
Chuyển đổi giọng nói cho ngôn ngữ ít tài nguyên bằng Chuyển giao tri thức

 16/10/2025
16/10/2025
Chuyển đổi giọng nói cho ngôn ngữ ít tài nguyên như Tiếng Việt đang là thách thức lớn trên bản đồ AI thế giới, bởi Tiếng Việt vốn được coi là ngôn ngữ ít tài nguyên dữ liệu sạch. Để khắc phục điều này, VNPT AI đã nghiên cứu thành công phương pháp Chuyển đổi giọng nói (Voice Conversion) kết hợp "Chuyển giao tri thức", giải quyết triệt để vấn đề rò rỉ giọng người nói nguồn.

Chuyển đổi giọng nói cho ngôn ngữ ít tài nguyên: Phương pháp tiếp cận dựa trên Chuyển giao tri thức và Huấn luyện đối nghịch miền
Trong lĩnh vực xử lý tiếng nói, việc xây dựng mô hình chuyển đổi giọng nói (Voice Conversion - VC) hiệu năng cao cho các ngôn ngữ ít tài nguyên (Low-Resource Languages) như tiếng Việt thường gặp rào cản do thiếu hụt dữ liệu gán nhãn quy mô lớn. Nhằm giải quyết vấn đề rò rỉ đặc trưng người nói nguồn trong các kiến trúc không phụ thuộc văn bản (text-free), đội ngũ chuyên gia tại VNPT AI đã nghiên cứu và phát triển một phương pháp mới kết hợp Chuyển giao tri thức (Knowledge Transfer - KT) từ ngôn ngữ giàu tài nguyên và Huấn luyện đối nghịch miền (Domain-Adversarial Training - DAT). Giải pháp này cho phép tách biệt hiệu quả giữa nội dung ngôn ngữ và danh tính người nói, đạt được độ tự nhiên và tương đồng vượt trội trong điều kiện dữ liệu hạn chế.
Thách thức trong tách biệt đặc trưng người nói
Chuyển đổi giọng nói any-to-any hướng tới việc biến đổi giọng của người nói nguồn thành người nói mục tiêu bất kỳ mà vẫn bảo tồn nội dung ngôn ngữ. Các phương pháp dựa trên văn bản (text-based) đòi hỏi tập dữ liệu song song và gán nhãn âm vị (PPG) phức tạp, gây khó khăn cho các ngôn ngữ ít dữ liệu như tiếng Việt. Ngược lại, các phương pháp text-free dù linh hoạt hơn nhưng thường gặp hiện tượng rò rỉ thông tin người nói nguồn vào âm thanh đầu ra, dẫn đến việc không phản ánh chính xác giọng người nói mục tiêu.
Để khắc phục, các chuyên gia tại VNPT AI áp dụng giả thuyết rằng các mô hình từ ngôn ngữ giàu tài nguyên (như tiếng Anh) chứa các mối tương quan âm học cơ bản có thể hỗ trợ các ngôn ngữ ít tài nguyên. Phương pháp khắc phục tận dụng các mô hình tiền huấn luyện về Kiểm định người nói (SV) và Nhận dạng giọng nói tự động (ASR) để trích xuất thông tin có giá trị mà không cần dữ liệu gán nhãn văn bản.
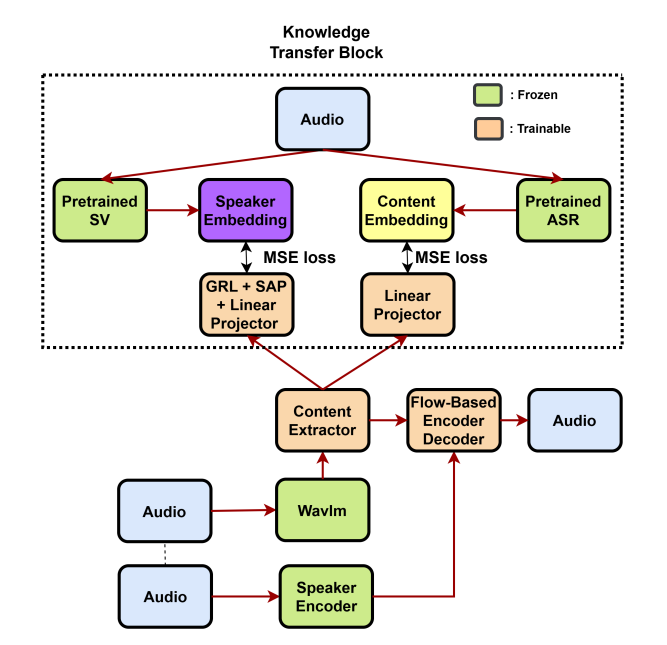
Kiến trúc hệ thống dựa trên KT và DAT
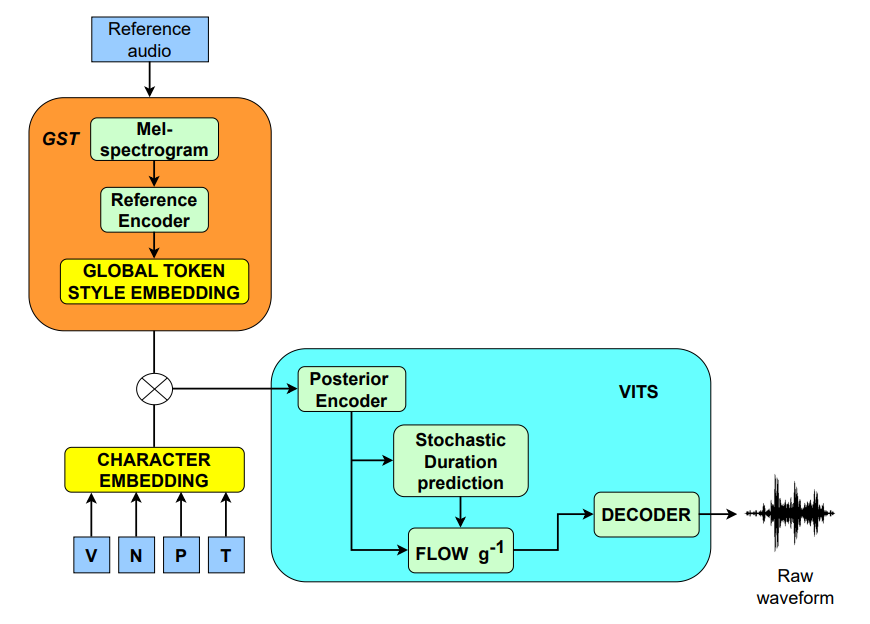
Nhóm chuyên gia đã sử dụng FreeVC làm kiến trúc nền tảng và mở rộng thông qua các khối Chuyển giao tri thức. Hệ thống bao gồm hai thành phần chiến lược:
- Loại bỏ thông tin người nói bằng DAT: Lớp Gradient Reversal Layer (GRL) kết hợp với Statistical Attentive Pooling (SAP) được triển khai phía trên một mô hình Kiểm định người nói (SV) tiếng Anh tiền huấn luyện. Cơ chế này cho phép thực hiện các tính toán trong không gian nhúng của người nói, giúp tách biệt danh tính người nói nguồn khỏi các đặc trưng nội dung (content embeddings) mà không cần nhãn định danh người nói.
- Bảo tồn nội dung thông qua KT: Việc tập trung quá mức vào loại bỏ đặc trưng người nói có thể gây mất mát nội dung ngôn ngữ. Để xử lý vấn đề này, phương pháp chưng cất tri thức (knowledge distillation) đã được thực hiện từ một mô hình ASR tiếng Anh tiền huấn luyện. Các đặc trưng từ mô hình tự giám sát WavLM được căn chỉnh với không gian nhúng của mô hình ASR thông qua hàm mất mát sai số bình phương trung bình (MSE loss).
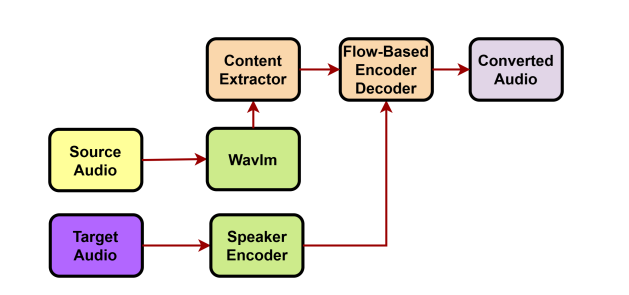
Chiến lược xây dựng dữ liệu và kết quả thực nghiệm
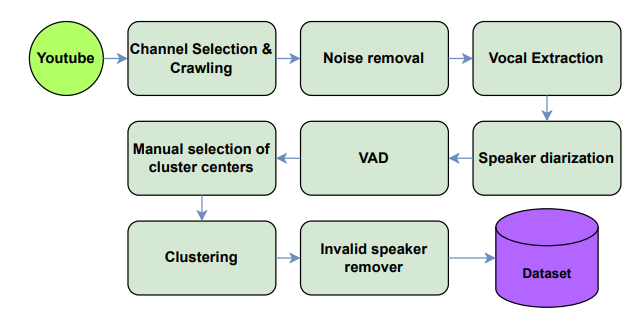
Đội ngũ VNPT AI đã thiết lập một quy trình tự động hóa để xây dựng tập dữ liệu tiếng Việt quy mô 79 giờ từ các kênh YouTube đa dạng. Quy trình này bao gồm các bước khử nhiễu, tách giọng (vocal extraction), phân đoạn (diarization), và phân cụm để đảm bảo tính nhất quán của dữ liệu huấn luyện.
Kết quả đánh giá cho thấy mô hình đề xuất (FreeVC+KT) đạt hiệu suất tối ưu trên cả chỉ số khách quan và chủ quan.
- Độ tự nhiên (O-NAT/MOS): Mô hình đạt điểm MOS 3.63, vượt qua FreeVC nguyên bản (3.41) và Phoneme Hallucinator (3.29). Điều này chứng tỏ việc tận dụng tri thức từ ngôn ngữ giàu tài nguyên giúp cải thiện đáng kể chất lượng âm thanh.
- Độ tương đồng người nói (O-SIM/SMOS): Khả năng chuyển đổi đặc trưng người nói đạt kết quả tốt nhất khi thiết lập các siêu tham số $\alpha=100$ và $\beta=5$, tạo ra sự cân bằng giữa việc giữ lại nội dung và mô phỏng giọng nói mục tiêu.
Mặc dù việc sử dụng mô hình ASR tiếng Anh làm tăng nhẹ tỷ lệ lỗi ký tự (CER) do khác biệt ngôn ngữ, hệ thống vẫn duy trì tính cạnh tranh cao và giải quyết triệt để vấn đề rò rỉ thông tin người nói nguồn.
>>> Đọc thêm: Mô hình O_O-VC: Chiến Lược Dữ Liệu Tổng Hợp Mở Khóa Chuyển Đổi Giọng Nói Any-to-Any Zero-Shot
Kết luận
Nghiên cứu này khẳng định rằng việc tích hợp tri thức từ các ngôn ngữ giàu tài nguyên thông qua DAT và KT là một chiến lược hiệu quả cho bài toán chuyển đổi giọng nói any-to-any trong điều kiện dữ liệu hạn chế. Giải pháp của đội ngũ chuyên gia tại VNPT AI không chỉ loại bỏ sự phụ thuộc vào dữ liệu văn bản gán nhãn mà còn thiết lập một tiêu chuẩn mới về chất lượng tổng hợp giọng nói cho thị trường Việt Nam.
Tác giả: Tumi Tran
Tin mới nhất
14/10/2025
12/10/2025
10/10/2025
07/10/2025
27/09/2025
26/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá