
Ứng dụng khung học sâu đa mô-đun phát hiện vi phạm đội mũ bảo hiểm ở xe máy

 13/03/2025
13/03/2025
Theo Tổ chức Y tế Thế giới (WHO), sử dụng mũ bảo hiểm đúng chuẩn có thể giảm 69 % chấn thương sọ não và 42 % nguy cơ tử vong khi xảy ra va chạm xe máy. Tuy nhiên, tại nhiều đô thị châu Á, nơi xe hai bánh chiếm tỷ lệ lưu thông chủ đạo, tỷ lệ tuân thủ đội mũ bảo hiểm chỉ dưới 60 %. Trong khi đó, mô hình giám sát thủ công hiện nay khó đáp ứng yêu cầu 24/ 7 trên mạng lưới camera toàn thành phố. Hệ thống AI tự động phát hiện lái xe hoặc hành khách không đội mũ bảo hiểm vì vậy trở thành nhu cầu cấp thiết, đặc biệt ở các nước đang phát triển như Việt Nam.

Song, việc triển khai khung học sâu đa mô‑đun phát hiện vi phạm mũ bảo hiểm trong thực tế đối diện ba thách thức lớn: i) lượng xe dày đặc và tốc độ di chuyển cao; ii) điều kiện ánh sáng, góc camera và chất lượng video biến thiên mạnh; iii) dữ liệu huấn luyện mất cân đối nghiêm trọng giữa lớp phổ biến (lái xe đội mũ) và lớp hiếm (trẻ em hoặc người ngồi sau không đội mũ).
Vì vậy, nhóm VNPT AI phát triển khung (framework) phân tích video có khả năng:
- Nhận diện đồng thời lái xe, hành khách phía sau (P2) và trẻ em phía trước (P0) vi phạm;
- Ổn định độ chính xác khi thay đổi độ phân giải, chiếu sáng hay góc quay;
- Khắc phục mất cân đối dữ liệu, đặc biệt với các lớp P0‑NoHelmet và P2‑NoHelmet;
- Nâng chính xác vượt ngưỡng Co-DETR gốc và hướng tới thứ hạng cao trên bảng xếp hạng quốc tế.
Trong bài viết này, đội ngũ kỹ sư VNPT AI chúng tôi sẽ trình bày kinh nghiệm xây dựng khung học sâu đa mô‑đun phát hiện vi phạm mũ bảo hiểm trong môi trường giao thông thực. Bằng cách phối hợp ensemble nhiều kiến trúc, cân bằng dữ liệu Copy‑Paste và hiệu chỉnh xác suất theo bối cảnh.

Đặt nền bằng kiến trúc đa mô đun
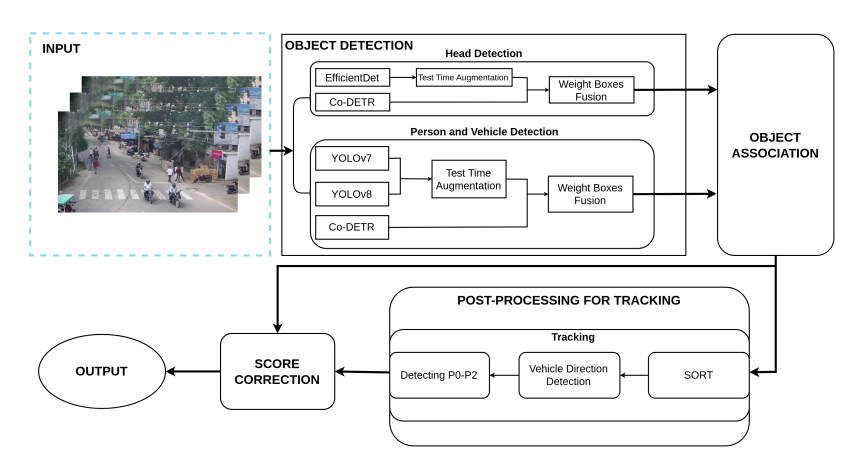
Tầng phát hiện mô hình
Hệ thống được tách thành hai tầng phát hiện:
- Tầng thứ nhất xác định người và xe máy bằng YOLOv7-D6, YOLOv8-X ở nhiều kích cỡ cùng Co-DETR-Swin-L;
- Tầng thứ hai định vị chính xác phần đầu bằng Co-DETR và EfficientDet-D7.
Mỗi mô hình suy diễn trên tập chuyển đổi thời gian (TTA: lật, xoay, đa tỷ lệ). Kết quả hợp nhất qua Weighted Boxes Fusion (WBF) nhằm giảm bỏ lỡ (false‑negative) ở vùng rìa khung hình hoặc khi đối tượng bị che khuất.
Liên kết và theo dõi để hiểu ngữ cảnh
Sau khi có toạ độ, các khung hình đầu‑người‑xe được gán cùng ID nếu thỏa chồng lấn không gian. Sau đó, chúng tôi kết hợp mô‑đun SORT và Kalman Filter tùy biến để:
- Theo vết đối tượng qua chuỗi khung;
- Suy diễn hướng di chuyển (tiến về/ra xa camera);
- Xác suất hóa vị trí tương đối giữa nhiều đầu để suy luận P0 (trẻ em) và P2 (người ngồi sau).
Khả năng “đọc” bối cảnh 3D này giảm đáng kể nhãn sai (driver ↔ passenger) – một lỗi thường gặp khi chỉ dựa khung hình đơn.
Chiến lược cân bằng dữ liệu Copy‑Paste
Thống kê bộ huấn luyện gốc cho thấy P0/P2‑NoHelmet xuất hiện < 0,5 % tổng mẫu. Để tránh mô hình “học lệch”, nhóm áp dụng hai chiến lược Copy‑Paste:
- Thủ công – cắt patch đầu không đội mũ rồi dán vào vị trí hợp lý trên khung hình khác (căn chỉnh IOU & tỷ lệ).
- Tự động – dùng Segment Anything tách người, chèn vào clip mới; nhãn được suy ra từ vị trí tương đối (phía trước = P0; phía sau = P2).
Nhờ bổ sung 45 mẫu P2‑NoHelmet và 58 mẫu P0‑NoHelmet, tập V2 trở nên cân đối hơn, giúp mô hình học đặc trưng thay vì “nhớ khung cảnh” của lớp hiếm.
Tinh chỉnh điểm tin cậy cho lớp hiếm
Ngay cả khi nhận diện đúng, mạng thường vẫn do dự cho P0/P2 vì độ hiếm dữ liệu. Dựa trên kết quả tracking, thuật toán tăng +0,1 điểm cho P0 và +0,2 điểm cho P2 trong video được xác định chắc chắn có lớp tương ứng. Thao tác giản đơn này đẩy khung vi phạm vượt ngưỡng NMS mà không gây trôi nhãn ở lớp phổ biến.
Thiết lập thực nghiệm và kết quả
Chúng tôi đã dự thi phương pháp này tại Track 5 - Detecting Violation of Helmet Rule for Motorcyclists (Phát hiện hành vi không đội mũ bảo hiểm), cuộc thi AI City Challenge 2024. Trong đó, phương pháp của VNPT AI đạt 0,4792 mAP, cao hơn 7,43 phần trăm so với Co-DETR gốc (0,4049), qua đó là một trong ba đội đạt mAP cao nhất tại Track 3. Phân tích đóng góp cho thấy gói tăng cường dữ liệu mang lại thêm 3,34 mAP, phương pháp ensemble cộng dồn 2,08 mAP và bước hiệu chỉnh điểm tin cậy bổ sung 2,01 mAP, tạo nên bước nhảy tổng hợp kể trên. Trên tập validation riêng, Co-DETR đã chạm 0,6786 mAP; riêng bộ phát hiện đầu bằng Co-DETR đạt 0,692, vượt xa EfficientDet-D7 (0,626), khẳng định tính ưu việt của kiến trúc trọng tâm. Tập hợp lại, chuỗi cải tiến này không chỉ nâng điểm số mà còn có thể thương mại hóa giải pháp phát hiện vi phạm mũ bảo hiểm ở quy mô đô thị.
>>> Đọc thêm: Giải pháp phát hiện đối tượng trong ảnh mắt cá
Tác giả: Dương Việt Hùng
Tin mới nhất
16/10/2025
14/10/2025
12/10/2025
10/10/2025
07/10/2025
27/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan

