kỹ thuật khám phá mẫu tuần tự - Sequential Pattern Mining
Kỹ thuật này được dùng để nhận diện các mẫu hoặc chuỗi sự kiện lặp đi lặp lại trong dữ liệu theo thời gian. Ví dụ, trong ngành bán lẻ, việc phát hiện các mặt hàng thường được mua cùng nhau theo mùa có thể giúp doanh nghiệp cải thiện chiến lược tiếp thị và quản lý hàng tồn kho.
Kỹ thuật cây quyết định hay Decision Trees
Cây quyết định là một phương pháp khai phá dữ liệu trực quan và dễ hiểu trong Data Mining, giúp phân tích và ra quyết định thông qua một loạt câu hỏi và câu trả lời.
Ví dụ, trong lĩnh vực tài chính, cây quyết định có thể được sử dụng để xác định khả năng chấp nhận một khoản vay dựa trên các thông tin như thu nhập, lịch sử tín dụng và độ tuổi của khách hàng.
Quy trình khai phá dữ liệu
Dưới đây là các bước chính trong quy trình khai phá dữ liệu:
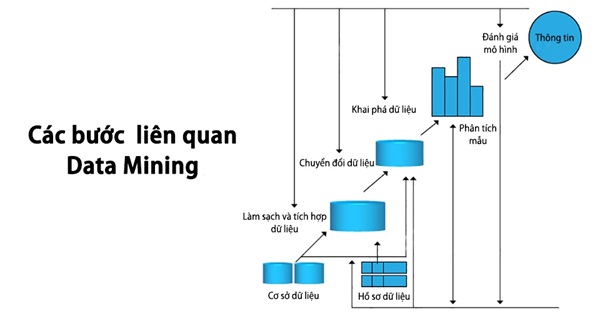
Bước 1: Làm sạch dữ liệu (Data Cleaning)
Dữ liệu thô thường chứa nhiều yếu tố không phù hợp, chẳng hạn như thông tin thiếu, dữ liệu nhiễu, hoặc lỗi định dạng. Bước đầu tiên trong quy trình khai phá dữ liệu là làm sạch dữ liệu, loại bỏ tạp âm để đảm bảo độ chính xác và nhất quán của bộ dữ liệu.
Ví dụ, trong dữ liệu khách hàng, thông tin không đầy đủ như số điện thoại hoặc email bị lỗi sẽ được loại bỏ hoặc sửa chữa để tránh ảnh hưởng đến kết quả phân tích.
Bước 2: Tích hợp các nguồn dữ liệu (Data Integration)
Ở bước này, các nguồn dữ liệu khác nhau sẽ được tích hợp lại thành một tập dữ liệu thống nhất. Điều này giúp xử lý dữ liệu hiệu quả hơn, đồng thời cung cấp cái nhìn toàn diện về thông tin.
Chẳng hạn, doanh nghiệp có thể kết hợp dữ liệu từ hệ thống CRM, dữ liệu giao dịch bán hàng, và dữ liệu truyền thông xã hội để phân tích hành vi khách hàng một cách đầy đủ hơn.
Bước 3: Lựa chọn dữ liệu (Data Selection)
Không phải tất cả dữ liệu thu thập được đều cần thiết. Trong bước này, dữ liệu liên quan đến mục tiêu phân tích sẽ được chọn lọc để giảm thiểu thời gian và chi phí xử lý.
Ví dụ, nếu doanh nghiệp muốn phân tích hành vi mua sắm của khách hàng, chỉ cần chọn dữ liệu giao dịch và hành vi tiêu dùng, thay vì toàn bộ dữ liệu khách hàng.
Bước 4: Chuyển đổi dữ liệu (Data Transformation)
Sau khi được chọn lọc, dữ liệu sẽ được chuyển đổi thành định dạng phù hợp để phân tích. Quá trình này có thể bao gồm việc tổng hợp dữ liệu, chuẩn hóa hoặc mã hóa thông tin để dễ dàng xử lý hơn.
Ví dụ, doanh nghiệp có thể chuyển đổi dữ liệu ngày tháng từ định dạng văn bản thành định dạng số để sử dụng trong mô hình dự báo.

Bước 5: Tiến hành khai phá dữ liệu (Data Mining)
Đây là bước trọng tâm trong quy trình và trả lời rõ ràng câu hỏi khai thác dữ liệu. Ở giai đoạn này, các kỹ thuật khai phá dữ liệu như phân cụm, phân loại, hồi quy, hoặc phát hiện bất thường sẽ được áp dụng để trích xuất thông tin có giá trị từ tập dữ liệu.
Chẳng hạn, sử dụng thuật toán phân loại để xác định nhóm khách hàng tiềm năng hoặc phát hiện các giao dịch gian lận trong lĩnh vực tài chính.
Bước 6: Đánh giá mẫu (Pattern Evaluation)
Sau khi trích xuất dữ liệu, các mẫu được phát hiện cần được đánh giá để xác định giá trị thực tiễn. Điều này đảm bảo rằng thông tin được chọn lọc phù hợp với mục tiêu phân tích và có thể áp dụng hiệu quả vào thực tế.
Ví dụ, nếu phát hiện một mẫu tiêu dùng cho thấy khách hàng thường mua sản phẩm A và B cùng nhau, doanh nghiệp có thể cân nhắc tạo ra các gói ưu đãi đi kèm để tăng doanh số.
Bước 7: Trình bày thông tin (Knowledge Presentation)
Bước cuối cùng là trình bày thông tin một cách trực quan và dễ hiểu. Các mẫu và xu hướng phát hiện được thể hiện thông qua các công cụ như biểu đồ, bảng, hoặc ma trận, giúp người dùng cuối dễ dàng tiếp cận và đưa ra quyết định.
Ví dụ, sử dụng biểu đồ cột để minh họa xu hướng tăng trưởng doanh số hoặc bảng phân tích để so sánh hiệu suất của các chiến dịch marketing.
Ưu nhược điểm của Data Mining
Dưới đây là một số ưu nhược điểm cụ thể của Data Mining:
Ưu điểm của khai phá dữ liệu
- Tăng cường lợi nhuận và hiệu quả hoạt động: Khai phá dữ liệu là quá trình thu thập và phân tích dữ liệu đáng tin cậy để giải quyết các vấn đề kinh doanh. Data Mining giúp doanh nghiệp xác định vấn đề, tìm kiếm dữ liệu liên quan và đưa ra giải pháp tối ưu, từ đó tăng lợi nhuận và hiệu quả vận hành.
- Ứng dụng rộng rãi: Khai phá dữ liệu là một quy trình linh hoạt, có thể áp dụng cho hầu hết mọi lĩnh vực, từ phân tích thị trường đến quản lý rủi ro. Bất kỳ dữ liệu nào cũng có thể được khai thác để giải quyết các vấn đề dựa trên bằng chứng cụ thể.
- Khám phá thông tin và xu hướng ẩn: Data Mining giúp doanh nghiệp phát hiện các mối tương quan và xu hướng ẩn giấu trong dữ liệu thô, mang lại giá trị tiềm ẩn. Kết quả từ các mô hình dữ liệu không chỉ hỗ trợ chiến lược độc đáo mà còn cung cấp những hiểu biết sâu sắc mà thông thường khó nhận ra.

Nhược điểm của Data Mining
- Tính phức tạp: Khai phá dữ liệu đòi hỏi kỹ năng kỹ thuật cao và công cụ phần mềm chuyên biệt. Điều này có thể trở thành rào cản lớn đối với các doanh nghiệp nhỏ thiếu nguồn lực và đội ngũ chuyên gia.
- Không đảm bảo kết quả: Mặc dù Data Mining cung cấp dữ liệu hữu ích để hỗ trợ ra quyết định, nhưng không thể đảm bảo thành công. Những thay đổi thị trường, lỗi mô hình hoặc dữ liệu không phù hợp đều có thể làm giảm hiệu quả của các giải pháp triển khai.
- Chi phí cao: Data Mining yêu cầu đầu tư lớn vào công cụ, dữ liệu và hạ tầng công nghệ thông tin (CNTT). Việc phân tích dữ liệu lớn cần khả năng tính toán mạnh mẽ, đồng thời chi phí lưu trữ và xử lý cũng là gánh nặng tài chính đối với nhiều doanh nghiệp, công cụ, dữ liệu và hạ tầng CNTT.

Ứng dụng thực tế của khai phá dữ liệu
Ứng dụng khai phá dữ liệu đã mang lại những bước tiến vượt bậc trong nhiều lĩnh vực, giúp doanh nghiệp tối ưu hóa hoạt động, nâng cao hiệu quả và ra quyết định chiến lược. Dưới đây là một số ứng dụng thực tế của Data Mining:
- Dịch vụ khách hàng: Data Mining hỗ trợ doanh nghiệp xác định các yếu tố khiến khách hàng hài lòng hoặc không hài lòng, từ đó cải thiện trải nghiệm dịch vụ và xây dựng lòng trung thành của khách hàng.
- Tài chính và ngân hàng: Trong lĩnh vực này, khai phá dữ liệu được sử dụng để phát hiện gian lận, đánh giá rủi ro tín dụng, xây dựng mô hình chấm điểm tín dụng, và cá nhân hóa chiến lược marketing. Nhờ đó, các tổ chức tài chính giảm thiểu tổn thất và bảo vệ khách hàng trước các hành vi gian lận.
- Y tế: Khai phá dữ liệu hỗ trợ chẩn đoán bệnh, xác định rủi ro sức khỏe, tối ưu hóa điều trị cá nhân hóa và phát hiện tương tác thuốc tiềm ẩn. Ngoài ra, nó còn giúp phân tích dữ liệu bệnh nhân để nâng cao chất lượng chăm sóc và giảm chi phí y tế.

- Giáo dục: Các cơ sở giáo dục sử dụng data mining để phân tích hành vi học tập của học sinh, xác định các môi trường học tập hiệu quả và tối ưu hóa kết quả giảng dạy.
- Sản xuất: Trong ngành sản xuất, khai phá dữ liệu giúp phân tích chuỗi cung ứng, dự báo nhu cầu, cải thiện hiệu quả sản xuất và giảm thiểu chi phí thông qua tự động hóa.
- Bán lẻ và thương mại điện tử: Khai phá dữ liệu trong kinh doanh được ứng dụng khá mạnh mẽ. Trong đó, các nhà bán lẻ sẽ tiến hành khai thác dữ liệu hành vi mua sắm của mỗi nhóm đối tương người dùng để cá nhân hóa chiến dịch marketing, tối ưu hóa quản lý hàng tồn kho và cải thiện doanh thu. Đồng thời, data mining còn hỗ trợ phát hiện gian lận trong thanh toán.
- Quản lý chuỗi cung ứng: Data mining giúp dự đoán nhu cầu thị trường, cải thiện chiến lược vận chuyển và tối ưu hóa kho bãi, góp phần tăng hiệu quả quản lý chuỗi cung ứng.
- Truyền thông và mạng xã hội: Phân tích dữ liệu người dùng trên mạng xã hội giúp doanh nghiệp nắm bắt xu hướng, tối ưu hóa nội dung và khai thác cơ hội quảng cáo phù hợp với đối tượng mục tiêu.
Top 10+ công cụ/phần mềm khai phá dữ liệu phổ biến
Dưới đây là danh sách các công cụ khai phá dữ liệu (data mining) phổ biến, được thiết kế để hỗ trợ doanh nghiệp tối ưu hóa phân tích dữ liệu và ra quyết định chiến lược.
RapidMiner
RapidMiner là nền tảng mạnh mẽ cho khai phá dữ liệu, tích hợp các thuật toán cần thiết cho học máy, học sâu, khai thác văn bản và phân tích dự đoán. Công cụ này nổi bật với giao diện kéo-thả và các mô hình dựng sẵn, giúp người không chuyên cũng có thể xây dựng luồng công việc một cách dễ dàng. Ngoài ra, cộng đồng người dùng của RapidMiner tương đối lớn, luôn túc trực và sẵn sàng hỗ trợ khi cần.

Oracle Data Mining
Thuộc bộ công cụ Oracle Advanced Analytics, Oracle Data Mining tập trung vào xây dựng mô hình dự đoán thông qua các thuật toán như phân loại, hồi quy và dự báo. Công cụ này không chỉ hỗ trợ phát hiện xu hướng và gian lận mà còn cho phép tích hợp với các ứng dụng BI qua API Java, giúp doanh nghiệp khai thác tối đa dữ liệu của mình.
IBM SPSS Modeler
IBM SPSS Modeler cung cấp giao diện kéo-thả thân thiện, hỗ trợ quá trình khai phá dữ liệu nhanh chóng và trực quan hơn. Công cụ này cho phép nhập dữ liệu từ nhiều nguồn khác nhau, giúp khám phá các mẫu và xu hướng ẩn sâu trong dữ liệu, từ đó tạo nên các mô hình dự đoán mạnh mẽ mà không cần kỹ năng lập trình cao.
Weka
Weka là công cụ mã nguồn mở, được viết bằng Java, cung cấp một bộ khung tích hợp cho nhiều thuật toán học máy. Ban đầu được thiết kế để phục vụ nghiên cứu nông nghiệp, Weka giờ đây được sử dụng rộng rãi trong lĩnh vực giáo dục và nghiên cứu khoa học, nhờ vào giao diện dễ sử dụng và các tính năng mạnh mẽ như phân cụm, phân loại và trực quan hóa dữ liệu.
KNIME
KNIME là một nền tảng khai phá dữ liệu miễn phí với giao diện trực quan, hỗ trợ phát triển mô hình phân tích mà không cần viết mã. Công cụ này còn cung cấp các tính năng tích hợp mạnh mẽ, giúp xử lý dữ liệu đa dạng và phát triển các ứng dụng BI, đặc biệt hữu ích trong tài chính và quản lý rủi ro.

H2O
H2O mang trí tuệ nhân tạo vào phân tích dữ liệu, hỗ trợ chạy nhiều thuật toán học máy, bao gồm cả AutoML để triển khai nhanh chóng các mô hình phức tạp. Công cụ này tích hợp tốt với các ngôn ngữ lập trình phổ biến như Python và R, cho phép quản lý dữ liệu lớn và xây dựng giải pháp linh hoạt.
Orange
Orange là một công cụ trực quan hóa dữ liệu nổi bật, cung cấp giao diện kéo-thả và các tính năng phân tích mạnh mẽ. Phù hợp cho các nhà sinh học và nhà khoa học dữ liệu, Orange hỗ trợ khai thác văn bản và xây dựng mô hình dễ dàng thông qua các biểu đồ tương tác như đồ thị hình nêm hay biểu đồ bóng.
Apache Mahout
Apache Mahout được xây dựng dựa trên nền tảng Hadoop, chuyên hỗ trợ phát triển các ứng dụng học máy có thể mở rộng. Công cụ này thích hợp với các chuyên gia muốn tự triển khai thuật toán của mình và thường được dùng trong xây dựng hệ thống gợi ý, phân cụm và phân loại dữ liệu lớn.
SAS Enterprise Miner
SAS Enterprise Miner giúp xử lý khối lượng dữ liệu lớn, chuyển đổi chúng thành các thông tin có giá trị. Công cụ này hỗ trợ nhiều thuật toán để xây dựng mô hình dự đoán, đặc biệt hữu ích trong phát hiện gian lận và tối ưu hóa chiến dịch marketing.
Teradata
Teradata là công cụ mạnh mẽ cho các doanh nghiệp sử dụng triển khai đa đám mây. Với tính năng không cần lập trình, Teradata giúp phân tích và phát triển mô hình kinh doanh một cách dễ dàng, phù hợp với nhiều môi trường như AWS, Google Cloud hay Azure.
Xu hướng phát triển của Data Mining trong tương lai
Công nghệ khai phá dữ liệu ngày càng phát triển mạnh mẽ với nhiều xu hướng mới, điển hình như:
Khai phá dữ liệu đa phương tiện (Multimedia Data Mining)
Xu hướng này tập trung vào việc thu thập và phân tích dữ liệu từ nhiều nguồn đa phương tiện như văn bản, âm thanh, hình ảnh và video. Các mô hình khai phá dữ liệu đa phương tiện giúp doanh nghiệp hiểu rõ hơn về hành vi khách hàng và cải thiện chiến lược kinh doanh.

Khai phá dữ liệu phổ biến (Ubiquitous Data Mining)
Khai phá dữ liệu từ các thiết bị như smartphone, laptop hay tablet đang ngày càng phổ biến. Mặc dù đối mặt với thách thức về chi phí và quyền riêng tư, xu hướng này hứa hẹn mang lại cơ hội lớn trong việc nghiên cứu tương tác giữa con người và máy tính.
Tự động hóa trong khai phá dữ liệu (Automation in Data Mining)
Với sự hỗ trợ của trí tuệ nhân tạo (AI) và học máy (ML), các tác vụ khai phá dữ liệu đang dần được tự động hóa. AI không chỉ tăng hiệu suất mà còn giúp phân tích các mẫu dữ liệu phức tạp, hỗ trợ ra quyết định chính xác hơn.
Khai phá dữ liệu phân tán (Distributed Data Mining)
Xu hướng này tập trung vào việc khai thác dữ liệu từ nhiều nguồn phân tán, như các văn phòng hoặc tổ chức khác nhau. Bằng cách sử dụng các thuật toán phức tạp, doanh nghiệp có thể tổng hợp dữ liệu để tạo ra những báo cáo và thông tin chi tiết giá trị.
>>> Xem thêm: Distributed Computing là gì? Những ứng dụng mới nhất của điện toán phân tán
Khai phá dữ liệu chuỗi thời gian (Time series data mining)
Phân tích các xu hướng chu kỳ và theo mùa là một trong những ứng dụng quan trọng của khai phá dữ liệu. Các doanh nghiệp có thể dự đoán xu hướng kinh doanh, tối ưu hóa hoạt động và lên kế hoạch chiến lược dài hạn.
Khai phá dữ liệu không gian và địa lý (Spatial and geographic data mining)
Đây là xu hướng khai thác thông tin từ dữ liệu không gian như hình ảnh vệ tinh hoặc bản đồ địa lý. Công nghệ này đang được ứng dụng mạnh mẽ trong các hệ thống thông tin địa lý (GIS) và ứng dụng điều hướng.

Kết luận:
Bài viết trên đây của VNPT AI đã giúp bạn hiểu rõ hơn về khái niệm "Data Mining là gì", cùng với những ứng dụng quan trọng của kỹ thuật này trong việc khai thác và chuyển hóa dữ liệu thô thành thông tin có giá trị. Nhìn chung, trong thời đại mà dữ liệu được ví như "vàng mới" của nền kinh tế số, việc áp dụng hiệu quả các phương pháp khai phá dữ liệu không chỉ giúp doanh nghiệp gia tăng năng lực cạnh tranh, mà còn tối ưu hóa các quy trình vận hành và ra quyết định chiến lược.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan





.jpg)