
Mô hình O_O-VC: Chiến Lược Dữ Liệu Tổng Hợp Mở Khóa Chuyển Đổi Giọng Nói Any-to-Any Zero-Shot

 25/09/2025
25/09/2025
Để giải quyết triệt để vấn đề rò rỉ thông tin (speaker leakage) thường gặp, đội ngũ kỹ sư VNPT AI đã phát triển thành công mô hình O_O-VC. Sử dụng chiến lược dữ liệu tổng hợp và cơ chế căn chỉnh một-một, công nghệ này mở ra kỷ nguyên mới cho các tác vụ chuyển đổi giọng nói Any-to-Any Zero-Shot với độ chính xác vượt trội.

Trong lĩnh vực xử lý giọng nói tiên tiến, Chuyển đổi Giọng nói (Voice Conversion - VC) đóng vai trò then chốt, nhằm mục đích biến đổi giọng nói của người nói nguồn thành giọng nói của người nói mục tiêu, trong khi vẫn bảo toàn tuyệt đối nội dung ngôn ngữ gốc. Theo truyền thống, các phương pháp VC tập trung vào việc tách biệt danh tính người nói và thông tin ngôn ngữ thành các biểu diễn độc lập. Tuy nhiên, việc tách biệt đặc trưng (feature disentanglement) hiệu quả luôn là một thách thức lớn. Thất bại trong quá trình này thường dẫn đến rò rỉ thông tin người nói (speaker leakage), khiến giọng nói được chuyển đổi vẫn giữ lại những đặc điểm không mong muốn của nguồn, làm giảm chất lượng tổng hợp.
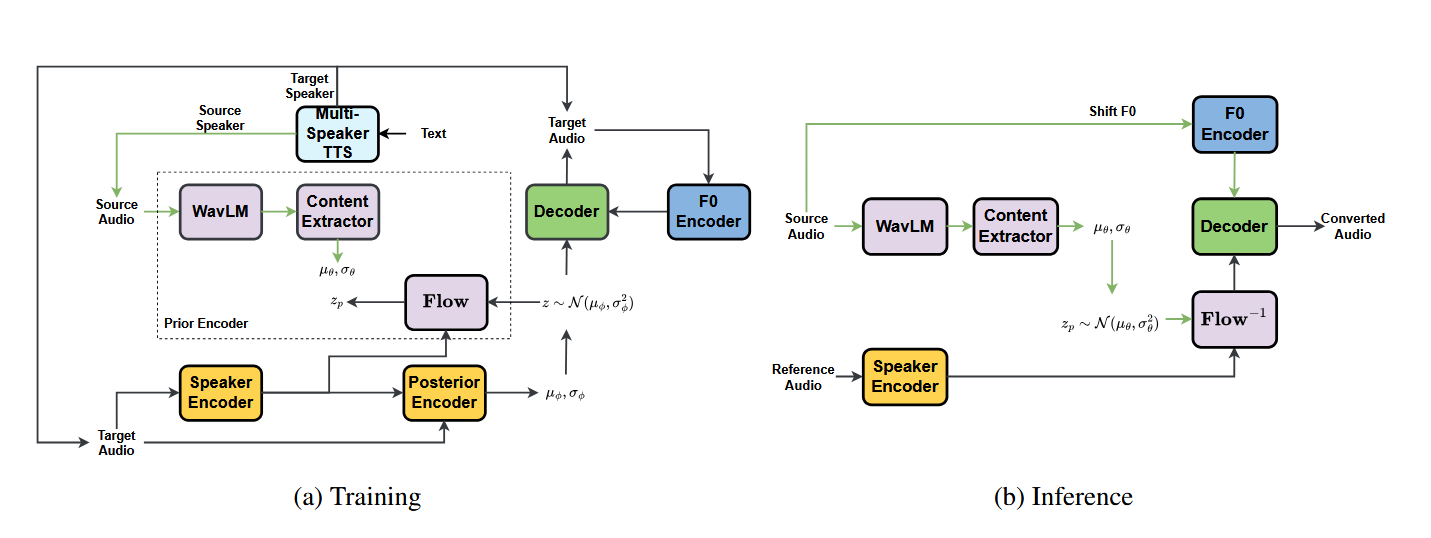
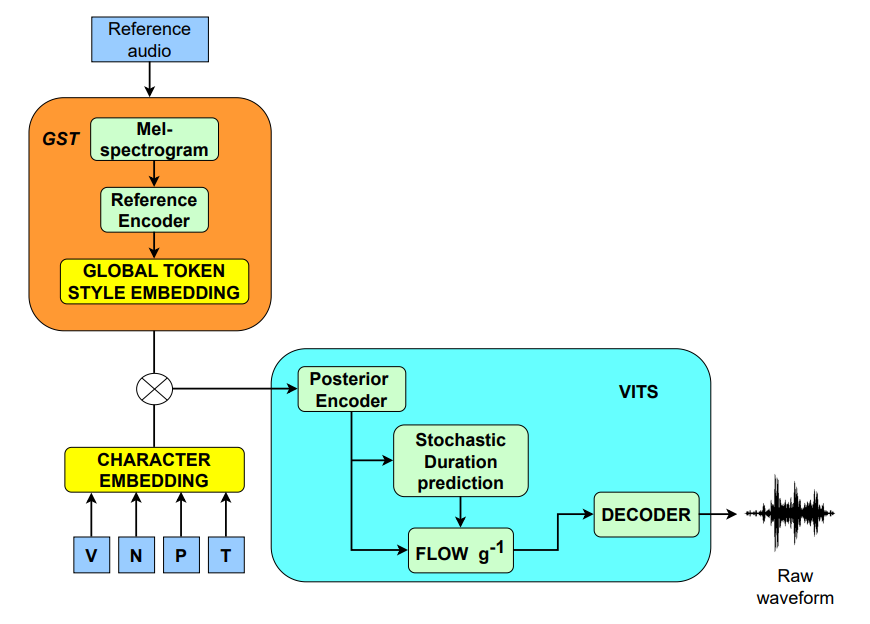
Để giải quyết những hạn chế cố hữu này, đội ngũ kỹ sư VNPT AI chúng tôi giới thiệu phương pháp tiếp cận O_O-VC (Synthetic Data-Driven One-to-One Alignment for Any-to-Any Voice Conversion). Phương pháp này khai thác dữ liệu giọng nói tổng hợp chất lượng cao được tạo ra bởi mô hình Text-to-Speech (TTS) đã được huấn luyện trước.
Thách thức truyền thống: Nút thắt Tách biệt Đặc trưng
Các hệ thống VC hiện đại thường gặp phải rào cản từ cả hai nhóm phương pháp chính:
- Phương pháp dựa trên văn bản (Text-Based): Các biểu diễn nội dung như PPGs (Phonetic Posteriorgrams) thường không thể nắm bắt được các thuộc tính tinh tế, độc lập với người nói như ngữ điệu, giọng điệu (accent) và phong cách nói. Hơn nữa, việc dựa vào mô hình Nhận dạng Giọng nói Tự động (ASR) để trích xuất nội dung có thể gây ra lỗi nhận dạng hoặc lỗi căn chỉnh, ảnh hưởng tiêu cực đến chất lượng chuyển đổi.
- Phương pháp không dựa trên văn bản (Text-Free): Các phương pháp này sử dụng Học tự giám sát (SSL) để trích xuất nội dung. Dù đã áp dụng nhiều kỹ thuật nén (như vector quantization hay bottleneck) để loại bỏ đặc điểm người nói, chúng vẫn khó có thể loại bỏ hoàn toàn thông tin người nói khỏi biểu diễn nội dung. Điều này dẫn đến tình trạng rò rỉ giọng nói, làm giảm độ tương đồng với giọng nói mục tiêu mong muốn.
O_O-VC: Đột phá với Dữ liệu Tổng hợp và Căn chỉnh Trực tiếp
O_O-VC loại bỏ sự cần thiết của việc tái tạo âm thanh phức tạp và quá trình tách biệt đặc trưng không hoàn hảo.
Việc sử dụng các cặp dữ liệu tổng hợp được tạo ra từ cùng một nội dung ngôn ngữ nhưng khác nhau về danh tính người nói mang lại một tín hiệu giám sát rõ ràng và trực tiếp:
- Căn chỉnh Một-đối-một (One-to-One Alignment): Vì cả âm thanh nguồn và âm thanh mục tiêu đều được tạo ra từ cùng một nội dung, chúng đảm bảo căn chỉnh chính xác từng khung (frame-level alignment). Điều này cho phép mô hình học một ánh xạ trực tiếp từ âm thanh nguồn sang âm thanh mục tiêu, đơn giản hóa đáng kể quá trình học so với việc ánh xạ qua các biểu diễn văn bản ẩn.
- Giảm thiểu Rò rỉ Người nói: Chiến lược huấn luyện dựa trên dữ liệu tổng hợp đã được chứng minh là cải thiện đáng kể khả năng loại bỏ thông tin người nói khỏi âm thanh nguồn. Các thử nghiệm định lượng cho thấy O_O-VC đạt điểm thấp hơn đáng kể so với mô hình FreeVC trên các chỉ số đánh giá phân cụm (ARI, NMI, Silhouette Score), khẳng định khả năng vô hiệu hóa danh tính người nói nguồn tốt hơn.
Khả năng Tổng quát hóa Zero-Shot và Thích ứng Đa ngôn ngữ
Để đảm bảo mô hình hoạt động hiệu quả trong các kịch bản chuyển đổi giọng nói zero-shot (người nói mục tiêu chưa từng xuất hiện trong quá trình đào tạo) và thích ứng với các miền âm thanh thực tế, chúng tôi áp dụng chiến lược đào tạo hai pha linh hoạt:
- Pha 1 (Dữ liệu Tổng hợp): Huấn luyện mô hình để học các biểu diễn nội dung mạnh mẽ, độc lập với người nói.
- Pha 2 (Tinh chỉnh): Tinh chỉnh mô hình bằng kho ngữ liệu giọng nói thực tế lớn (như LibriSpeech) sử dụng mục tiêu tái tạo âm thanh. Giai đoạn này giúp mô hình thích ứng với các người nói mới và quan trọng hơn là thích ứng với các ngôn ngữ mới.
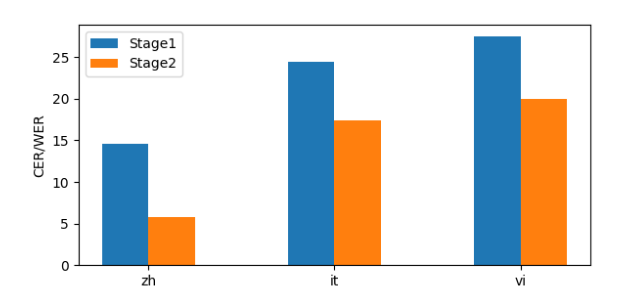
Khả năng thích ứng của O_O-VC đã được kiểm chứng thông qua việc tinh chỉnh trên các ngôn ngữ chưa từng thấy, bao gồm tiếng Trung (ZH), tiếng Ý (IT) và đặc biệt là tiếng Việt (VI). Kết quả cho thấy việc tinh chỉnh Pha 2 giúp mô hình thích nghi hiệu quả với bất kỳ ngôn ngữ nào chỉ bằng dữ liệu âm thanh, không yêu cầu dữ liệu đã dán nhãn.
VNPT AI: Dẫn đầu Ứng dụng Công nghệ Giọng nói Đa ngôn ngữ
Đội ngũ chuyên gia của VNPT AI đang tích cực nghiên cứu và ứng dụng những tiến bộ này để xây dựng các giải pháp giọng nói chất lượng cao cho thị trường Việt Nam và các ngôn ngữ có nguồn lực thấp (low-resource settings). Nhờ khả năng thích ứng ngôn ngữ mạnh mẽ của O_O-VC, chúng tôi có thể mang lại trải nghiệm chuyển đổi giọng nói tự nhiên, dễ hiểu và linh hoạt, đáp ứng nhu cầu đa dạng từ cá nhân đến doanh nghiệp.
Hiệu suất Đạt được
Các thử nghiệm rộng rãi xác nhận hiệu quả vượt trội của O_O-VC so với các phương pháp tiên tiến khác trong kịch bản zero-shot.
- Bảo toàn Nội dung: Mô hình O_O-VC đạt hiệu suất tốt nhất về tính nhất quán nội dung, với tỷ lệ lỗi từ (WER) thấp nhất (1.74%) và giảm tương đối 16.35% WER so với các mô hình đối thủ.
- Độ tương đồng Người nói: Đạt được cải thiện 5.91% về Độ tương đồng Cosine của Bộ mã hóa Người nói (SECS). Về đánh giá chủ quan, O_O-VC đạt điểm cân bằng (B-MOS, trung bình của độ tự nhiên và độ tương đồng) cao nhất (3.45), khẳng định khả năng duy trì sự cân bằng mạnh mẽ giữa độ tự nhiên và độ tương đồng giọng nói.
Kết luận
Khung chuyển đổi giọng nói O_O-VC, dựa trên chiến lược dữ liệu tổng hợp và căn chỉnh trực tiếp, đã thiết lập một tiêu chuẩn mới về hiệu suất trong các kịch bản VC any-to-any zero-shot. Phương pháp này không chỉ giải quyết triệt để vấn đề rò rỉ thông tin người nói mà còn cung cấp một giải pháp ổn định, linh hoạt, và có khả năng thích ứng cao với các người nói và ngôn ngữ mới, bao gồm tiếng Việt. Những kết quả này củng cố vị thế của VNPT AI trong việc cung cấp các công nghệ giọng nói AI tiên tiến, giúp định hình tương lai của giao tiếp kỹ thuật số.
Tác giả: Tumi Tran
Tin mới nhất
16/10/2025
14/10/2025
12/10/2025
10/10/2025
07/10/2025
27/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá