
Vision Language Models là gì? Cách thức hoạt động và ứng dụng trong thực tế

 25/09/2025
25/09/2025
Vision Language Models là cầu nối giữa ngôn ngữ và thị giác, đưa AI tiến gần hơn đến AGI - trí tuệ nhân tạo tổng quát. Chúng mở ra khả năng máy móc có thể hiểu thế giới giống con người thông qua chữ viết, hình ảnh, video, âm thanh và ngữ cảnh.
Với khả năng xử lý đồng thời cả hình ảnh và văn bản, Vision Language Models (VLMs) đã tạo ra một bước tiến lớn trong lĩnh vực trí tuệ nhân tạo. VLMs giúp rút ngắn thời gian viết mô tả sản phẩm, phân tích chuẩn xác hình ảnh y tế để đưa ra chẩn đoán. Vậy cụ thể, VLMs là gì, hoạt động như thế nào và được ứng dụng ra sao trong thực tế? Bài viết dưới đây của VNPT AI sẽ giúp bạn khám phá toàn diện.
Vision Language Models (VLMs) là gì?
Mô hình ngôn ngữ thị giác (Vision Language Models - VLMs) là một loại mô hình trí tuệ nhân tạo đa phương thức, kết hợp giữa khả năng xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP) và thị giác máy tính (Computer Vision). Mục tiêu chính của VLMs là học cách hiểu và ánh xạ mối liên hệ giữa dữ liệu hình ảnh và văn bản, từ đó tạo ra phản hồi ngôn ngữ dựa trên đầu vào thị giác hoặc ngược lại.
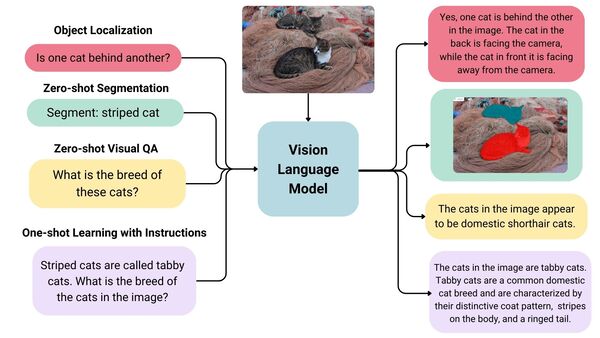
Nhờ khả năng hiểu nội dung từ nhiều dạng dữ liệu, mô hình ngôn ngữ thị giác đang được ứng dụng rộng rãi trong các lĩnh vực như: tìm kiếm hình ảnh thông minh, phân tích nội dung truyền thông, hỗ trợ người khiếm thị, và xây dựng các trợ lý AI thế hệ mới.
Mô hình ngôn ngữ thị giác (VLMs) hoạt động như thế nào?
Vision Language Models vận hành thông qua một kiến trúc đa phương thức với ba thành phần cốt lõi:
- Bộ mã hóa thị giác (Vision Encoder): Trích xuất các đặc trưng của hình ảnh đầu vào, bao gồm thông tin về đối tượng, vị trí, màu sắc, kết cấu và ngữ cảnh trực quan. Kết quả là các biểu diễn đặc trưng số hóa (visual embeddings) giàu thông tin.
- Bộ chuyển đổi (Projector): Chuyển các đặc trưng hình ảnh thành các visual tokens - định dạng mà mô hình ngôn ngữ có thể hiểu (từ, cụm từ,...).
- Mô hình ngôn ngữ lớn (LLM): Sau khi nhận được các token hình ảnh từ projector, LLM sẽ phân tích và diễn giải chúng, Tiếp đó, mô hình sẽ kết hợp kết quả này với văn bản đầu vào (nếu có) để tạo ra phản hồi cuối cùng bằng ngôn ngữ tự nhiên.
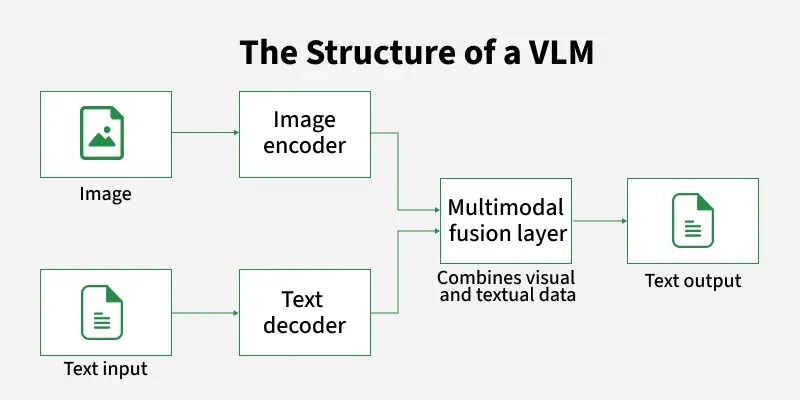
Các thành phần chính của Vision Language Models
Để hiểu và xử lý đồng thời hình ảnh và văn bản, mô hình ngôn ngữ thị giác được thiết kế dựa trên cấu trúc đa thành phần. Trong đó, mỗi thành phần đảm nhận một vai trò riêng biệt nhưng có sự phối hợp chặt chẽ với nhau:
Visual Encoder (Bộ mã hóa hình ảnh)
Đây là bộ phận chịu trách nhiệm trích xuất các yếu tố đặc trưng trực quan, có ý nghĩa từ dữ liệu ảnh hoặc video. Thông qua quá trình mã hóa, hình ảnh được biểu diễn dưới dạng biểu diễn đặc trưng (visual embeddings), chứa thông tin về đối tượng, vị trí, bố cục không gian và các yếu tố hình ảnh liên quan.
Visual encoder thường sử dụng các kiến trúc hiện đại như Vision Transformer (ViT) hoặc CLIP-based models - các kiến trúc đã được huấn luyện trên hàng triệu cặp ảnh - văn bản hoặc dữ liệu hình ảnh lớn. Ngoài ra, mô hình ngôn ngữ thị giác hiện đại còn sử dụng kỹ thuật contrastive learning (học tương phản/học đối chiếu) để học cách phân biệt sự khác biệt giữa các cặp dữ liệu.
Ví dụ: phân biệt giữa một bức ảnh Nhà thờ kiến trúc Gothic và một bức ảnh Nhà thờ kiến trúc Baroque.
Bộ mã hóa hình ảnh (như CLIP-ViT) của LLaVA sẽ học được cách nhận diện các đặc điểm then chốt mà con người sử dụng để phân biệt hai phong cách:
- Kiến trúc Gothic: Các đỉnh tháp thường nhọn, mái vòm cao vút và được trang trí với các cửa sổ kính màu lớn.
- Kiến trúc Baroque: Mái vòm tròn trịa hình dạng quả lê, các chi tiết trang trí cầu kỳ, và thường có những bức tượng hay tác phẩm điêu khắc lộng lẫy.
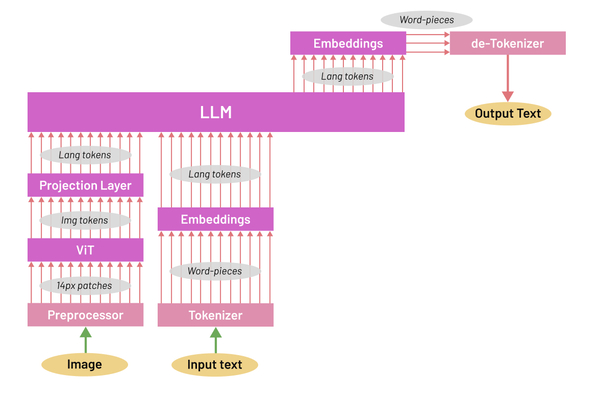
Text Encoder (Bộ mã hóa văn bản)
Text Encoder hoạt động song song với Visual encoder, đảm nhận vai trò phân tích và “hiểu” ngữ nghĩa của câu chữ, văn bản đầu vào. Text encoder thường là một large language model (LLM - mô hình ngôn ngữ lớn), có khả năng chuyển văn bản thành các vector số thể hiện lớp nghĩa trừu tượng của ngôn ngữ.
Trong các kiến trúc như PrefixLM hay Masked Language Modeling (MLM), Text Encoder không chỉ đọc hiểu mà còn học cách dự đoán từ tiếp theo hoặc khôi phục các từ bị ẩn, qua đó giúp mô hình hiểu sâu hơn về ngữ cảnh. Khi kết hợp với đặc trưng hình ảnh từ Visual Encoder, VLMs có thể thực hiện nhiều tác vụ đa phương thức như tạo mô tả ảnh, trả lời câu hỏi liên quan đến hình ảnh hoặc tìm kiếm dữ liệu đa phương thức.
Các phương pháp huấn luyện Vision Language Models
Dưới đây là 4 phương pháp huấn luyện phổ biến được áp dụng rộng rãi trong các mô hình ngôn ngữ thị giác hiện đại:
Contrastive Learning (Học đối chiếu)
Phương pháp này giúp mô hình học cách phân biệt giữa các ảnh - văn bản phù hợp và không phù hợp. Cụ thể, mô hình được huấn luyện để thu hẹp khoảng cách trong không gian biểu diễn giữa những cặp khớp nhau và tăng khoảng cách với những cặp không khớp.
Chẳng hạn: CLIP là ví dụ điển hình áp dụng contrastive learning, được huấn luyện trên 400 triệu cặp ảnh - mô tả để dự đoán chính xác nội dung hình ảnh trong chế độ zero-shot (học không cần ví dụ). Nhờ cách tiếp cận này, các mô hình ngôn ngữ thị giác có thể nhận diện, tìm kiếm hoặc phân loại hình ảnh mà không cần huấn luyện lại trên tập dữ liệu đích.
Masking (Che giấu)
Masking là kỹ thuật huấn luyện hiệu quả giúp mô hình học cách dự đoán và bổ sung các phần dữ liệu bị thiếu hoặc bị ẩn đi (ví dụ từ trong văn bản hoặc vùng ảnh). Cụ thể có 2 phương pháp huấn luyện sau:
- Masked Language Modeling (MLM): Mô hình dự đoán từ bị ẩn trong văn bản dựa trên ngữ cảnh và hình ảnh.
- Masked Image Modeling (MIM): Mô hình tái tạo lại vùng ảnh bị che dựa trên chú thích văn bản.
Ví dụ: FLAVA là mô hình tiêu biểu kết hợp giữa Contrastive Learning và Masking, sử dụng transformer để mã hóa cả hình ảnh và văn bản, sau đó tích hợp bằng cơ chế Cross-attention liên kết 2 loại thông tin.

Generative model training (Huấn luyện mô hình sinh dữ liệu)
Khác với hai phương pháp Contrastive Learning và Masking, huấn luyện mô hình sinh dữ liệu hướng đến việc tạo ra đầu ra mới hoàn toàn, giúp mô hình ngôn ngữ thị giác phát triển khả năng biểu đạt đa chiều, chẳng hạn như:
- Sinh hình ảnh từ văn bản (text-to-image): Điển hình như các mô hình DALL·E, Midjourney, Stable Diffusion,....
- Sinh mô tả văn bản từ hình ảnh (image-to-text): Ví dụ như: tạo caption, tóm tắt nội dung ảnh hoặc chatbot hỏi đáp câu hỏi về ảnh.
Ví dụ: Tạo các công cụ mô tả hình ảnh cho người khiếm thị thông qua việc ứng dụng mô hình sinh dữ liệu.
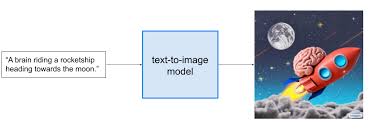
Pretrained Models (Mô hình tiền huấn luyện)
Do việc huấn luyện từ đầu rất tốn kém, nhiều mô hình ngôn ngữ thị giác hiện đại tận dụng sức mạnh của các mô hình đã được huấn luyện sẵn, ví dụ như:
- Vision Encoder từ CLIP, ViT hoặc các kiến trúc mạng nơ-ron tích chập (CNN) như ResNet, EfficientNet.
- Text Encoder từ các mô hình ngôn ngữ lớn như Vicuna, GPT, BERT hoặc LLaMA.
Ví dụ: LLaVA (Large Language and Vision Assistant) là một mô hình ngôn ngữ thị giác mạnh mẽ được tạo ra bằng cách kết hợp mô hình thị giác CLIP-ViT với mô hình ngôn ngữ lớn nguồn mở LLM Vicuna.
Bên cạnh đó, các bộ dữ liệu lớn, đa dạng như COCO, LAION, hoặc ImageNet cũng đóng vai trò thiết yếu trong giai đoạn tiền huấn luyện và fine-tuning (tinh chỉnh) theo từng tác vụ cụ thể, giúp VLMs đạt được hiệu suất cao, có thể ứng dụng rộng rãi.
Ứng dụng của Vision Language Models
Với khả năng xử lý đồng thời dữ liệu hình ảnh và ngôn ngữ, Vision Language Models đang mở ra nhiều ứng dụng đột phá trong các lĩnh vực khác nhau như:
- Tìm kiếm và truy xuất hình ảnh bằng ngôn ngữ tự nhiên: VLMs cho phép người dùng tìm kiếm hình ảnh hoặc video dựa trên các mô tả bằng văn bản. Ví dụ: Tìm sản phẩm trên sàn thương mại điện tử bằng cách gõ từ khóa.
- Chú thích và tóm tắt nội dung hình ảnh: Các mô hình VLMs có thể tự động tạo chú thích chi tiết cho ảnh, hoặc tóm tắt nội dung trực quan từ các video, tài liệu y tế, hay sơ đồ kỹ thuật,.... Ví dụ: mô tả X - quang trong y tế, tóm tắt video bài giảng,....
- Trả lời câu hỏi trực quan (VQA): VLMs có thể trả lời nhanh chóng các câu hỏi liên quan đến hình ảnh. Ví dụ: hệ thống tìm kiếm thông minh bằng hình ảnh, trợ lý ảo trong giáo dục,...
- Tạo nội dung đa phương tiện: Từ các mô tả ngắn, VLMs có thể tạo ra hình ảnh tương ứng (text-to-image) hoặc ngược lại. Ví dụ: ChatGPT thiết kế hình ảnh từ các prompt (mô tả bằng văn bản) người dùng đặt ra.
- Phân đoạn hình ảnh và phát hiện vật thể: VLMs có thể chia nhỏ hình ảnh, phát hiện vật thể, hành vi đáng ngờ,.... Ví dụ: giám sát an ninh tòa nhà, theo dõi dây chuyền sản xuất tự động.
- Hỗ trợ người khiếm thị: Thông qua việc tạo mô tả hình ảnh hoặc trả lời câu hỏi liên quan đến nội dung thị giác, VLMs trở thành công cụ hỗ trợ hiệu quả cho người khiếm thị. Ví dụ: đọc nội dung ảnh cho người mù.
- Thực tế ảo (VR) và thực tế tăng cường (AR): VLMs tạo yếu tố tương tác theo ngữ cảnh, góp phần nâng cao trải nghiệm người dùng trong các ứng dụng VR/AR. Ví dụ: thiết kế game trải nghiệm ứng dụng AR/VR.
- Ứng dụng trong chăm sóc sức khỏe: VLMs hỗ trợ phân tích hình ảnh y tế như ảnh chụp X-quang, MRI,… Ví dụ: phát hiện bất thường từ ảnh MRI, X-quang.
- Tự động kiểm duyệt nội dung: VLMs có thể phát hiện và lọc các nội dung nhạy cảm hoặc nội dung vi phạm chính sách, nâng cao hiệu quả kiểm duyệt. Ví dụ: công cụ kiểm duyệt nội dung tự động trên mạng xã hội.
- Robot và hệ thống tự hành: Các mô hình VLMs giúp robot có thể nhận diện mội trường và giao tiếp tự nhiên với con người. Ví dụ: robot dịch vụ, xe tự lái,…
Những thách thức và hạn chế của VLMs
Dù mở ra nhiều cơ hội ứng dụng trong đời sống và công nghiệp, Vision Language Models vẫn đối mặt với không ít thách thức:
- Sai lệch dữ liệu (Data Bias): VLMs có nguy cơ kế thừa thiên kiến từ dữ liệu huấn luyện hoặc các mô hình tiền huấn luyện. Điều này dẫn đến các kết quả đầu ra mang tính định kiến xã hội, giới tính, sắc tộc… gây ảnh hưởng tiêu cực đến hiệu quả ứng dụng, đặc biệt trong các lĩnh vực nhạy cảm như: y tế, pháp lý, giáo dục.
- Phức tạp và tiêu tốn chi phí triển khai: Sự kết hợp giữa mô hình xử lý hình ảnh và ngôn ngữ khiến VLMs có kiến trúc phức tạp hơn hẳn so với các mô hình đơn lẻ, yêu cầu tài nguyên tính toán lớn hơn, từ đó làm tăng chi phí phát triển, huấn luyện và triển khai thực tế. Đây là rào cản không nhỏ đối với doanh nghiệp nhỏ và tổ chức nghiên cứu độc lập khi dự định triển khai mô hình.

- Khả năng tổng quát hóa còn hạn chế: VLMs thường gặp khó khăn khi xử lý dữ liệu đầu vào vượt ra ngoài phạm vi các kỹ thuật đã được huấn luyện. Điều này gây ảnh hưởng đến khả năng ứng dụng trong các tình huống thực tế có tính bất định cao.
- Xuất hiện “ảo giác” trong kết quả đầu ra (AI Hallucinations): Tương tự như các mô hình ngôn ngữ thuần túy, VLMs có thể tạo ra các kết quả phi thực tế hoặc sai lệch hoàn toàn so với nội dung hình ảnh ban đầu. Do vậy, việc đánh giá và xác thực lại đầu ra từ các Vision Language Models là cần thiết, đặc biệt trong những lĩnh vực đòi hỏi độ chính xác cao như y học, kỹ thuật hay giao thông.
- Hạn chế về độ phân giải và hiểu biết không gian: Phần lớn các VLMs hiện tại sử dụng kiến trúc dựa trên CLIP với kích thước ảnh đầu vào nhỏ (thường 224×224 hoặc 336×336 pixel), khiến chúng khó nhận diện chi tiết nhỏ hoặc vật thể cỡ nhỏ. Ngoài ra, dữ liệu huấn luyện chủ yếu là mô tả ngắn nên các mô hình này còn yếu trong việc định vị vật thể chính xác trong không gian.
- Hạn chế khi xử lý video dài: Với khả năng lưu giữ ngữ cảnh còn hạn chế, VLMs gặp khó khăn trong việc hiểu và phân tích video dài - bao gồm các chuỗi hình ảnh tĩnh, gây tiêu tốn nhiều thời gian và bộ nhớ.
- Khó thích nghi với các lĩnh vực chuyên biệt: VLMs có thể hoạt động kém hiệu quả nếu phải xử lý các tình huống đặc thù khác biệt với dữ liệu huấn luyện, ví dụ như kiểm tra lỗi sản xuất trong một dây chuyền công nghiệp cụ thể, chấm mờ trên ảnh chụp X-quang của một bệnh hiếm gặp.
>>> Đọc thêm: Data modeling là gì?
Tạm kết:
Vision Language Models (VLMs) đang dần khẳng định vai trò then chốt trong kỷ nguyên trí tuệ nhân tạo đa phương thức. Không chỉ giúp máy hiểu và liên kết giữa hình ảnh với ngôn ngữ, các mô hình này còn mở ra loạt ứng dụng đột phá trong y tế, giáo dục, thương mại điện tử, robot thông minh và nhiều lĩnh vực khác.
Dù vẫn đối mặt với thách thức về hiệu suất, độ chính xác và khả năng tùy biến, tiềm năng của VLMs là không thể phủ nhận, hứa hẹn trở thành động lực quan trọng thúc đẩy làn sóng đổi mới tiếp theo trong AI.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá