
Reinforcement Learning là gì? Khám phá các thuật toán trong học tăng cường

 14/03/2025
14/03/2025
Reinforcement Learning là một trong những lĩnh vực quan trọng trong trí tuệ nhân tạo, mang lại những bước tiến vượt bậc trong việc phát triển các hệ thống tự động hóa thông minh.
Reinforcement Learning là một trong những bước tiến quan trọng của trí tuệ nhân tạo hiện nay. Không cần dữ liệu gán nhãn hay lập trình cứng nhắc, học tăng cường cho phép hệ thống tự khám phá, thử nghiệm và tối ưu hóa quyết định theo thời gian. Từ đó mở ra những ứng dụng đột phá cho nhiều lĩnh vực như công nghệ, tài chính, tới y tế,... Dù vẫn còn những thách thức trong tính toán và triển khai thực tiễn, RL vẫn đang thu hút sự quan tâm mạnh mẽ từ giới công nghệ và các nhà đầu tư, trở thành một trong những nền tảng quan trọng thúc đẩy trí tuệ nhân tạo và tự động hóa. Vậy Reinforcement Learning là gì? Nguyên lý hoạt động và những ứng dụng thực tế của học tăng cường ra sao? Hãy cùng VNPT AI tìm hiểu kỹ hơn trong bài viết này.
Reinforcement learning là gì?
Học tăng cường (Reinforcement Learning) là một kỹ thuật của học máy (Machine Learning) giúp phần mềm tự động đưa ra quyết định nhằm tối ưu hóa kết quả. Phương pháp này mô phỏng cách con người học hỏi thông qua thử và sai để đạt được mục tiêu đã đề ra. RL hướng dẫn phần mềm ưu tiên những hành động có lợi cho mục tiêu, đồng thời hạn chế các hành động không cần thiết hoặc gây xao nhãng.

Cụ thể, các thuật toán RL hoạt động dựa trên cơ chế phần thưởng và hình phạt để đánh giá hành động. Hệ thống không ngừng thử nghiệm, tiếp nhận phản hồi và điều chỉnh chiến lược để tìm ra phương án tối ưu nhất nhằm đạt được mục tiêu. Một đặc điểm quan trọng của học tăng cường là khả năng trì hoãn phần thưởng, chấp nhận hy sinh lợi ích ngắn hạn để đạt kết quả tốt hơn trong tương lai. Nhờ đó, Reinforcement Learning giúp AI thích nghi và tối ưu hóa hiệu suất trong môi trường phức tạp, chưa biết trước. Vì vậy, nó được ứng dụng rộng rãi trong robot tự động, trò chơi điện tử, giao dịch tài chính, chuỗi cung ứng và nhiều hệ thống tự động khác.
Nguyên lý hoạt động của học tăng cường
Trước khi tìm hiểu về nguyên lý hoạt động của Reinforcement Learning là gì, bạn đọc cần nắm được các yếu tố chính trong học tăng cường bao gồm:
- Tác tử - Agent trong Reinforcement Learning là thuật toán hoặc hệ thống ra quyết định trong RL.
- Môi trường (Environment): Là bối cảnh mà tác tử hoạt động, bao gồm các quy tắc, giới hạn và các biến số.
- Hành động (Action): Là các bước mà tác tử có thể thực hiện để thay đổi trạng thái của môi trường.
- Trạng thái (State): Là điều kiện của môi trường tại một thời điểm nhất định.
- Phần thưởng (Reward): Là giá trị phản hồi (có thể dương, âm hoặc bằng không) mà tác tử nhận được sau mỗi hành động, phản ánh mức độ hiệu quả của hành động đó.
- Phần thưởng tích lũy (Cumulative Reward): Là tổng phần thưởng mà tác tử nhận được trong suốt quá trình hoạt động, giúp xác định chiến lược tối ưu.
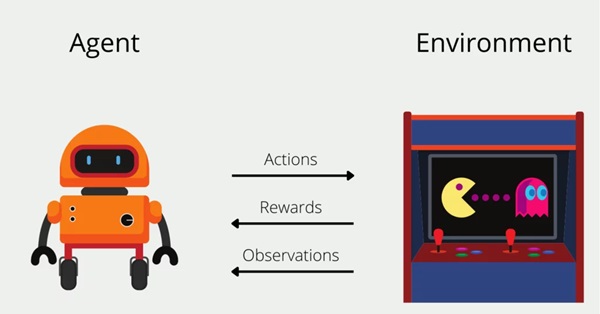
Về nguyên lý, Reinforcement Learning cơ bản sẽ hoạt động theo cách tương tự như cách con người và động vật học hỏi từ trải nghiệm thông qua thử và sai. Ví dụ, một đứa trẻ có thể nhận ra rằng khi chúng giúp đỡ người khác hoặc làm việc nhà, chúng sẽ nhận được lời khen, trong khi hành vi tiêu cực như la hét hoặc ném đồ chơi sẽ dẫn đến phản ứng tiêu cực. Dần dần, đứa trẻ học được cách hành động để nhận được kết quả mong muốn. Thuật toán RL cũng áp dụng cách tiếp cận này bằng cách thử nghiệm các hành động khác nhau trong một môi trường để khám phá những hành vi mang lại phần thưởng cao nhất.
Cụ thể về quy trình hoạt động: Reinforcement Learning được xây dựng dựa trên Quá trình quyết định Markov (Markov Decision Process - MDP), trong đó tác tử thực hiện các hành động tuần tự theo từng bước thời gian. Ở mỗi bước:
- Tác tử thực hiện một hành động dựa trên trạng thái hiện tại của môi trường.
- Môi trường phản hồi bằng cách cập nhật trạng thái mới và cung cấp phần thưởng tương ứng.
- Tác tử học hỏi từ phản hồi, điều chỉnh chính sách hành động để tối ưu hóa phần thưởng trong tương lai.
Trong quá trình này, tác tử phải đối mặt với một quyết định quan trọng:
- Khám phá (Exploration): Thử các hành động mới để hiểu rõ hơn về môi trường.
- Khai thác (Exploitation): Lựa chọn hành động đã biết mang lại phần thưởng cao nhất.
Sự cân bằng giữa khám phá và khai thác là yếu tố cốt lõi để Reinforcement Learning tìm ra chiến lược tối ưu. Khi tác tử đã học đủ, nó có thể áp dụng chính sách tốt nhất để đạt được phần thưởng tối đa trong môi trường cụ thể.
Phân biệt giữa Reinforcement Learning với các phương pháp học máy khác
Machine Learning có ba phương pháp học chính: Học có giám sát, Học không giám sát và Học tăng cường. Mỗi phương pháp có cách tiếp cận và ứng dụng riêng, phù hợp với từng loại bài toán khác nhau. Hãy để VNPT AI giúp bạn hiểu rõ hơn những điểm khác nhau giữa các phương pháp học máy khác và Reinforcement Learning là gì nhé.
Học có giám sát (Supervised Learning)
Phương pháp học này giống như việc học với một giáo viên. Mô hình được huấn luyện trên dữ liệu có nhãn, tức là mỗi đầu vào đều có một đầu ra tương ứng. Phương pháp này thường được sử dụng để giải quyết các bài toán phân loại (như phát hiện email spam) và hồi quy (như dự đoán giá nhà). Một số thuật toán phổ biến bao gồm Hồi quy tuyến tính, Hồi quy logistic, SVM, Cây quyết định và Mạng nơ-ron nhân tạo.
>>> Xem thêm: Supervised Learning là gì? Ứng dụng thực tiễn của học có giám sát
Học không giám sát (Unsupervised Learning)
Phương pháp học không giám sát lại không yêu cầu dữ liệu có nhãn. Thay vì dựa vào đầu ra cụ thể, mô hình tự tìm kiếm các mẫu, nhóm hoặc mối quan hệ trong dữ liệu. Phương pháp này thường được áp dụng trong các bài toán phân cụm (như phân loại khách hàng) và phân tích liên kết (như gợi ý sản phẩm). Một số thuật toán tiêu biểu là K-Means, Phân cụm phân cấp, PCA và Autoencoders.
Học tăng cường (Reinforcement Learning - RL)
Reinforcement Learning hoạt động dựa trên sự tương tác giữa một tác tử (agent) và môi trường. Thay vì học từ dữ liệu có nhãn, tác tử sẽ thực hiện hành động, nhận phản hồi dưới dạng phần thưởng hoặc hình phạt, và dần dần tối ưu hóa chiến lược để đạt được thành công lâu dài. RL thường được ứng dụng trong các bài toán yêu cầu ra quyết định liên tục như trò chơi điện tử, điều khiển robot và giao dịch tài chính. Một số thuật toán phổ biến bao gồm Q-learning, SARSA và Deep Q-Networks (DQN).
Phân loại Reinforcement Learning
Reinforcement Learning được chia thành hai nhóm chính: Học tăng cường có mô hình (Model-based RL) và Học tăng cường không có mô hình (Model-free RL). Vậy sự khác biệt giữa hai phương pháp Reinforcement Learning là gì? Câu trả lời nằm ở cách tác tử học hỏi và ra quyết định của từng phương pháp:
Học tăng cường dựa trên mô hình (Model-based RL)
Trong phương pháp này, tác tử xây dựng một mô hình nội bộ về môi trường, giúp nó dự đoán phần thưởng của từng hành động trước khi thực hiện. Thuật toán của tác tử cũng được thiết kế để tối đa hóa điểm thưởng. Model-based RL phù hợp với các môi trường tĩnh, nơi kết quả của mỗi hành động được xác định rõ ràng.
Ưu điểm:
- Không cần nhiều mẫu dữ liệu để học.
- Tiết kiệm thời gian do có thể dự đoán thay vì thử nghiệm thực tế.
- Cung cấp môi trường an toàn hơn để kiểm tra và khám phá.
Nhược điểm:
- Phụ thuộc vào độ chính xác của mô hình; nếu mô hình không tốt, hiệu suất sẽ bị ảnh hưởng.
- Độ phức tạp cao, đòi hỏi nhiều tài nguyên tính toán.
- Không phù hợp với môi trường liên tục thay đổi.
Học tăng cường không mô hình (Model-free RL)
Phương pháp này không tạo mô hình nội bộ mà thay vào đó học hỏi thông qua thử nghiệm và sai sót. Tác tử thực hiện nhiều hành động khác nhau để quan sát kết quả, từ đó xây dựng một chiến lược tối ưu (gọi là chính sách – policy) nhằm tối đa hóa phần thưởng. Model-free RL phù hợp với các môi trường phức tạp, không xác định hoặc thường xuyên thay đổi.
Ưu điểm:
- Không phụ thuộc vào độ chính xác của mô hình.
- Ít phức tạp về mặt tính toán hơn so với Model-Based RL.
- Phù hợp hơn với các tình huống thực tế, nơi môi trường có thể thay đổi và khó dự đoán.
Nhược điểm:
- Cần thử nghiệm nhiều hơn, dẫn đến tiêu tốn nhiều thời gian hơn.
- Có thể gặp rủi ro khi ứng dụng Reinforcement Learning trong thực tế do phải thực hiện các hành động trực tiếp mà không có dự đoán trước.
Các thuật toán chính trong Reinforcement Learning
Thuật toán Reinforcement Learning quy định cách tác tử (agent) học được các hành động phù hợp từ phần thưởng mà nó nhận được. Có nhiều thuật toán khác nhau được sử dụng trong Reinforcement Learning, mỗi loại phù hợp với từng đặc điểm môi trường và bài toán cụ thể. Trong dó, các thuật toán RL thường được chia thành hai nhóm chính: thuật toán dựa trên giá trị (Value-Based) và thuật toán dựa trên chính sách (Policy-Based).
Thuật toán dựa trên giá trị (Value-Based Algorithms)
Nhóm thuật toán này tập trung vào việc đánh giá giá trị của từng trạng thái trong môi trường. Giá trị này phản ánh phần thưởng kỳ vọng mà tác tử có thể nhận được khi bắt đầu từ trạng thái đó và thực hiện nhiệm vụ.
Q-Learning
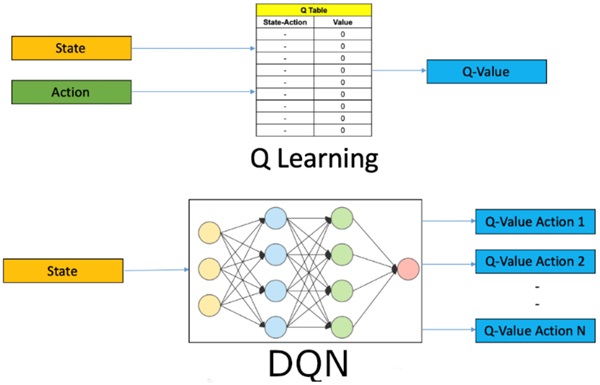
Q-Learning là một thuật toán Model-Free, Off-Policy, có nghĩa là nó không cần biết trước mô hình của môi trường và có thể học hỏi từ các hành động không tuân theo chính sách hiện tại. Thuật toán này sử dụng Q-table, trong đó mỗi ô lưu trữ giá trị Q tương ứng với một cặp trạng thái - hành động. Trong quá trình huấn luyện, giá trị Q được cập nhật dần dựa trên phản hồi từ môi trường. Khi thực thi, tác tử sẽ tra cứu Q-table để chọn hành động có giá trị cao nhất, từ đó tối ưu hóa phần thưởng nhận được trong hành trình tiếp theo.
Deep Q-Networks (DQN)
Deep Q-Networks (DQN) là một phiên bản nâng cao của Q-Learning, trong đó Q-table được thay thế bằng một mạng nơ-ron nhân tạo để ước lượng giá trị Q. Phương pháp này đặc biệt thích hợp cho các môi trường có không gian trạng thái lớn, nơi việc lưu trữ và cập nhật Q-table trở nên không khả thi. Nhờ sử dụng mạng nơ-ron, DQN giúp tác tử có khả năng tổng quát hóa, cho phép đưa ra quyết định tốt ngay cả với những trạng thái chưa từng gặp trước đó.
SARSA
SARSA (State-Action-Reward-State-Action) là một thuật toán On-Policy, có nghĩa là tác tử học theo chính sách hiện tại thay vì khám phá toàn bộ môi trường như Q-Learning. Thuật toán này cập nhật giá trị Q dựa trên hành động thực tế mà tác tử chọn theo chính sách đang được sử dụng. Nhờ đó, SARSA thường phù hợp với các bài toán yêu cầu hành vi an toàn và ổn định hơn so với Q-Learning, đặc biệt trong các môi trường có rủi ro cao.
Thuật toán dựa trên chính sách (Policy-Based Algorithms)
Thay vì học giá trị của từng trạng thái, nhóm thuật toán này tập trung trực tiếp vào việc tối ưu hóa chính sách (policy) – tức là quy tắc để tác tử chọn hành động trong từng trạng thái.
Các thuật toán này cập nhật trực tiếp chính sách để tối đa hóa phần thưởng. Một số thuật toán dựa trên policy gradient bao gồm: REINFORCE, Proximal Policy Optimization (PPO), Trust Region Policy Optimization (TRPO), Actor-Critic, Advantage Actor-Critic (A2C), Deep Deterministic Policy Gradient (DDPG), và Twin-Delayed DDPG (TD3).
Lợi ích của học tăng cường
Reinforcement learning có thể giải quyết nhiều bài toán phức tạp mà các thuật toán máy học truyền thống không làm được. Đặc biệt, RL được xem là một trong những công nghệ tiến bộ nhất sau trí tuệ nhân tạo tổng quát (AGI) vì nó có thể tự động tìm kiếm giải pháp tối ưu trong dài hạn mà không cần sự hướng dẫn chi tiết. Dưới đây là một số lợi ích quan trọng của RL:
- Tập trung vào mục tiêu tổng thể: Trong khi các thuật toán máy học truyền thống thường chia nhỏ vấn đề thành nhiều phần để giải quyết từng bước, Reinforcement learning học cách tối ưu hóa trực tiếp phần thưởng dài hạn. Điều này giúp hệ thống hiểu rõ mục tiêu cuối cùng và biết cách cân nhắc giữa lợi ích trước mắt và lợi ích lâu dài.
- Tự thu thập dữ liệu trong quá trình học: Thay vì cần một bộ dữ liệu huấn luyện có sẵn, Reinforcement learning tự thu thập dữ liệu thông qua tương tác với môi trường. Điều này giúp giảm đáng kể công sức chuẩn bị dữ liệu và cho phép hệ thống học tập một cách linh hoạt hơn.
- Thích nghi với môi trường thay đổi: RL có khả năng tự điều chỉnh khi môi trường thay đổi, không giống như các thuật toán truyền thống chỉ hoạt động tốt trên dữ liệu cố định. Nhờ khả năng học từ kinh nghiệm theo thời gian, RL có thể ứng phó tốt hơn với các tình huống không chắc chắn và môi trường động.
Ứng dụng của Reinforcement Learning trong thực tế
Hiện nay, Reinforcement Learning đang dần thay đổi cách người dùng giải quyết những bài toán phức tạp trong thế giới thực. Nhờ khả năng học hỏi từ trải nghiệm và tối ưu hóa quyết định trong các môi trường linh hoạt, học tăng cường được tin dùng trong nhiều ngành công nghiệp yêu cầu độ chính xác cao, từ robot, y tế, tài chính đến năng lượng và trò chơi. Vậy những ứng dụng phổ biến nhất của Reinforcement learning là gì? Cùng VNPT AI tìm hiểu chi tiết:
Robot và xe tự hành
- Điều khiển robot: RL giúp robot học cách cầm nắm, di chuyển và lắp ráp sản phẩm trong nhà máy, tăng khả năng thích ứng với môi trường mới. Ví dụ: Cánh tay robot của DeepMind được huấn luyện bằng RL để thực hiện các nhiệm vụ sắp xếp vật thể.
- Xe tự hành: RL giúp xe tự hành học cách di chuyển an toàn trong môi trường phức tạp, tối ưu hóa lộ trình và tiết kiệm nhiên liệu.

Y tế và Dược phẩm
- Lập kế hoạch điều trị: Reinforcement Learning hỗ trợ tối ưu hóa phác đồ điều trị cho bệnh nhân, đặc biệt trong điều trị ung thư và bệnh mãn tính.
- Phát triển thuốc mới: RL giúp tìm ra các phân tử thuốc tiềm năng bằng cách mô phỏng phản ứng hóa học, tăng tốc quá trình phát triển dược phẩm.
Tài chính và Đầu tư
- Giao dịch tự động: Học tăng cường hỗ trợ xây dựng thuật toán giao dịch thông minh, thích ứng nhanh với biến động thị trường. Ví dụ: LOXM của J.P. Morgan sử dụng RL để tối ưu hóa giao dịch tài chính.
- Quản lý danh mục đầu tư: Reinforcement Learning giúp cân bằng giữa lợi nhuận và rủi ro bằng cách tự động điều chỉnh chiến lược đầu tư theo thời gian thực.
Sản xuất và Bảo trì
- Tối ưu hóa dây chuyền sản xuất: RL giúp điều chỉnh thông số sản xuất để tăng hiệu suất và giảm lãng phí.
- Bảo trì dự đoán: Hệ thống học tăng cường phân tích dữ liệu máy móc để dự đoán lỗi và lên lịch bảo trì kịp thời, giảm chi phí sửa chữa.
Năng lượng và Lưới điện thông minh
- Quản lý lưới điện: RL giúp cân bằng cung - cầu điện năng, tối ưu hóa sử dụng năng lượng tái tạo. Ví dụ: DeepMind đã giảm 40% tiêu thụ năng lượng tại trung tâm dữ liệu Google.
- Tối ưu lịch trình sạc xe điện: Học tăng cường tính toán thời điểm sạc tối ưu để tiết kiệm chi phí và giảm áp lực lên lưới điện.
Trò chơi và Mô phỏng thực tế ảo
- Phát triển AI trong game: RL giúp AI học cách chơi game chiến lược, như AlphaGo của DeepMind đã đánh bại nhà vô địch cờ vây thế giới.
- Ứng dụng trong thực tế ảo: Reinforcement Learning tạo ra các mô phỏng chân thực hơn, hỗ trợ huấn luyện AI và nghiên cứu hành vi con người.

Thách thức và hạn chế của Reinforcement Learning
Dù đã đạt được những thành công ấn tượng và được ứng dụng rộng rãi trong các môi trường mô phỏng, việc ứng dụng học tăng cường vào thực tế vẫn còn nhiều rào cản. Hãy cùng VNPT AI tìm hiểu những thách thức chính của học tăng cường là gì mà khiến kỹ thuật này chưa được áp dụng rộng rãi trong thế giới thực:
- Cần lượng dữ liệu huấn luyện lớn: Học tăng cường tự động tạo dữ liệu bằng cách tương tác với môi trường, nhưng tốc độ thu thập dữ liệu bị giới hạn bởi động lực học của môi trường. Trong các hệ thống có độ trễ cao hoặc không gian trạng thái lớn, tác tử RL cần khám phá rất nhiều trước khi tìm ra chiến lược tối ưu, làm quá trình học trở nên chậm và tốn kém.
- Phần thưởng bị trì hoãn: Reinforcement Learning dựa vào phần thưởng để học, nhưng trong nhiều bài toán thực tế, phần thưởng không xuất hiện ngay lập tức mà chỉ được xác định sau một chuỗi hành động dài. Điều này gây khó khăn trong việc xác định hành động nào đã góp phần tạo nên kết quả cuối cùng, khiến việc tìm ra chính sách tối ưu trở nên phức tạp. Ví dụ, trong trò chơi cờ vua, chỉ khi ván đấu kết thúc người chơi mới biết được chiến lược của mình có hiệu quả hay không.
- Thiếu khả năng giải thích: Sau khi một tác tử học tăng cường học được chính sách tối ưu và bắt đầu thực thi, lý do đằng sau các quyết định của nó thường không rõ ràng. Điều này làm giảm mức độ tin tưởng của con người vào hệ thống, đặc biệt trong những lĩnh vực có rủi ro cao như y tế hoặc tài chính. Nếu có thể giải thích được cách RL đưa ra quyết định, chúng ta không chỉ hiểu rõ hơn về bài toán mà còn phát hiện ra những điểm yếu trong mô hình.
Tương lai của Reinforcement Learning
Một trong những xu hướng Reinforcement Learning nổi bật nhất hiện nay là Học tăng cường sâu (Deep Reinforcement Learning - DRL), công nghệ đang tạo ra bước đột phá nhờ kết hợp RL với mạng nơ-ron sâu. Trước đây, học tăng cường yêu cầu thiết kế đặc trưng thủ công, con người phải chọn lọc và cung cấp những đặc trưng đầu vào để mô hình học tập. Nhưng với deep learning, mô hình có thể tự động trích xuất đặc trưng quan trọng từ dữ liệu thô, giúp tác tử học chính sách tối ưu trong môi trường phức tạp.
Ngoài ra, Reinforcement Learning cơ bản mắc phải một hạn chế đó là mỗi tác tử chỉ học một nhiệm vụ riêng lẻ. Tuy nhiên, mô hình A3C (Asynchronous Advantage Actor-Critic) đã khắc phục điều này bằng cách cho phép nhiều tác tử học song song và chia sẻ kinh nghiệm, giúp quá trình học nhanh hơn. Những tiến bộ này đang đưa RL tiến gần hơn đến trí tuệ nhân tạo tổng quát (AGI), nơi các hệ thống không chỉ học giải quyết một bài toán mà còn có khả năng học cách học, mở ra tiềm năng tự động hóa mạnh mẽ hơn.
Tạm kết
Reinforcement Learning đang chứng minh tiềm năng lớn trong nhiều lĩnh vực, từ robot, chăm sóc sức khỏe đến tài chính và năng lượng. Dù vẫn đối mặt với thách thức như yêu cầu dữ liệu lớn, phần thưởng trễ và khó diễn giải, nhưng học tăng cường đang tiến gần hơn đến trí tuệ nhân tạo tổng quát (AGI), mở ra nhiều cơ hội đột phá và ứng dụng thực tiễn trong tương lai. Hy vọng rằng bài viết này của VNPT AI đã cung cấp cho bạn đọc những thông tin đầy đủ nhất về kỹ thuật Reinforcement Learning là gì và tầm quan trọng của công nghệ này trong đời sống.
Tác giả: Nguyễn Minh Hải
Tin mới nhất

29/12/2025

29/12/2025

18/12/2025

17/12/2025

16/12/2025
16/12/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan
.jpg)

