
Ứng dụng DeepStream trong hệ thống phân tích, tóm tắt video thông minh

 23/09/2025
23/09/2025
Theo thống kê của Tổng cục Hải quan, đến năm 2025 cả nước sẽ có hơn 20 triệu camera giám sát được đưa vào sử dụng, tương đương gần 500 triệu giờ video được tạo ra mỗi ngày. Để khai thác kho dữ liệu khổng lồ này, VNPT AI đã ứng dụng thành công DeepStream vào hệ thống phân tích video thế hệ mới.
Lượng dữ liệu khổng lồ này đặt ra bài toán lớn về khai thác tri thức từ video. Việc chỉ dừng lại ở quan sát thụ động không còn đủ, mà các hệ thống hiện đại cần có khả năng tìm kiếm, tóm tắt và suy luận theo ngữ cảnh, nhằm biến video từ dữ liệu thô thành nguồn thông tin phục vụ ra quyết định.
Tuy nhiên, phần lớn các nền tảng xử lý video tại Việt Nam hiện vẫn phát triển theo hướng rời rạc, mỗi sản phẩm chỉ giải quyết một khâu riêng biệt như nhận diện hình ảnh, phân tích âm thanh hay trích xuất nội dung. Điều này khiến việc tích hợp và vận hành tổng thể gặp nhiều hạn chế, đặc biệt trong bối cảnh nhu cầu phân tích dữ liệu đa mô thức (Multimodal data processing) ngày càng gia tăng.
Từ thực tế đó, đội ngũ kỹ sư VNPT AI đã xây dựng một nền tảng tổng hợp “all-in-one” (tất cả trong một) - VNPT SmartVision Generative Agent (SVGA) - dựa trên nền tảng DeepStream và các mô hình ngôn ngữ. Cách tiếp cận này hình thành nên Video Search & Summarization (VSS) - hệ thống có thể hiểu cảnh, giọng nói, tài liệu, đồng thời có khả năng tóm tắt, hỗ trợ tìm kiếm hỏi đáp theo ngữ cảnh trên một trải nghiệm ngôn ngữ thống nhất, mở ra hướng ứng dụng có giá trị trong nhiều lĩnh vực. Những kết quả kỹ thuật này đã được chúng tôi công bố tại NVIDIA AI Days 2025 vào tháng 9/2025.

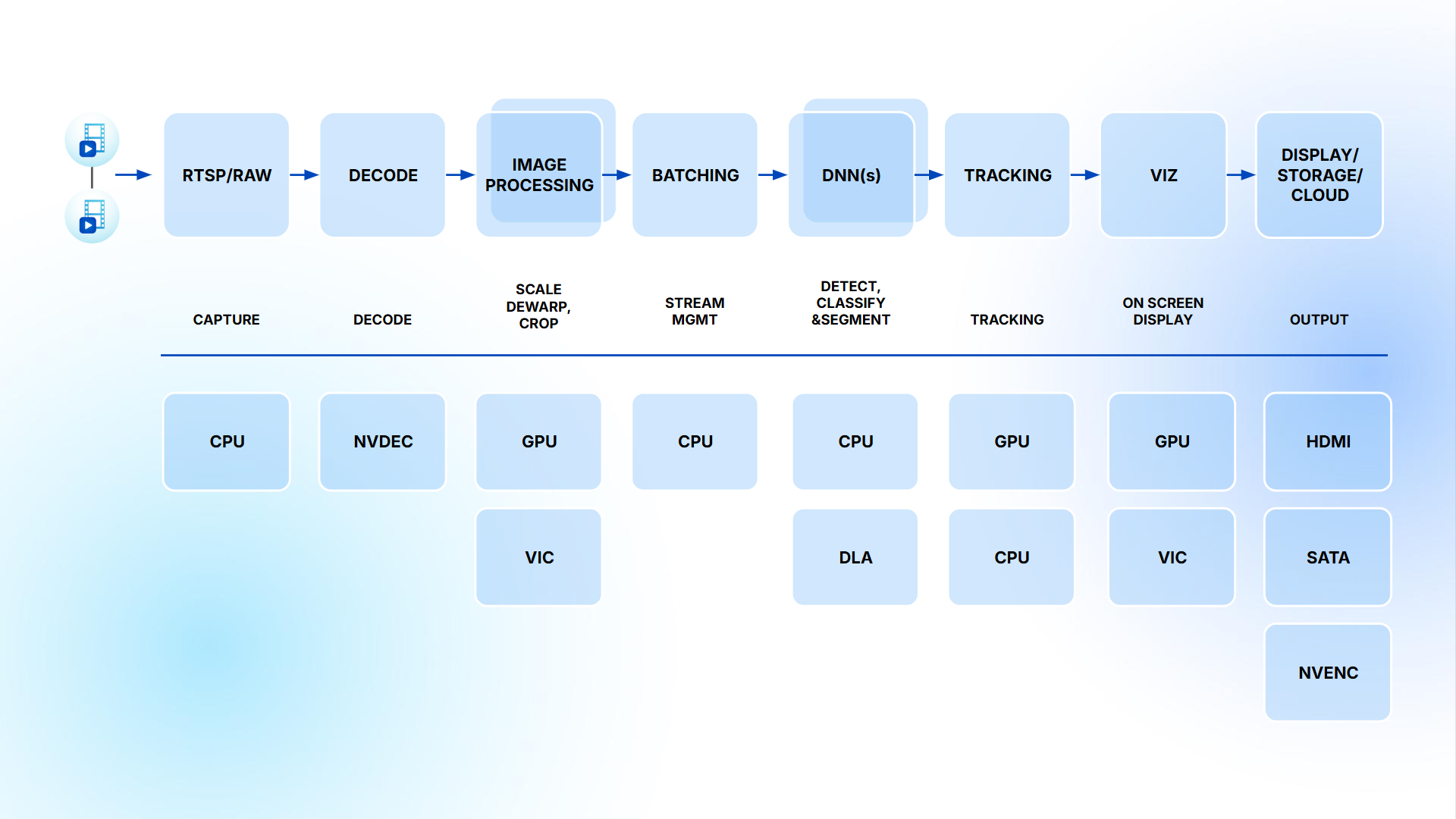
Hạ tầng kỹ thuật: DeepStream
Chúng tôi lựa chọn DeepStream Framework, cho phép xử lý song song nhiều luồng video - audio với GPU tăng tốc. Hệ thống hỗ trợ decode, batching, inference qua TensorRT/Triton và đồng bộ metadata (ID, thời gian, bounding box) cho phân tích hạ nguồn.
Đặc biệt, DeepStream cho phép xử lý end-to-end (từ nhận luồng camera, giải mã hình ảnh, phát hiện đối tượng, đến hiển thị và lưu trữ đám mây) giúp giảm đáng kể độ trễ, nâng cao tính ổn định và hiệu năng trong các ứng dụng quy mô lớn như giám sát đô thị hay giao thông thông minh.
Video Search & Summarization (VSS)
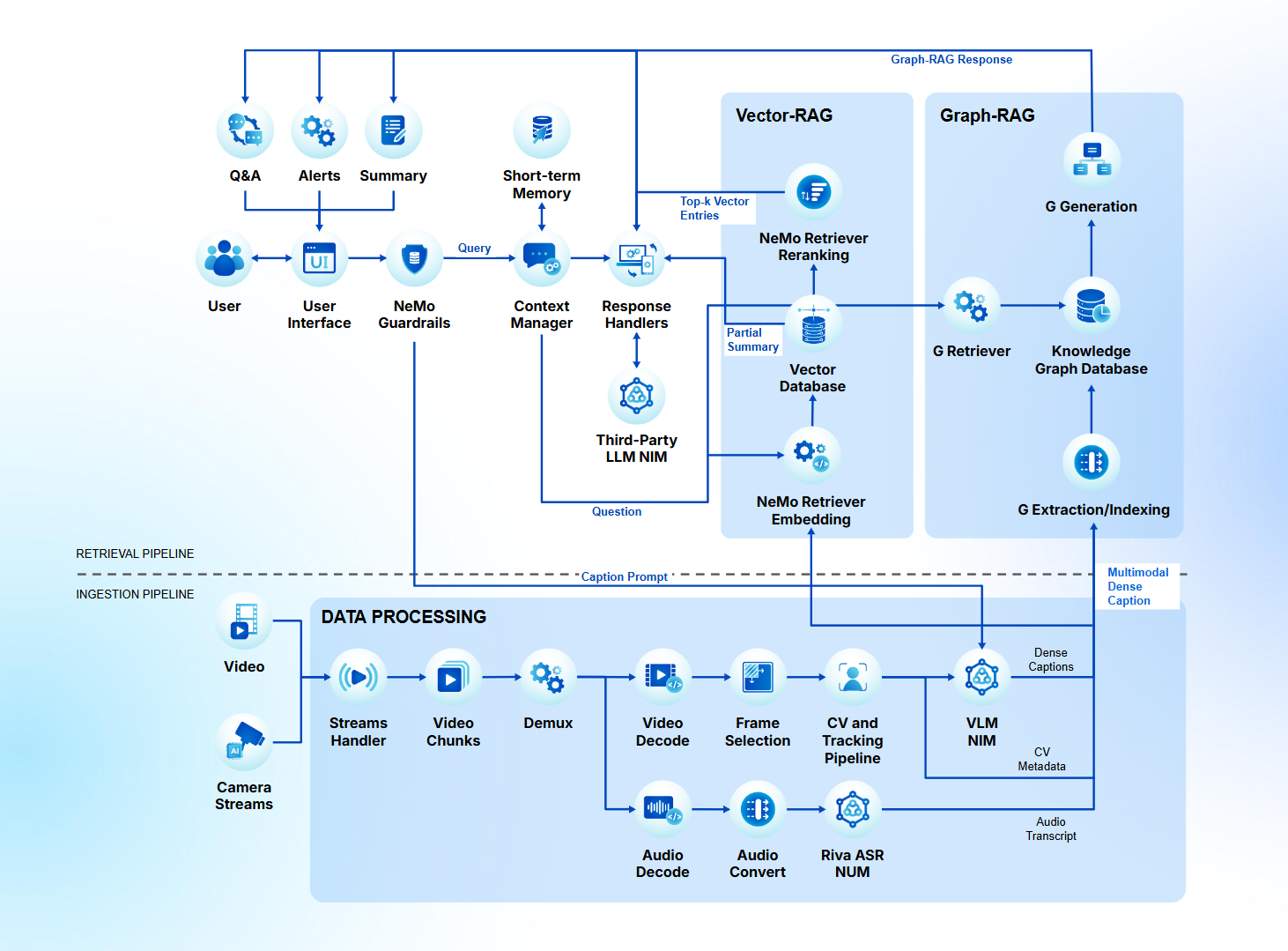
VSS là thành phần quan trọng trong SVGA, được thiết kế để xử lý và khai thác dữ liệu video theo hai giai đoạn: ingestion pipeline và retrieval pipeline. Ingestion pipeline tích hợp:
- Deepstream để chuẩn hóa video pipeline và bóc tách, trích xuất thông tin từ ảnh (frame), tiếng nói (audio) từ video/ camera streaming.
- Riva ASR để chuyển đổi âm thanh thành văn bản.
- VLM (Vision-Language Model) tạo caption giàu ngữ nghĩa với prompt điều hướng.
- Chuẩn hóa và lập chỉ mục qua Vector DB và Graph DB.
Trong retrieval pipeline, Vector-RAG hỗ trợ tìm kiếm ngữ nghĩa, còn Graph-RAG cho phép suy luận theo chuỗi sự kiện và quan hệ. Sự kết hợp này giúp giảm ảo giác, nâng cao độ chính xác và tạo câu trả lời gắn với ngữ cảnh.
Ở quy trình Tóm tắt & Truy xuất thông tin, VSS kết hợp retriever embedding, Vector DB và Graph DB trong một workflow thống nhất. Mô hình LLM gọi công cụ (tool-calling) để truy xuất dữ liệu, sau đó sử dụng kết quả được rerank (xếp hạng lại) làm ngữ cảnh tóm tắt hoặc trả lời câu hỏi.
Cơ chế này cho phép VSS thực hiện hai chức năng đồng thời:
- Summarization: tổng hợp nội dung video dài hoặc luồng trực tiếp thành bản tóm tắt ngắn, súc tích và có ngữ cảnh.
- Q&A: trả lời truy vấn tự nhiên của người dùng dựa trên dữ liệu thực, giúp đảm bảo tính chính xác và giảm ảo giác mô hình.
Để đảm bảo đầu ra an toàn và ổn định, VSS tích hợp nhiều cơ chế điều phối và kiểm soát:
- Prompt Engine: chuẩn hóa và chèn hướng dẫn định dạng, quy tắc an toàn trước khi gửi yêu cầu đến LLM.
- NeMo Guardrails: kiểm soát phản hồi, loại bỏ nội dung không phù hợp, bảo đảm tuân thủ quy tắc miền ứng dụng.
- Context Manager & Short-Term Memory: lưu trữ ngữ cảnh hội thoại và các lần truy vấn trước, giúp hệ thống duy trì mạch trao đổi tự nhiên, tránh lặp lại hoặc mâu thuẫn.
Nhờ sự kết hợp này, VSS trở thành một nền tảng phân tích video có khả năng tóm tắt, hỏi đáp, và phản hồi liên tục trong thời gian thực.
Ứng dụng thực tiễn của SVGA
Thành quả nghiên cứu của chúng tôi đã được triển khai trong nhiều kịch bản, giải quyết các bài toán thực tế:
- Giao thông: nhận diện vi phạm, phân tích mật độ, hỗ trợ phạt nguội với bằng chứng video; tổng hợp và tóm tắt sự kiện theo khu vực để báo cáo nhanh.
- An ninh: theo dõi đối tượng/phương tiện bằng nhận diện khuôn mặt và biển số; giám sát nguy cơ cháy nổ, gửi cảnh báo thời gian thực; phân loại và tóm tắt vi phạm để hỗ trợ điều tra.
- Công nghiệp: giám sát PPE, phát hiện hành vi nguy hiểm, cảnh báo tai nạn; tự động phân tích ca làm và sinh báo cáo cuối ca.
- Kiểm duyệt nội dung: phát hiện nhanh nội dung vi phạm (18+, bạo lực, bản đồ trái phép...); nhận diện gương mặt trong danh sách hạn chế; tóm tắt và làm nổi bật các đoạn video chứa vi phạm.
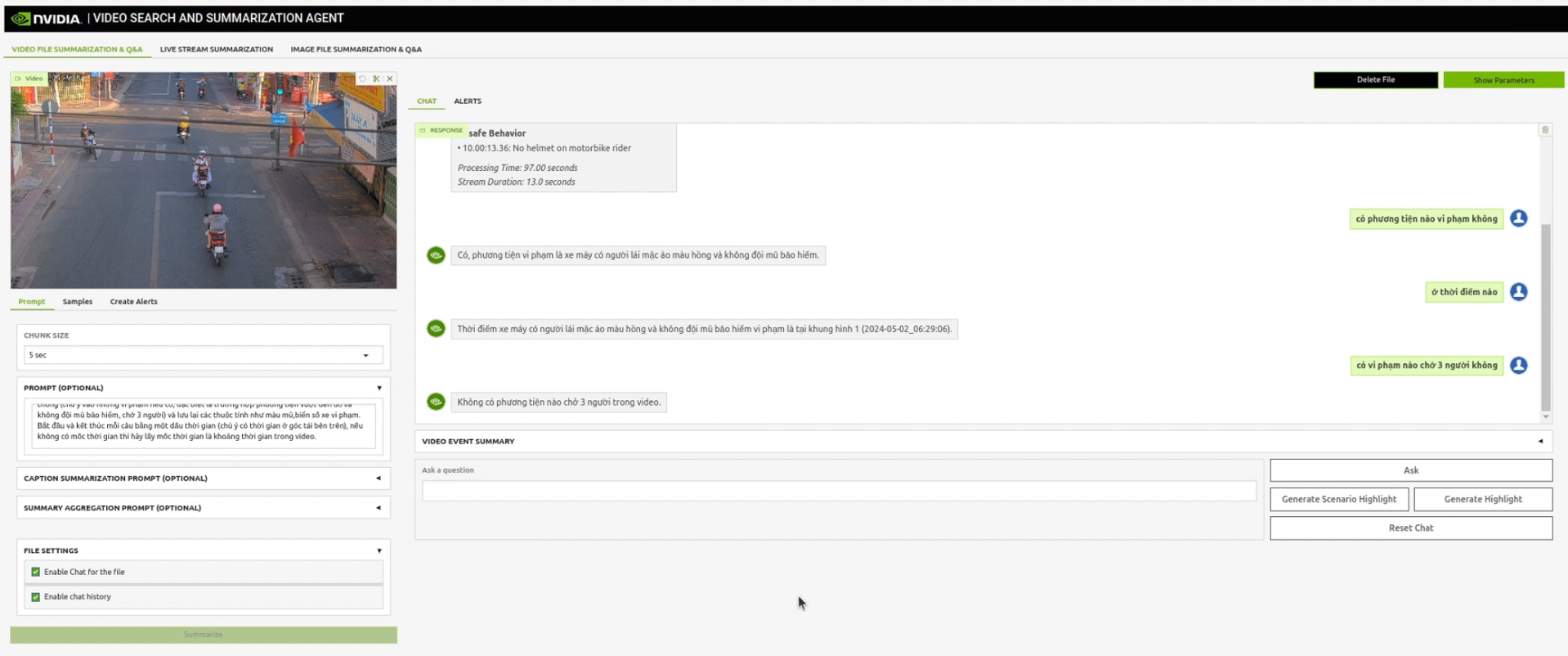
Kết quả và ý nghĩa
SVGA không chỉ nhìn và nhận diện, mà còn hiểu, tóm tắt và phản hồi bằng ngôn ngữ tự nhiên. Video được chuyển hóa từ dữ liệu thụ động thành nguồn tri thức tương tác, hỗ trợ ra quyết định nhanh chóng trong nhiều bối cảnh. Đặc biệt, VSS được thiết kế để xử lý linh hoạt cả dữ liệu video lưu trữ (offline) và luồng video trực tuyến (online streaming), giúp hệ thống vận hành hiệu quả trong các môi trường khác nhau, từ phân tích dữ liệu quá khứ đến giám sát thời gian thực.
Từ giao thông, an ninh, cho đến công nghiệp và nội dung số, SVGA đang đặt nền móng cho hạ tầng phân tích video thế hệ mới - một hạ tầng vừa mang tính học thuật, vừa mang giá trị ứng dụng thực tiễn trong lĩnh vực giám sát thông minh.
Tác giả: Dương Việt Hùng
Từ khóa:
VNPTAI
NVIDIAAIDay
VNPTSmartVision
ImageProcessing
Tin mới nhất
16/10/2025
14/10/2025
12/10/2025
10/10/2025
07/10/2025
27/09/2025

VNPT AI
Hãy trở thành đối tác của chúng tôi ngay hôm nay để được sử dụng những dịch vụ hàng đầu!
Gửi lời nhắnĐánh Giá
Các bài viết liên quan

