
Tổng quan về mô hình Self-supervised learning trong AI

 04/11/2025
04/11/2025
Self-supervised learning được xem là một tập con của học không giám sát. Các mô hình nổi tiếng như GPT, BERT đều sử dụng Self-supervised learning để học từ dữ liệu lớn mà không cần n
Trong bối cảnh hơn 402 triệu terabyte dữ liệu được tạo ra mỗi ngày, việc gán nhãn thủ công cho dữ liệu trở nên tốn kém và khó thực hiện trên quy mô lớn. Trước sự bùng nổ dữ liệu khổng lồ này, phương pháp self-supervised learning giúp máy tự học từ dữ liệu không gán nhãn, được coi là một hướng tiếp cận sáng giá, tối ưu hóa việc tận dụng nguồn dữ liệu dồi dào mà không cần tốn chi phí gán nhãn. Cùng VNPT AI khám phá xem Self-supervised learning là gì trong bài viết dưới đây.
Self-supervised learning là gì?
Self-supervised learning (học tự giám sát - SSL) là một kỹ thuật học máy, trong đó mô hình học từ dữ liệu không gán nhãn nhưng vẫn giải quyết được các nhiệm vụ vốn thường yêu cầu dữ liệu có nhãn. Thay vì phụ thuộc vào các bộ dữ liệu đã được gán nhãn sẵn, mô hình sẽ tự tạo ra các nhãn ngầm từ dữ liệu chưa có cấu trúc, giúp khai thác tối đa nguồn dữ liệu lớn mà không cần tốn công sức gán nhãn thủ công.
Self-supervised learning hoạt động như thế nào?
Self-supervised learning giúp mô hình học từ dữ liệu chưa gán nhãn bằng cách tạo ra các bài tập giả lập. Trong các bài tập này, chính dữ liệu thô được dùng làm đáp án tạm thời, cho phép mô hình học cách hiểu và biểu diễn dữ liệu mà không cần nhãn thật.
Sau khi học được những biểu diễn này, mô hình sẽ được tinh chỉnh với một lượng nhỏ dữ liệu có nhãn để phục vụ các nhiệm vụ cụ thể. Cách này giúp tiết kiệm rất nhiều công sức và chi phí so với việc gán nhãn toàn bộ dữ liệu.
Hai cách tiếp cận phổ biến của SSL là:
- Self-predictive learning: dự đoán một phần dữ liệu bị ẩn đi dựa trên phần còn lại.
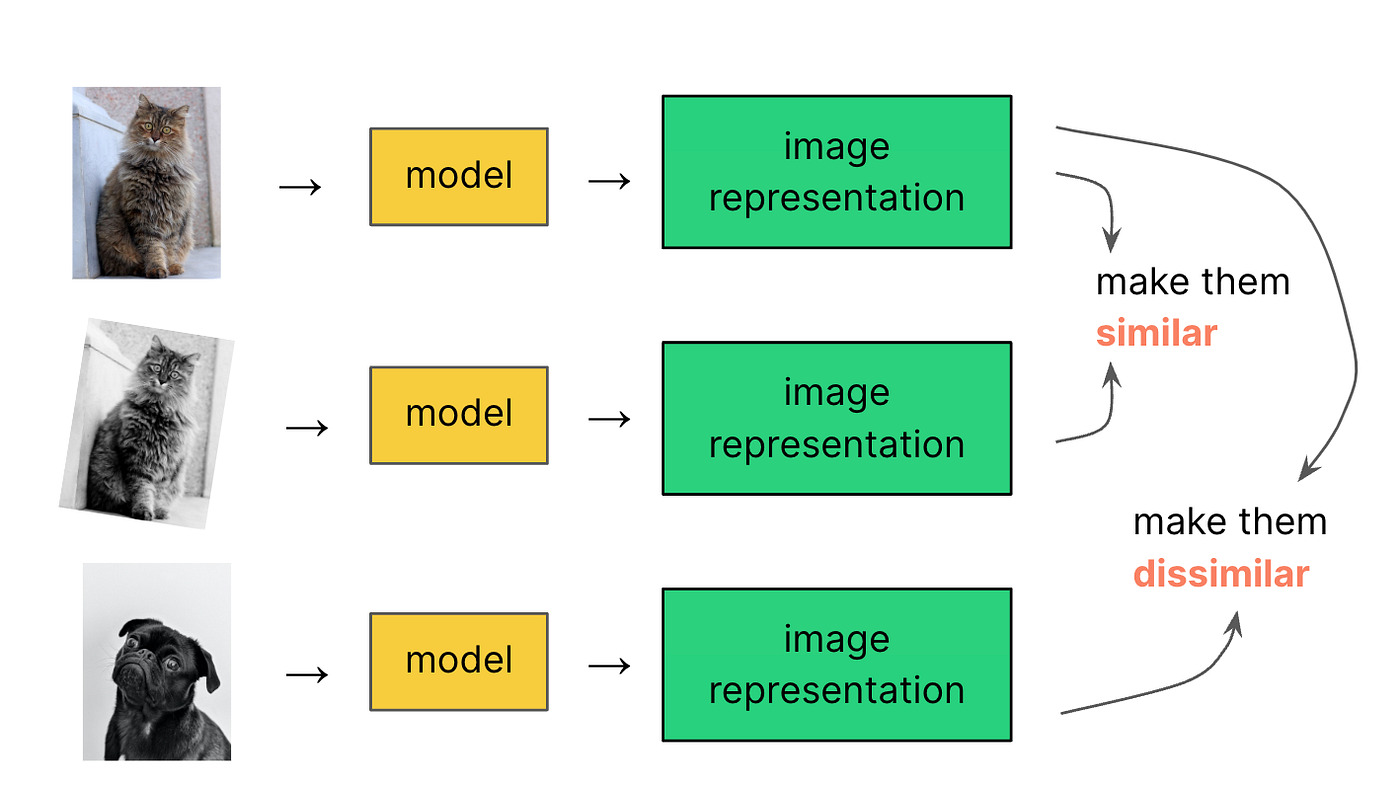
- Contrastive learning: học cách so sánh và phân biệt các dữ liệu tương tự hoặc khác nhau.
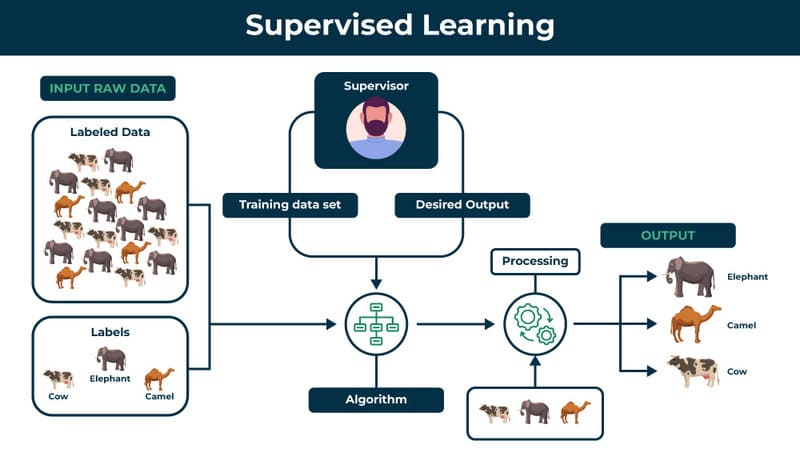
Sự khác biệt giữa Supervised, Unsupervised và Self-supervised learning
Trong lĩnh vực học máy, các mô hình có thể học từ dữ liệu theo nhiều cách khác nhau, tùy thuộc vào mức độ sẵn có của nhãn dữ liệu. Có 3 phương pháp phổ biến nhất là supervised learning, unsupervised learning và self-supervised learning. Trong đó, mỗi phương pháp có cách thức hoạt động, ưu điểm và hạn chế riêng:
Tiêu chí | Supervised Learning (Học có giám sát) | Unsupervised Learning (Học không giám sát) | Self-supervised Learning (Học tự giám sát) |
| Dữ liệu | Có gán nhãn đầy đủ | Không có nhãn | Dữ liệu không nhãn, tự tạo nhãn giả |
| Cách học | Học từ cặp dữ liệu và nhãn có sẵn | Tìm cấu trúc hoặc nhóm trong dữ liệu | Tạo bài tập giả lập để học biểu diễn dữ liệu, sau đó tinh chỉnh bằng các dữ liệu có nhãn |
| Chi phí gán nhãn | Cao (cần nhiều dữ liệu có nhãn) | Không cần gán nhãn | Thấp hơn vì tận dụng dữ liệu không nhãn |
| Ưu điểm | Độ chính xác cao nếu có nhiều nhãn chất lượng | Khai thác dữ liệu lớn không nhãn | Giảm phụ thuộc vào dữ liệu gán nhãn, tận dụng dữ liệu dồi dào |
| Hạn chế | Phụ thuộc nhiều vào dữ liệu có nhãn | Kết quả khó đánh giá chính xác | Cần thiết kế bài tập giả phù hợp để hiệu quả |
| Ứng dụng thực tế | Phân loại ảnh, phát hiện đối tượng, xử lý ngôn ngữ tự nhiên (NLP) | Phân cụm, giảm chiều dữ liệu, phát hiện bất thường. | Học biểu diễn ảnh, phân tích cảm xúc, trả lời câu hỏi, dịch máy. |
Ưu nhược điểm của Self-supervised learning
Self-supervised learning có những ưu điểm và hạn chế mà người dùng cần cân nhắc trước khi sử dụng.
Ưu điểm
- Giảm phụ thuộc vào dữ liệu gán nhãn: Mô hình có thể tự học từ dữ liệu thô mà không cần quá nhiều dữ liệu đã được gắn nhãn sẵn, giúp tiết kiệm thời gian và chi phí gán nhãn.
- Cải thiện khả năng khái quát hóa: Giúp mô hình dự đoán chính xác hơn với dữ liệu mới nhờ học từ cấu trúc tự nhiên của dữ liệu thay vì chỉ ghi nhớ các ví dụ cụ thể.
- Dễ áp dụng cho nhiều bài toán khác nhau: Sau khi được huấn luyện, mô hình có thể điều chỉnh nhanh để giải quyết các tác vụ khác mà không phải học lại từ đầu.
- Khả năng mở rộng tốt: Có thể xử lý tập dữ liệu lớn mà không cần gán nhãn thủ công, đặc biệt hữu ích trong các lĩnh vực có lượng dữ liệu khổng lồ.
Nhược điểm
Chất lượng tín hiệu học chưa ổn định: Vì mô hình tự tạo ra “nhãn giả” từ dữ liệu, tín hiệu học có thể bị nhiễu hoặc thiếu chính xác so với dữ liệu được gán nhãn bởi con người, dẫn đến kết quả không tối ưu.
- Không phù hợp với mọi loại bài toán: SSL có thể kém hiệu quả với những bài toán phức tạp hoặc dữ liệu quá rời rạc, khó tìm ra cấu trúc để học.
- Huấn luyện phức tạp hơn: Một số kỹ thuật đòi hỏi quá trình thiết lập và tinh chỉnh phức tạp hơn so với phương pháp học có giám sát truyền thống.
Ứng dụng của Self-supervised learning
Self-supervised learning ngày càng được áp dụng rộng rãi nhờ khả năng tận dụng dữ liệu chưa gán nhãn. Dưới đây là một số ứng dụng phổ biến:
- Xử lý ngôn ngữ tự nhiên (NLP): Self-supervised learning giúp huấn luyện các mô hình ngôn ngữ lớn như BERT, ChatGPT. Nhờ đó, máy có thể dịch văn bản, tóm tắt nội dung, phân tích cảm xúc hoặc trả lời câu hỏi mà không cần khối lượng lớn dữ liệu gán nhãn.
- Thị giác máy tính (Computer Vision): SSL được sử dụng để nhận diện hình ảnh, phân loại đối tượng và nhận diện khuôn mặt. Phương pháp này giúp khai thác kho dữ liệu hình ảnh khổng lồ mà không cần gắn nhãn từng ảnh, tiết kiệm nhiều công sức.

- Y tế và chẩn đoán hình ảnh: Trong y học, SSL hỗ trợ phân tích các hình ảnh như X-quang, MRI hay CT scan. Điều này giúp phát hiện bất thường nhanh hơn và giảm chi phí gán nhãn vốn rất tốn kém trong lĩnh vực y tế.
- Nhận dạng giọng nói và tổng hợp âm thanh: SSL được dùng để huấn luyện các hệ thống trợ lý ảo hoặc phần mềm chuyển giọng nói thành văn bản. Đồng thời, nó còn giúp cải thiện khả năng tổng hợp giọng nói, tạo ra giọng nói tự nhiên hơn.
Tạm kết
Bài viết trên của VNPT AI giúp bạn đọc nắm được thông tin về Self-supervised learning. Với khả năng tận dụng dữ liệu chưa gán nhãn và tạo ra những biểu diễn hữu ích cho nhiều bài toán khác nhau, self-supervised learning đang dần trở thành một trong những hướng tiếp cận quan trọng của học máy hiện đại. Trong tương lai, khi dữ liệu ngày càng nhiều và nhu cầu giảm chi phí gán nhãn ngày càng lớn, self-supervised learning hứa hẹn sẽ mở ra thêm nhiều cơ hội ứng dụng và cải tiến vượt bậc.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá