
Out-of-Vocabulary (OOV): Thách thức và giải pháp trong xử lý ngôn ngữ tự nhiên

 03/12/2025
03/12/2025
Out-of-Vocabulary (OOV) là những từ không có trong từ vựng mà mô hình đã được huấn luyện. OOV làm giảm hiệu năng của mô hình, làm suy giảm ngữ nghĩa và tăng lỗi trong các bài toán NLP
Trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP), hiện tượng Out-of-Vocabulary (OOV) thường gây khó khăn cho các ứng dụng như dịch máy, nhận diện giọng nói hay phân tích văn bản. Bài viết này của VNPT AI sẽ phân tích nguyên nhân, tác động và các giải pháp giúp hạn chế tình trạng OOV. Từ đó các doanh nghiệp có thể nâng cao hiệu quả của các hệ thống NLP.
Out-of-Vocabulary (OOV) là gì?
Trong lĩnh vực NLP, thuật ngữ OOV được dùng để chỉ những từ mà mô hình học máy chưa từng gặp trong quá trình huấn luyện. Các từ này không nằm trong tập từ vựng đã được định nghĩa sẵn của mô hình. Vì vậy khi xuất hiện trong văn bản hoặc giọng nói, chúng thường gây ra khó khăn trong việc xử lý.

Do mô hình NLP phụ thuộc nhiều vào vốn từ đã học để hiểu và phân tích dữ liệu đầu vào, sự xuất hiện của một từ OOV có thể dẫn đến lỗi hoặc giảm độ chính xác. Ví dụ, một trợ lý ảo bằng giọng nói khi nghe thấy một từ lóng mới hoặc một thuật ngữ y khoa hiếm gặp mà chưa từng được huấn luyện trước đó. Hệ thống có thể không hiểu đúng hoặc không đưa ra phản hồi phù hợp, ảnh hưởng đến hiệu quả hoạt động của ứng dụng.
Nguyên nhân dẫn đến Out-of-Vocabulary
Hiện tượng OOV xuất phát từ nhiều yếu tố khác nhau như:
Tính biến đổi của ngôn ngữ
Một trong những nguyên nhân chính gây ra hiện tượng OOV là ngôn ngữ luôn thay đổi với sự xuất hiện liên tục của từ mới đến từ xu hướng văn hóa, công nghệ hay mạng xã hội. Những từ lóng, hashtag hoặc cụm từ viết tắt phổ biến trên Internet thường không có trong vốn từ vựng gốc của mô hình. Tương tự, các thuật ngữ chuyên ngành mới cũng dễ trở thành OOV nếu hệ thống chưa được cập nhật.
Thiếu dữ liệu huấn luyện
Đa số mô hình NLP được huấn luyện trên một tập dữ liệu cố định. Nếu dữ liệu không đủ lớn hoặc thiếu tính đa dạng, nhiều từ sẽ không xuất hiện trong quá trình huấn luyện và bị loại khỏi vốn từ vựng. Điều này đặc biệt rõ trong các lĩnh vực chuyên môn như y tế, pháp luật, nơi thường xuyên sử dụng thuật ngữ kỹ thuật mà mô hình phổ thông không được “làm quen” từ trước.
Sự khác biệt về ngôn ngữ và cấu trúc phức tạp
Ngoài ra, sự khác biệt về đặc trưng ngôn ngữ và cấu trúc từ vựng - câu cũng là nguyên nhân quan trọng dẫn đến hiện tượng Out-of-Vocabulary. Một số ngôn ngữ có hệ thống hình thái phức tạp (chẳng hạn biến đổi theo thì, giống, số, cách), hoặc có nhiều biến thể vùng miền, tạo ra rất nhiều dạng từ khác nhau mà mô hình không được huấn luyện đầy đủ. Bên cạnh đó, cấu trúc câu đa dạng hoặc khác biệt về cách ghép từ trong mỗi ngôn ngữ cũng có thể làm nảy sinh những cụm từ mà mô hình chưa từng gặp. Từ đó dẫn đến việc mô hình không thể nhận diện hoặc xử lý chính xác.
Tác động của OOV đến các ứng dụng của NLP
Khi mô hình gặp những từ ngoài vốn từ, hiệu quả xử lý sẽ suy giảm đáng kể. Cụ thể, OOV ảnh hưởng trực tiếp đến các khía cạnh sau:
Giảm độ chính xác
Hầu hết các mô hình NLP đều dựa vào vốn từ đã được định nghĩa sẵn để phân tích ngôn ngữ. Khi gặp từ OOV, hệ thống có thể hiểu sai ngữ nghĩa hoặc đưa ra kết quả không chính xác. Trong các tác vụ như phân loại văn bản hay phân tích cảm xúc, chỉ một từ quan trọng thuộc dạng OOV cũng có thể làm sai lệch toàn bộ kết quả.

Ảnh hưởng đến hiệu suất nhận diện thực thể (NER)
Trong bài toán Nhận diện thực thể (Named Entity Recognition - NER), việc xác định đúng tên riêng của người, địa điểm hoặc tổ chức đóng vai trò then chốt. Tuy nhiên, những tên mới như công ty khởi nghiệp, sản phẩm vừa ra mắt hoặc nhân vật trên mạng xã hội… thường là OOV. Do đó, hệ thống dễ bỏ sót hoặc gán nhãn sai, làm giảm chất lượng trích xuất thông tin và các ứng dụng liên quan như tìm kiếm thông minh hay tóm tắt tin tức.
Giảm hiệu quả nhận diện giọng nói và dịch máy
Đối với nhận diện giọng nói, từ OOV thường bị nhận dạng nhầm thành những từ phát âm gần giống trong tập từ vựng đã học, gây ra lỗi trong phiên âm hoặc mệnh lệnh thoại. Ví dụ, một trợ lý ảo có thể nghe nhầm tên một ứng dụng mới và thực hiện sai yêu cầu của người dùng. Trong dịch máy, OOV dẫn đến tình trạng bỏ sót hoặc thay thế bằng từ không liên quan, làm giảm độ chính xác và tính tự nhiên của bản dịch.
Khó khăn trong xử lý dữ liệu phi cấu trúc
Trong môi trường dữ liệu mở như mạng xã hội, văn bản thường chứa nhiều ký hiệu, hashtag, từ viết tắt hoặc biểu tượng cảm xúc. Đây đều là những yếu tố ngoài vốn từ, khiến mô hình NLP khó phân tích chính xác. Kết quả là các ứng dụng như phân tích xu hướng, lọc nội dung hay hệ thống gợi ý bị giảm hiệu quả đáng kể.
Làm sao để giảm thiểu tình trạng OOV?
Dưới đây là những giải pháp nhằm giảm thiểu tình trạng OOV trong NLP:
Cập nhật vốn từ động và theo thời gian thực
Một trong những hướng quan trọng là xây dựng mô hình có khả năng mở rộng vốn từ ngay khi gặp từ mới. Nhờ đó, hệ thống luôn thích ứng kịp với tiếng lóng, thuật ngữ mới hoặc xu hướng ngôn ngữ mà không cần huấn luyện lại từ đầu.
Giải pháp đa ngôn ngữ và xuyên ngôn ngữ
OOV thường xuất hiện nhiều hơn ở các ngôn ngữ ít tài nguyên. Các mô hình đa ngữ hoặc kỹ thuật như transfer learning và zero-shot learning cho phép tận dụng kiến thức từ ngôn ngữ mạnh hơn để hệ thống xử lý tốt từ mới trong nhiều bối cảnh.
Xử lý từ chuyên ngành
Trong các lĩnh vực như y tế, luật hay công nghệ, thuật ngữ đặc thù liên tục xuất hiện. Huấn luyện mô hình trên dữ liệu chuyên ngành kết hợp cùng embeddings theo miền giúp hệ thống hiểu và xử lý chính xác hơn các từ chuyên biệt này.
Học tương tác với con người
Mô hình có thể giảm OOV hiệu quả hơn nếu tận dụng phản hồi trực tiếp từ người dùng hoặc chuyên gia. Cơ chế này cho phép hệ thống nhanh chóng bổ sung từ mới, đồng thời theo kịp sự biến đổi nhanh của ngôn ngữ thực tế.
Hiểu ngữ cảnh nâng cao
Các mô hình NLP hiện đại đang hướng tới khả năng nắm bắt ngữ cảnh sâu hơn, không chỉ trong câu mà cả toàn văn bản. Việc tích hợp dữ liệu đa phương thức như văn bản, hình ảnh và âm thanh cũng giúp mô hình hiểu chính xác hơn các từ mới hoặc hiếm gặp.
Cách phát hiện và xử lý OOV
Để giải quyết vấn đề OOV trong NLP, các nhà nghiên cứu đã đưa ra nhiều hướng tiếp cận khác nhau gồm:
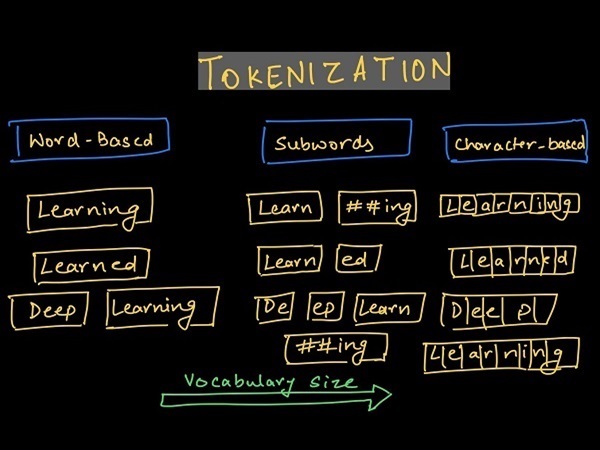
Subword Tokenization (Phân tách từ thành đơn vị nhỏ hơn)
Phân tách từ thành các đơn vị nhỏ hơn (subword) là một trong những phương pháp phổ biến để xử lý OOV. Thay vì coi mỗi từ là một khối riêng biệt, phương pháp này chia nhỏ từ thành tiền tố, hậu tố hoặc chuỗi ký tự. Điều này giúp mô hình xây dựng nghĩa của từ mới dựa trên các phần quen thuộc.
Ví dụ, BPE tách từ thành các cặp ký tự thường gặp, trong khi WordPiece (dùng trong BERT) chia nhỏ từ hiếm thành các đơn vị cơ bản hơn. Nhờ vậy, ngay cả những từ chưa xuất hiện trong tập huấn luyện vẫn có thể được mô hình xử lý và biểu diễn chính xác hơn.
Mô hình ngữ cảnh dựa trên Transformer
Sự xuất hiện của các mô hình Transformer như BERT, GPT, T5 mở ra cách tiếp cận mới trong xử lý OOV. Khác với phương pháp biểu diễn từ tĩnh (static word embeddings) như Word2Vec hay GloVe, Transformer phân tích ngữ cảnh sâu hơn và mối quan hệ giữa các từ trong câu. Ví dụ, BERT và GPT có thể dự đoán hoặc diễn giải một từ lạ bằng cách xem xét toàn bộ câu. Trong khi đó, T5 linh hoạt hơn khi coi mọi tác vụ NLP là một bài toán sinh văn bản. Nhờ cơ chế này, mô hình không chỉ nhận diện từ mới mà còn hiểu được nghĩa tiềm ẩn của chúng trong ngữ cảnh.
Data Augmentation (Tăng cường dữ liệu)
Một cách khác để giảm OOV là mở rộng tập dữ liệu huấn luyện thông qua các kỹ thuật tăng cường dữ liệu. Việc tạo thêm dữ liệu đa dạng giúp mô hình quen với nhiều dạng ngôn ngữ hơn. Một cách điển hình là thay thế từ bằng từ đồng nghĩa khác để bổ sung các biến thể diễn đạt khác nhau. Bên cạnh đó còn có cách back-translation (dịch một câu sang ngôn ngữ khác rồi dịch ngược lại) nhằm tạo ra những cặp câu mới. Cách làm này không chỉ giúp giảm OOV mà còn tăng tính linh hoạt và khả năng khái quát của mô hình.
Mô hình mở rộng vốn từ (Open-Vocabulary Models)
Khác với các mô hình truyền thống vốn có từ vựng cố định, mô hình mở rộng vốn từ cho phép thích nghi với dữ liệu mới trong quá trình hoạt động. Adaptive Softmax là một ví dụ điển hình khi chia vốn từ thành nhiều cụm dựa trên tần suất xuất hiện. Nhờ đó hệ thống có thể xử lý hiệu quả cả từ phổ biến lẫn từ hiếm. Ngoài ra, một số mô hình còn có khả năng học từ phản hồi của người dùng. Chẳng hạn như chatbot hoặc trợ lý ảo có thể ghi nhận và cập nhật các từ mới về tên sản phẩm hoặc tiếng lóng. Qua đó giảm dần tình trạng OOV trong các lần tương tác tiếp theo.
Kết luận
Những phân tích trên của VNPT AI cho thấy OOV là một trong những rào cản lớn đối với sự phát triển của NLP và ứng dụng AI liên quan đến ngôn ngữ. Tuy nhiên, nhờ vào các kỹ thuật hiện đại (subword tokenization, embeddings ngữ cảnh, mô hình Transformer hay học tương tác) vấn đề này dần được khắc phục. Trong tương lai, khi ngôn ngữ tiếp tục thay đổi và mở rộng, việc nghiên cứu và áp dụng các giải pháp xử lý OOV sẽ là yếu tố then chốt để xây dựng các hệ thống NLP thông minh, chính xác và gần gũi hơn với người dùng.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá