
ZIQA: Tối ưu hệ thống Hỏi đáp Đa phương thức trong lĩnh vực Giao thông

 12/10/2025
12/10/2025
Tối ưu hóa hệ thống hỏi đáp đa phương thức trong lĩnh vực giao thông đang đặt ra nhiều thách thức, từ thuật ngữ pháp quy phức tạp đến sự thiếu hụt dữ liệu gán nhãn chất lượng cao. Trước bài toán đó, đội ngũ chuyên gia VNPT AI đã phát triển ZIQA (Zero-shot Image Question Answering) – một khung giải pháp không cần huấn luyện, kết hợp tiền xử lý dữ liệu đa phương thức và kỹ nghệ câu lệnh để nâng cao khả năng lý luận của mô hình thị giác – ngôn ngữ. Tại cuộc thi VLSP 2025 MLQA-TSR, giải pháp ZIQA+ dựa trên backbone InternVL3-78B đã đạt độ chính xác 83,56% trên tập kiểm thử kín, cho thấy hiệu quả rõ rệt của cách tiếp cận zero-shot trong các bài toán hỏi đáp luật giao thông đặc thù.
Trong nỗ lực giải quyết các thách thức về thuật ngữ chuyên ngành và sự khan hiếm dữ liệu nhãn trong lĩnh vực pháp quy, đội ngũ chuyên gia từ VNPT AI đã phát triển khung giải pháp ZIQA (Zero-shot Image QA). Đây là một mô hình tiếp cận không cần huấn luyện (training-free), kết hợp giữa tiền xử lý dữ liệu đa phương thức và hệ thống truy vấn lai để tối ưu hóa khả năng lý luận của các mô hình thị giác - ngôn ngữ (VLM). Tại cuộc thi VLSP 2025 MLQA-TSR, giải pháp dựa trên backbone InternVL3-78B tích hợp ZIQA+ đã đạt độ chính xác 83,56% trên tập kiểm thử kín, khẳng định tính hiệu quả của việc kỹ nghệ câu lệnh (prompt engineering) trong các miền dữ liệu đặc thù.

Thách thức trong lý luận đa phương thức đặc thù miền
Việc hỏi đáp dựa trên hình ảnh (Image QA) yêu cầu sự hiểu biết thị giác chi tiết và khả năng tích hợp ngữ cảnh văn bản. Trong lĩnh vực giao thông và pháp quy, các thách thức này bị khuếch đại bởi ba yếu tố: sự khó khăn trong việc căn chỉnh sơ đồ quy định với các điều khoản văn bản; các tài liệu dài và bảng biểu HTML phức tạp vượt quá cửa sổ ngữ cảnh của mô hình; và sự thiếu hụt dữ liệu gán nhãn khiến việc huấn luyện tinh chỉnh (fine-tuning) dễ dẫn đến hiện tượng quá khớp (overfitting). Ngoài ra, thông tin bổ trợ nhiễu có thể gây xao nhãng và làm giảm hiệu suất của các pipeline đa phương thức.
Chiến lược tiền xử lý và Kỹ nghệ câu lệnh ZIQA
Nhằm khắc phục giới hạn về chiều dài ngữ cảnh của VLM, pipeline ZIQA triển khai các chiến lược nén và chuẩn hóa dữ liệu:
- Xử lý hình ảnh: Các hình ảnh trong văn bản được ghép nối thành một hình ảnh tổng hợp duy nhất bằng thư viện PIL và được gán nhãn chỉ định (identifier). Thiết kế này cho phép căn chỉnh rõ ràng giữa tham chiếu văn bản và đầu vào thị giác, đồng thời giảm số lượng token tiêu tốn (thường từ 2k-3k token cho mỗi hình ảnh riêng lẻ).
- Xử lý bảng biểu: Các bảng biểu định dạng HTML thường rườm rà được chuyển đổi sang định dạng Markdown. Quá trình này giúp giảm dấu ấn token nhưng vẫn duy trì cấu trúc thông tin thiết yếu để mô hình có thể diễn giải tương đương với HTML.
Thay vì huấn luyện lại mô hình, đội ngũ chuyên gia VNPT AI tập trung vào cấu trúc câu lệnh (prompt) bao gồm ba yếu tố: ngữ cảnh đoạn văn, câu hỏi trắc nghiệm và các quy tắc định dạng đầu ra nghiêm ngặt. Chiến lược ZIQA+ còn bổ sung các quy tắc heuristics để lọc bỏ thông tin gây nhiễu từ các điều luật bổ trợ, giúp mô hình tập trung vào ngữ cảnh cốt lõi và đưa ra câu trả lời tin cậy hơn.
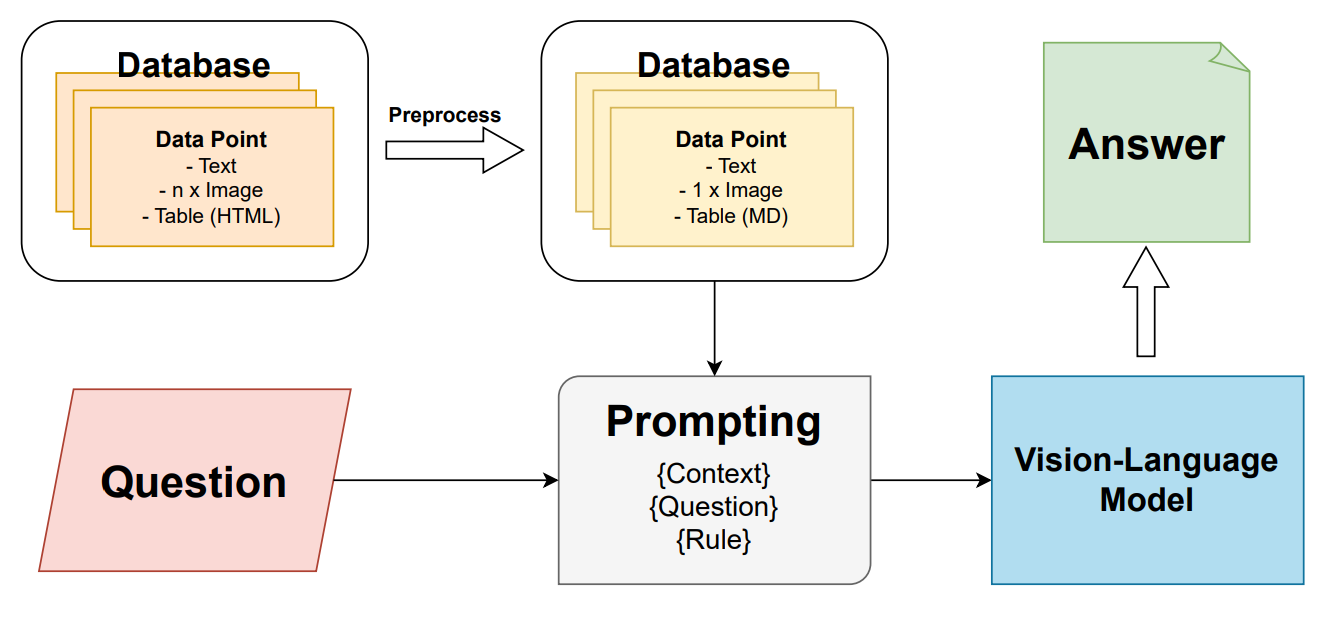
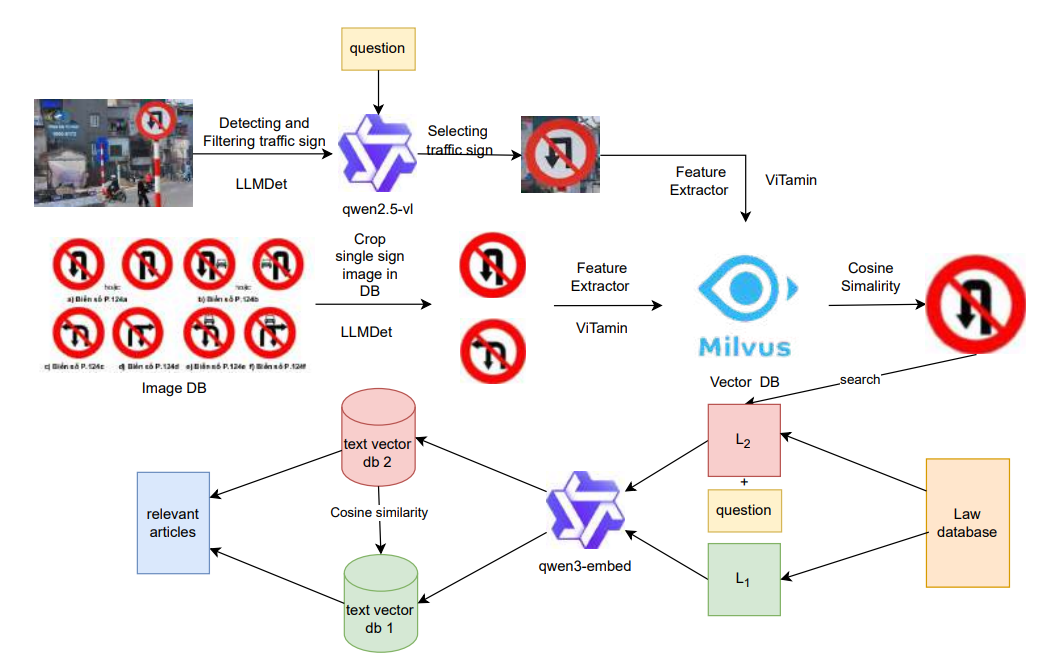
Hệ thống truy vấn lai (Hybrid Retrieval Strategy)
Hệ thống truy vấn đa phương thức zero-shot được thiết kế để kết nối hình ảnh biển báo giao thông với các văn bản pháp luật. Quy trình bao gồm các giai đoạn:
- Phát hiện và Lọc: Sử dụng LLMDet để trích xuất khung bao (bounding box) của biển báo, sau đó dùng Qwen2.5-VL để phân loại nhị phân nhằm loại bỏ các biển báo không phải giao thông (như biển quảng cáo).
- Truy vấn hình ảnh: Kết hợp tìm kiếm tương đồng dựa trên đặc trưng (embedding ViTamin và Milvus) với phân loại mục tiêu cho các loại biển báo quan trọng như "Biển cấm vào" hoặc "Biển thời gian". Đối với các hạng mục này, hệ thống ánh xạ trực tiếp đến cơ sở dữ liệu để đảm bảo tính xác định và khả năng diễn giải.
- Truy vấn văn bản: Sử dụng Qwen3-Embed để tính toán độ tương đồng cosine, liên kết các hình ảnh ứng viên với các điều luật tương ứng trong cơ sở dữ liệu pháp quy.
Đánh giá hiệu suất thực nghiệm
Thực nghiệm trên tập dữ liệu xây dựng từ Quy chuẩn QCVN 41:2024/BGTVT và Luật Trật tự, an toàn giao thông đường bộ số 36/2024/QH15 cho thấy hiệu quả vượt trội của phương pháp tiếp cận này. Trên tập kiểm thử công khai, InternVL3-78B kết hợp ZIQA đã nâng độ chính xác từ 82% lên 84%. Đối với tập kiểm thử kín có độ đa dạng và thách thức cao hơn, hệ thống ZIQA+ đạt 83,56%, vượt qua các cấu hình chỉ sử dụng tiền xử lý hình ảnh hoặc bảng biểu đơn lẻ.
Phân tích các trường hợp lỗi chỉ ra rằng các vật thể quy mô nhỏ hoặc ở xa có thể bị bỏ lỡ bởi bộ phát hiện, dẫn đến sai sót trong chuỗi lý luận. Tuy nhiên, việc nén ngữ cảnh thông qua tiền xử lý Markdown và ghép ảnh đã tạo ra một môi trường dữ liệu ít nhiễu, cải thiện khả năng diễn giải các tín hiệu thị giác về hình dạng và màu sắc của mô hình.
Kết luận
Khung giải pháp ZIQA cung cấp một mô hình thực tiễn cho các hệ thống hỏi đáp đa phương thức trong các miền có quy định chặt chẽ và hạn chế về dữ liệu gán nhãn. Bằng cách ưu tiên thiết kế truy vấn và tối ưu hóa câu lệnh, hệ thống không chỉ giảm chi phí phát triển mà còn duy trì được tính chính xác và khả năng mở rộng cho các triển khai quy mô lớn trong tương lai.
Tác giả: Tumi Tran
Tin mới nhất
16/10/2025
14/10/2025
10/10/2025
07/10/2025
27/09/2025
26/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá