
Phương pháp tiếp cận Emotion Transplantation trong tổng hợp tiếng nói biểu cảm

 10/10/2025
10/10/2025
Phương pháp Emotion Transplantation do VNPT AI nghiên cứu là giải pháp đột phá cho tổng hợp tiếng nói biểu cảm (Emotional TTS), vượt qua thách thức dữ liệu khan hiếm. Kỹ thuật này chuyển giao khả năng biểu cảm tự nhiên từ người nói nguồn sang người nói đích, kết hợp kiến trúc VITS và Global Style Token (GST). Tại VLSP 2022, phương pháp này đã đạt hạng 1 tự nhiên (MOS 3.762) và tổng hạng 2, chứng minh hiệu quả thực tiễn.

Tổng hợp tiếng nói có cảm xúc (Emotional Text-to-Speech – Emotional TTS) là hướng nghiên cứu nhằm tạo ra giọng nói tổng hợp có khả năng biểu đạt các trạng thái cảm xúc tự nhiên, tuy nhiên bài toán này gặp nhiều thách thức do hạn chế về dữ liệu, đặc biệt là việc thu thập bộ dữ liệu cảm xúc chất lượng cao. Để giải quyết vấn đề này, đội ngũ chuyên gia từ VNPT AI đã nghiên cứu và triển khai phương pháp "Emotion Transplantation" (Chuyển đổi biểu cảm). Phương pháp này cho phép chuyển giao khả năng biểu đạt cảm xúc từ một người nói nguồn sang người nói đích thông qua quy trình tiền xử lý dữ liệu nghiêm ngặt và kiến trúc học sâu tiên tiến, giúp tối ưu hóa hiệu quả tổng hợp giọng nói trong điều kiện dữ liệu hạn chế.
Thách thức về dữ liệu trong TTS biểu cảm
Các hệ thống TTS truyền thống hiện nay đã đạt được chất lượng âm thanh cao nhờ các kiến trúc như FastSpeech2 hay VITS, tuy nhiên việc tích hợp sắc thái cảm xúc vẫn là một bài toán phức tạp. Phần lớn các mô hình hiện nay yêu cầu bộ dữ liệu cảm xúc quy mô lớn từ chính người nói mục tiêu, nhưng thực tế người nói thường khó biểu đạt cảm xúc một cách tự nhiên trong quá trình ghi âm phòng thu.
Phương pháp Emotion Transplantation được phát triển nhằm tận dụng bộ dữ liệu cảm xúc từ người nói nguồn và kết hợp với bộ dữ liệu trung tính của người nói đích. Mục tiêu cốt lõi là điều chỉnh mô hình sao cho tái tạo chính xác đặc trưng giọng nói của người nói đích trong khi vẫn duy trì được năng lực biểu cảm của người nói nguồn.
Quy trình tiền xử lý dữ liệu đa tầng
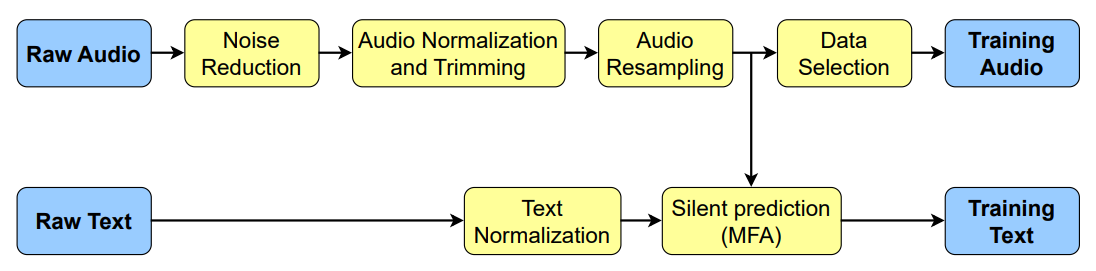
Dữ liệu đầu vào cho bài toán này thường chứa nhiều tạp âm và không đồng nhất về phong cách nói. Để đảm bảo chất lượng huấn luyện, đội ngũ chuyên gia VNPT AI đã thiết lập hệ thống tiền xử lý bao gồm các giai đoạn,:
- Giảm nhiễu (Noise Reduction): Sử dụng mô hình Music Source Separation và FullSubNet để tách lọc giọng nói khỏi các nguồn tạp âm như nhạc nền hoặc tiếng ồn môi trường.
- Chuẩn hóa và Cắt lọc (Normalization & Trimming): Điều chỉnh âm lượng về mức 20dB và loại bỏ các khoảng lặng ở hai đầu tệp tin nhằm hỗ trợ mô hình dự đoán chính xác hơn các âm vị đầu tiên.
- Căn chỉnh văn bản và âm thanh (Alignment): Sử dụng MFA để ước lượng độ dài các từ trong audio, từ đó đưa ra được khoảng lặng và dựa trên độ dài các khoảng lặng này để tự động hóa việc gán dấu câu, giúp mô hình học được nhịp điệu và ngắt nghỉ tự nhiên.
- Lọc dữ liệu dựa trên tốc độ nói: Loại bỏ các mẫu có giá trị từ trên giây (WPS) nằm ngoài khoảng 3.0 đến 5.5 và các tệp có độ dài dưới 0.8 giây để đảm bảo tính ổn định cho mô hình.
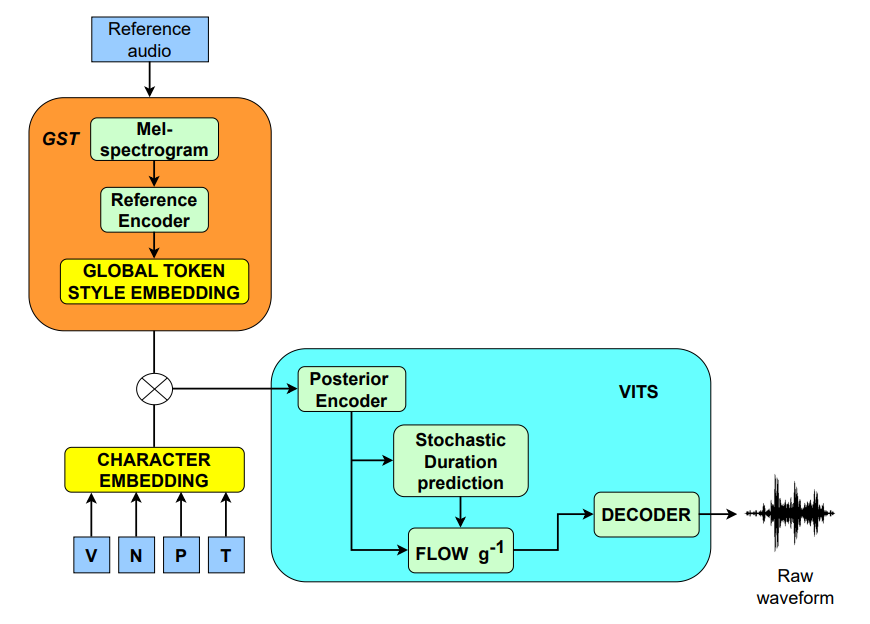
Kiến trúc mô hình và chiến lược thích nghi giọng nói
Hệ thống sử dụng kiến trúc VITS làm khung xương cốt lõi (backbone), kết hợp với mô-đun Global Style Token (GST) đóng vai trò là bộ mã hóa cảm xúc (Emotion Encoder). VITS tích hợp các kỹ thuật Variational Autoencoder, Stochastic Duration Prediction và Adversarial Training, giúp tạo ra âm thanh có chất lượng tương đương các mô hình hai giai đoạn nhưng vẫn giữ được lợi thế về tốc độ huấn luyện song song.
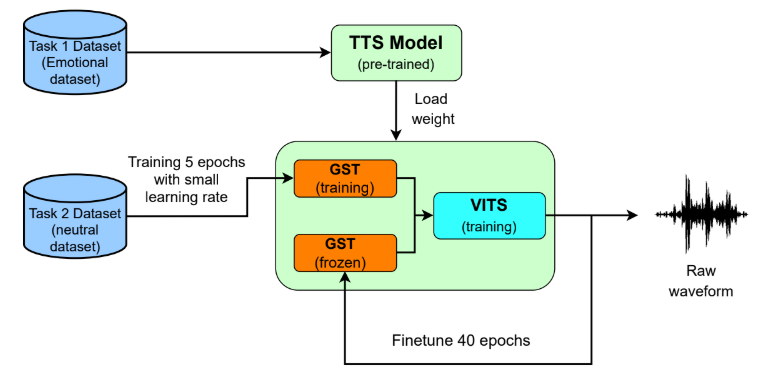
Chiến lược huấn luyện được chia thành hai giai đoạn chính,:
- Huấn luyện Baseline: Xây dựng mô hình TTS biểu cảm cơ sở cho người nói nguồn bằng cách sử dụng nhúng cảm xúc từ GST.
- Thích nghi giọng nói (Voice Adaptation): Tinh chỉnh mô hình trên dữ liệu người nói đích với tốc độ học thấp. Trong 5 epoch đầu, toàn bộ mô hình được cập nhật để học đặc trưng người nói đích; sau đó, trọng số của mô-đun GST được đóng băng trong 40 epoch tiếp theo để bảo toàn năng lực biểu cảm trong khi mô hình tiếp tục tối ưu hóa các đặc trưng âm học của mục tiêu.
Kết quả thực nghiệm tại VLSP 2022
Kết quả thực nghiệm cho thấy hệ thống đạt độ tương đồng giọng nói cao với điểm cosine similarity trung bình khoảng 0.75 cho các trạng thái Trung tính, Buồn và Vui. Tại cuộc thi VLSP 2022, giải pháp của VNPT AI đã đạt được các thứ hạng ấn tượng:
- Hạng Nhì về độ tự nhiên (MOS đạt 3.762).
- Hạng Nhì về độ tương đồng người nói (đạt 2.286/4.0).
- Hạng Ba về độ rõ lời (Intelligibility).
Tổng hợp các tiêu chí, phương pháp của đội ngũ đã đạt vị trí thứ hai chung cuộc, khẳng định tính hiệu quả của mô hình trong việc chuyển đổi cảm xúc ngay cả khi dữ liệu huấn luyện bị hạn chế.
Kết luận
Nghiên cứu về phương pháp Emotion Transplantation của VNPT AI đã chứng minh khả năng ứng dụng thực tiễn của việc kết hợp kiến trúc VITS và GST trong bài toán tổng hợp giọng nói biểu cảm. Việc thiết lập một quy trình xử lý dữ liệu chuẩn hóa và chiến lược thích nghi mô hình phù hợp là chìa khóa để vượt qua các hạn chế về tài nguyên dữ liệu, mở ra hướng phát triển cho các hệ thống giao tiếp người - máy thông minh và thấu cảm hơn.
Tác giả: Tumi Tran
Tin mới nhất
16/10/2025
14/10/2025
12/10/2025
07/10/2025
27/09/2025
26/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá