
Unsupervised Learning là gì? Ưu nhược điểm của học máy không giám sát

 26/02/2025
26/02/2025
Unsupervised Learning (Học không giám sát) là một phương pháp trong Machine Learning, trong đó mô hình tự học từ dữ liệu mà không cần nhãn có sẵn.
Trong kỷ nguyên số, khi doanh nghiệp phải xử lý khối lượng dữ liệu khổng lồ thì việc khai thác và phân tích thông tin trở thành một thách thức lớn. Đây cũng chính là lúc unsupervised learning được ứng dụng rộng rãi, giúp tối ưu hóa quá trình phân tích dữ liệu. Từ việc phân nhóm khách hàng đến phát hiện các xu hướng tiềm ẩn, học không giám sát đang dần trở thành một công cụ không thể thiếu trong phân tích dữ liệu hiện đại, từ đó mang lại lợi ích trong nhiều lĩnh vực. Cụ thể, VNPT AI sẽ giúp bạn đọc giải mã Unsupervised learning là gì trong bài viết dưới đây.
Unsupervised Learning là gì?
Unsupervised learning (học máy không giám sát) là một phần của Machine Learning, trong đó mô hình tự tìm kiếm các mẫu và cấu trúc trong dữ liệu mà không cần nhãn có sẵn. Thay vì dựa vào dữ liệu được gán nhãn trước, thuật toán này phân tích và nhóm các điểm dữ liệu dựa trên sự tương đồng và khác biệt dựa trên tệp dữ liệu đầu vào.
Nhờ khả năng tìm kiếm quy luật từ dữ liệu, Unsupervised Learning ngày càng trở thành công cụ quan trọng, giúp doanh nghiệp khai thác dữ liệu hiệu quả hơn và mang đến những trải nghiệm ngày càng thông minh và cá nhân hóa hơn cho người dùng.

>>> Xem thêm: Supervised Learning là gì? Ứng dụng thực tiễn của học có giám sát
Nguyên lý hoạt động của Unsupervised Learning
Để làm rõ hơn về khái niệm Unsupervised learning là gì, VNPT AI sẽ giúp bạn giải mã nguyên lý hoạt động của công nghệ này. Unsupervised learning hoạt động dựa trên thuật toán tự học, tức là không cần dữ liệu gán nhãn sẵn có nào. Thuật toán này sẽ nhận dữ liệu thô và tự khai thác các quy luật, sự tương đồng và khác biệt giữa các điểm dữ liệu.
Học giám sát và học không giám sát khác nhau ở mô hình dữ liệu và thuật toán. Cụ thể, Học không giám sát tự suy luận và sắp xếp dữ liệu theo quy luật. Ví dụ, nếu cung cấp một tập dữ liệu lớn về thời tiết mà không có thông tin cụ thể, thuật toán có thể tự phát hiện các nhóm dữ liệu có nhiệt độ tương đồng hoặc kiểu thời tiết giống nhau. Khi quan sát kết quả, bạn có thể nhận ra rằng các nhóm nhiệt độ tương ứng với bốn mùa, hoặc các mẫu thời tiết giống nhau có thể đại diện cho các điều kiện như mưa, tuyết hay sương mù.

Nhờ nguyên lý hoạt động này, Unsupervised learning đặc biệt hữu ích trong những bài toán yêu cầu phân tích và xử lý dữ liệu phức tạp. Nó thường được áp dụng trong phân cụm khách hàng, phát hiện xu hướng ẩn trong dữ liệu lớn hoặc giảm số chiều dữ liệu để tối ưu hóa mô hình.
Các thuật toán học không giám sát phổ biến
Dưới đây là một số thuật toán học không giám sát phổ biến, mỗi thuật toán mang lại những ưu điểm riêng trong việc phân tích và xử lý dữ liệu:
Phân cụm
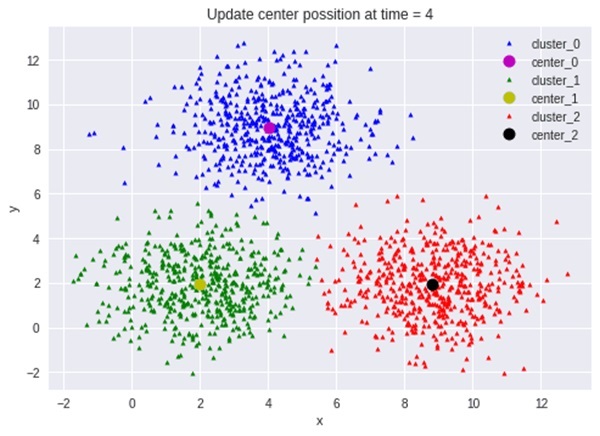
Thuật toán phân cụm giúp nhóm các dữ liệu chưa được gán nhãn thành từng cụm dựa trên điểm chung của chúng. Mục tiêu chính của phân cụm là phát hiện các mẫu và mối quan hệ tiềm ẩn trong dữ liệu.
Bằng cách xác định các nhóm có đặc điểm tương tự nhau, thuật toán này được ứng dụng rộng rãi trong nhiều lĩnh vực như phân nhóm khách hàng, phân tích thị trường, phát hiện gian lận, hay thậm chí trong xử lý hình ảnh và phân tích gen. Từ đó, các doanh nghiệp có thể nghiên cứu và khai thác thông tin một cách hiệu quả hơn.
Một số thuật toán phân cụm được sử dụng phổ biến bao gồm:
- Phân cụm K-means: Chia dữ liệu thành K cụm, trong đó mỗi điểm được gán vào cụm gần nhất dựa trên khoảng cách.
- Phân cụm theo thứ bậc: Xây dựng một cây phân cấp bằng cách lần lượt gộp hoặc tách các nhóm dữ liệu.
- Phân cụm dựa trên mật độ (DBSCAN): Xác định cụm dựa trên mật độ dữ liệu, giúp phát hiện các cụm có hình dạng không đều và loại bỏ các điểm phân tán nhiễu.
- Phân cụm dịch chuyển trung bình: Phát hiện các cụm bằng cách di chuyển các điểm về phía khu vực đông đúc nhất.
- Phân cụm phổ: Phân cụm dựa trên biểu đồ kết nối giữa các điểm, thường được sử dụng khi dữ liệu có cấu trúc phức tạp.
Liên kết
Thuật toán liên kết là một kỹ thuật ML dựa trên quy tắc tìm ra một số mối quan hệ rất hữu ích giữa các tham số của một tập dữ liệu lớn. Về cơ bản, kỹ thuật này được sử dụng để phân tích giỏ hàng, từ đó giúp hiểu rõ hơn mối quan hệ giữa các sản phẩm khác nhau.
Các thuật toán được sử dụng phổ biến như:
- Thuật toán Apriori: Tìm các mẫu bằng cách khám phá các kết hợp mục thường xuyên theo từng bước.
- Thuật toán FP-Growth: Là một giải pháp thay thế hiệu quả cho Apriori, giúp xác định nhanh các mẫu thường gặp mà không cần tạo ra các tập ứng viên.
- Thuật toán Eclat: Sử dụng giao điểm của các tập mục để tìm các mẫu thường xuyên một cách hiệu quả.
- Thuật toán dựa trên cây hiệu quả: Có khả năng xử lý các tập dữ liệu lớn bằng cách sắp xếp dữ liệu theo cấu trúc cây.
Giảm kích thước
Thuật toán giảm kích thước là phương pháp giảm bớt số lượng đặc trưng trong một tập dữ liệu mà vẫn giữ lại càng nhiều thông tin càng tốt. Kỹ thuật này giúp tăng hiệu suất cho các thuật toán machine learning bằng cách loại bỏ các đặc trưng không cần thiết, đồng thời hỗ trợ trực quan hóa dữ liệu dễ dàng hơn. Giảm kích thước giúp giảm bớt độ phức tạp của dữ liệu, làm cho quá trình phân tích trở nên nhanh chóng và hiệu quả hơn, đặc biệt khi làm việc với các tập dữ liệu lớn.
Một số thuật toán giảm kích thước như:
- Phân tích thành phần chính (PCA): Giảm kích thước bằng cách chuyển đổi dữ liệu thành các thành phần chính không tương quan.
- Phân tích phân biệt tuyến tính (LDA): Giảm kích thước trong khi tối đa hóa khả năng phân tách lớp cho các tác vụ phân loại.
- Phân tích ma trận không âm (NMF): Chia dữ liệu thành các phần không âm để đơn giản hóa biểu diễn.
- Nhúng tuyến tính cục bộ (LLE): Giảm kích thước trong khi vẫn giữ nguyên mối quan hệ giữa các điểm gần đó.
- Isomap: Ghi lại cấu trúc dữ liệu toàn cục bằng cách bảo toàn khoảng cách dọc theo một đa tạp.
Ưu nhược điểm của học không giám sát
Dưới đây là những ưu nhược điểm của Unsupervised learning mà các doanh nghiệp cần biết để áp dụng hiệu quả hơn:
Ưu điểm
Học không giám sát mang lại nhiều ưu điểm đáng kể, đặc biệt khi xử lý dữ liệu lớn và phức tạp:
- Xử lý các tác vụ phức tạp: Học không giám sát có thể giải quyết những bài toán phức tạp như phân cụm dữ liệu lớn, phát hiện bất thường, hay phân tích mối quan hệ giữa các yếu tố mà không cần sự can thiệp của con người.
- Không cần giải thích nhãn: Một trong những điểm mạnh của học không giám sát là không cần phải chuẩn bị dữ liệu có nhãn. Điều này giúp tiết kiệm thời gian và công sức trong việc tạo ra hoặc thu thập nhãn cho mỗi điểm dữ liệu.
- Hoạt động theo thời gian thực: Học không giám sát có thể hoạt động với dữ liệu thời gian thực để xác định các mẫu.
- Ít tốn kém hơn: Vì không cần đến quá trình gán nhãn dữ liệu phức tạp và tốn kém, học không giám sát thường ít chi phí hơn so với các phương pháp học có giám sát.
Nhược điểm
Mặc dù học không giám sát có nhiều ưu điểm nhưng phương pháp này cũng tồn tại một số nhược điểm cần chú ý khi áp dụng trong thực tiễn.
- Độ chính xác không ổn định: Kết quả của học không giám sát có thể thay đổi tùy theo thuật toán sử dụng và cách thức phân tích. Do thiếu sự giám sát, các mô hình có thể tạo ra những kết quả không chính xác hoặc khó giải thích nếu dữ liệu không đủ chất lượng hoặc nhiễu.
- Yêu cầu dữ liệu lớn và đa dạng: Để đạt được kết quả tốt, học không giám sát cần một lượng dữ liệu lớn và đa dạng. Nếu dữ liệu thiếu sự đa dạng hoặc không đầy đủ, các mẫu có thể không phản ánh đúng thực tế.
Ứng dụng thực tế của Unsupervised Learning
Các ứng dụng của Unsupervised Learning rất đa dạng trong nhiều lĩnh vực như:
- Phân tích hành vi khách hàng: Unsupervised Learning được sử dụng để phân nhóm khách hàng dựa trên thói quen mua sắm, hành vi trực tuyến hoặc sở thích, giúp các doanh nghiệp cá nhân hóa chiến lược tiếp thị và cung cấp sản phẩm/dịch vụ phù hợp.
- Xử lý ngôn ngữ tự nhiên (NLP): Học không giám sát giúp phân loại văn bản, hay tìm kiếm thông tin mà không cần dữ liệu đã được gán nhãn. Chẳng hạn, các thuật toán này có thể phân nhóm các bài viết theo chủ đề, phân tích cảm xúc trong các bình luận hay nhận diện ý nghĩa của câu từ trong một đoạn văn.
- Phân loại hình ảnh và video: Unsupervised Learning thường áp dụng cho việc phân nhóm và nhận diện các đặc điểm tương đồng giữa các bức ảnh hoặc video mà không cần thông tin nhãn.
- Phát hiện bất thường: Học không giám sát được sử dụng để phát hiện điểm bất thường hoặc gian lận trong dữ liệu mà không cần dữ liệu nhãn. Ví dụ, trong các hệ thống giám sát, thuật toán này có thể phát hiện các hành vi bất thường của người dùng hoặc các giao dịch đáng ngờ, giúp ngăn chặn hành vi gian lận hoặc sự cố an ninh.
- Hỗ trợ công cụ đề xuất: Thuật toán có thể nhóm các sản phẩm, bài hát, hoặc bộ phim tương tự nhau dựa trên hành vi người dùng, từ đó đưa ra các gợi ý cá nhân hóa hơn.

Tạm kết
Bài viết trên của VNPT AI đã giúp bạn đọc giải thích Unsupervised learning là gì và khám phá những ứng dụng thực tế phổ biến của công nghệ này. Tóm lại, đây không chỉ là một công cụ mạnh mẽ giúp khai thác và phân tích dữ liệu mà còn mở ra cơ hội cho các doanh nghiệp hiểu sâu hơn về hành vi và xu hướng tiềm ẩn. Khi khối lượng dữ liệu ngày càng tăng, học không giám sát sẽ tiếp tục phát triển và trở thành yếu tố quyết định trong việc thúc đẩy sự sáng tạo và đổi mới trong tương lai.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan
.jpg)


