
Tối ưu hóa Mô hình Thị giác - Ngôn ngữ thông qua Tri thức miền

 07/10/2025
07/10/2025
Tại cuộc thi AI City Challenge 2025, VNPT AI đã tạo nên dấu ấn mạnh mẽ khi công bố giải pháp tối ưu hóa mô hình Thị giác - Ngôn ngữ (VLM) thông qua tích hợp tri thức miền. Với số điểm ấn tượng 57.1133, bước đột phá công nghệ này không chỉ khẳng định năng lực làm chủ công nghệ lõi mà còn mở ra hướng đi mới hiệu quả cho bài toán giám sát và đảm bảo an toàn giao thông đô thị thông minh.
Trong lĩnh vực an toàn giao thông đô thị, việc diễn giải chính xác các tình huống động từ dữ liệu video là cơ sở cho các ứng dụng ngăn ngừa tai nạn và điều phối giao thông thông minh. Tại cuộc thi AI City Challenge 2025 (Track 2), đội ngũ chuyên gia của VNPT AI đã công bố một khung giải pháp cải tiến dựa trên CityLLaVA, tích hợp tri thức miền (domain-aware) vào các mô hình thị giác - ngôn ngữ (VLM). Hệ thống đạt số điểm 57.1133, khẳng định hiệu quả của việc kết hợp các mô hình SOTA với cơ chế Expert-Information Fusion (hội tụ thông tin chuyên gia).

Chiến lược tiền xử lý và cấu trúc dữ liệu đa tầng
Khung giải pháp tập trung tối ưu hóa hiệu quả huấn luyện thông qua quy trình tiền xử lý dựa trên khung bao (bounding-box-guided) và lựa chọn góc nhìn chiến lược. Để loại bỏ các dữ liệu nhiễu từ camera, hệ thống tính toán diện tích trung bình của các khung bao người đi bộ và phương tiện nhằm ưu tiên các góc nhìn có độ hiển thị đối tượng cao nhất.
Nhằm tăng cường khả năng căn chỉnh giữa văn bản và hình ảnh, các khung bao được phóng đại và chồng trực tiếp lên khung hình (màu xanh lá cho người đi bộ, màu xanh dương cho phương tiện). Kỹ thuật này đóng vai trò như một chỉ dẫn thị giác (visual prompt), hỗ trợ mô hình tập trung vào các khu vực giàu thông tin ngữ nghĩa. Song song đó, các đoạn mô tả phức tạp được phân tách thành các câu đơn lẻ (sentence-level decomposition) để tạo ra các tín hiệu giám sát chi tiết hơn cho quá trình huấn luyện.
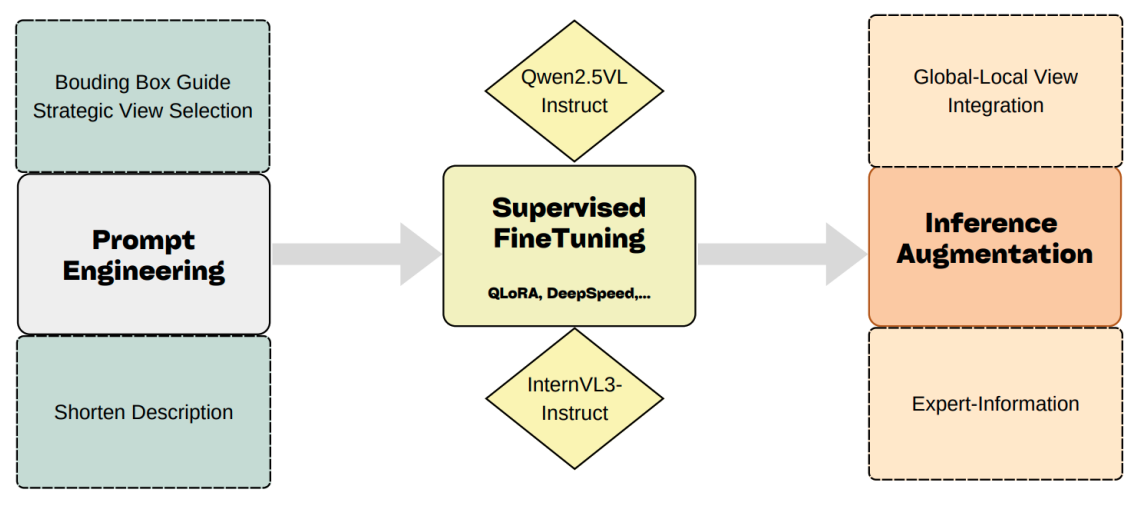
Tích hợp backbone vlm và kỹ thuật thích ứng tham số
Hệ thống khai thác các mô hình thị giác - ngôn ngữ hàng đầu hiện nay là Qwen2.5-VL-72B và InternVL3-78B. Đây là các kiến trúc đã chứng minh khả năng vượt trội trong việc định vị đối tượng và phân tích các sự kiện theo thời gian trong video dài.
Để thích ứng các mô hình tổng quát này vào miền giao thông đặc thù mà không đòi hỏi tài nguyên tính toán quá lớn, đội ngũ chuyên gia đã áp dụng kỹ thuật QLoRA (Quantized Low-Rank Adaptation). Ngoài ra, phương pháp tối ưu hóa chính sách tương đối nhóm (GRPO) được triển khai để hiệu chỉnh khả năng suy luận của mô hình mà không cần các vòng lặp phản hồi từ con người. Thử nghiệm cho thấy Qwen2.5-VL đạt độ chính xác cao nhất trong các tác vụ Hỏi đáp (VQA) với 78.98%.
Cơ chế Expert-Information Fusion
Điểm then chốt trong giải pháp của VNPT AI là việc nhúng trực tiếp các tri thức miền vào câu lệnh (prompt) nhằm giảm thiểu hiện tượng "ảo giác" của AI. Cơ chế này bao gồm ba thành phần chính:
- Sự hiện diện của đối tượng: Xác nhận sự tồn tại thực tế của người đi bộ thông qua hệ thống phát hiện đối tượng YOLO.
- Vị trí không gian tương đối: Phân tích tọa độ khung bao để xác định vị trí của người đi bộ so với điểm nhìn của phương tiện (trái, trước, phải), giúp mô hình hiểu rõ ngữ cảnh không gian.
- Nhận thức của người đi bộ (Awareness): Sử dụng mô hình phát hiện khuôn mặt để suy luận mức độ chú ý của người đi bộ. Nếu khuôn mặt được phát hiện, mô hình giả định người đi bộ có nhận thức về phương tiện; ngược lại, mức độ nhận thức được đánh giá là thấp.

Kết quả thực nghiệm và khả năng ứng dụng
Các nghiên cứu cho thấy độ chính xác của hệ thống tăng dần khi tích hợp thêm các yếu tố tri thức chuyên gia. Khi kết hợp đồng thời thông tin về sự hiện diện, vị trí tương đối và mức độ nhận thức, độ chính xác của tác vụ QA đạt mức tối ưu 80.74%. Điều này chứng minh rằng việc mô tả toàn diện các tín hiệu ngữ cảnh trực tiếp vào prompt giúp VLM đạt được hiệu suất suy luận vượt trội so với việc chỉ sử dụng hình ảnh thô.
Tác giả: Tumi Tran
Tin mới nhất
16/10/2025
14/10/2025
12/10/2025
10/10/2025
27/09/2025
26/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá